皆さん,こんにちは!機械学習エンジニアの柏木(@asteriam )です.
今回は前回のエントリーに続いてその後編になります.
tech.connehito.com
はじめに
後編は前編でも紹介した通り以下の内容になります.
後編:SageMakerのリソースを用いてモデルのデプロイ(サービングシステムの構築)をStep Functionsのフローに組み込んだ話
モデル学習後の一連の流れで,推論を行うためにモデルのデプロイやエンドポイントの作成をStep Functionsで実装した内容になります.
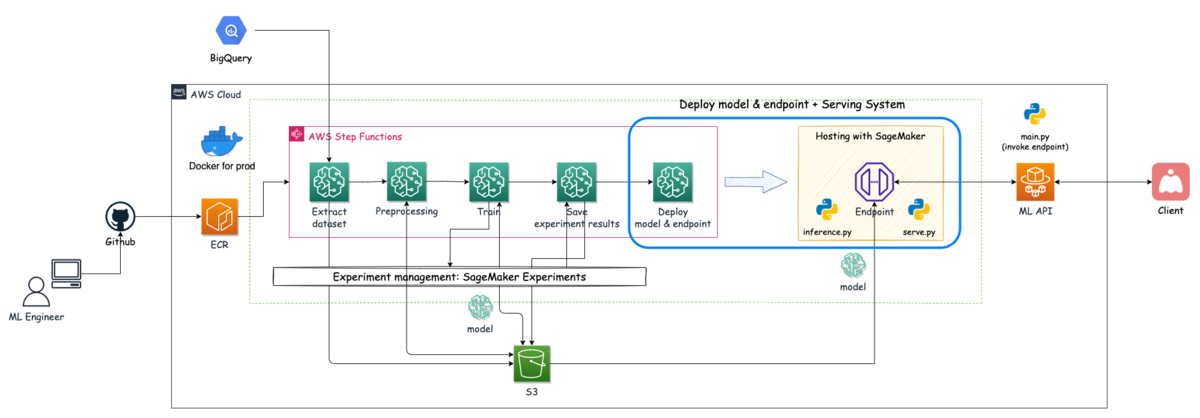
今回紹介するのは下図の青枠箇所の内容になります.
検閲システムのアーキテクチャー概略図
目次
Step Functionsを使ってサービングシステムを構築する方法
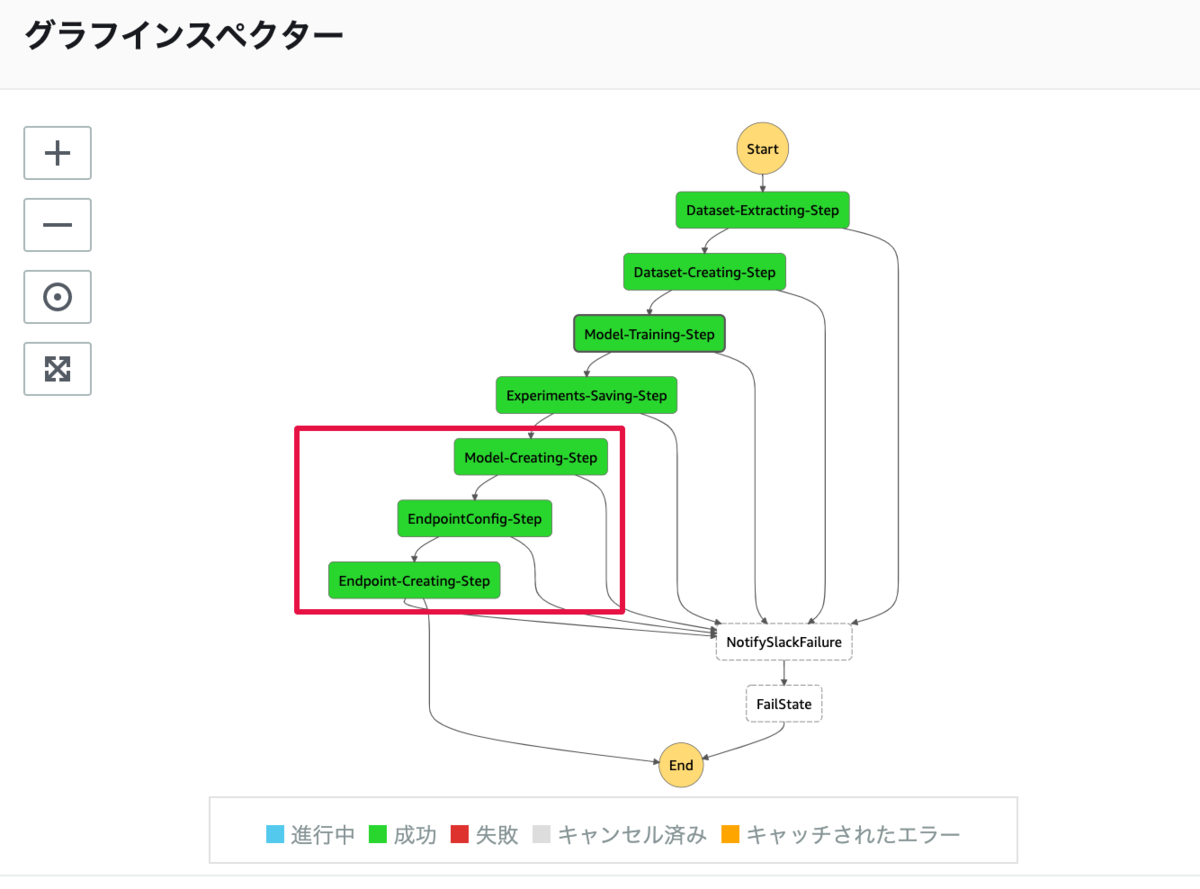
Step Functionsのグラフインスペクターに示された処理のうち赤枠部分が今回の処理になります.
No.
ステップ名
SageMakerのアクション
処理内容
5
Model-Creating-Step
CreateModel
推論コンテナの設定とモデルの作成
6
EndpointConfig-Step
CreateEndpointConfig
エンドポイントの設定
7
Endpoint-Creating-Step
CreateEndpoint
エンドポイントの作成とモデルのデプロイ
Step Functionsのグラフインスペクター
サービングシステムを構築するために,3つの処理をStep Functionsに組み込んでいます.
モデルの作成と推論コンテナの設定
エンドポイントの構成を設定
エンドポイントの作成とモデルのデプロイ
また,サービングシステム・ML API・Clientの関係性を説明するために,システム全体から該当箇所を切り取った図を下に載せています.
サービングシステム
それぞれの役割を説明すると
Client⇄ML API
ClientはML APIに対して,推論を行うために必要なデータをPOSTする
ML APIは正常投稿 or 違反投稿どちらかを表すフラグ値(0 or 1)をClientに返却する
ML API⇄推論エンドポイント(サービングシステム)
ML APIは検閲する生のテキストを情報として詰め込んで推論エンドポイントをinvokeする
import json
import boto3
client = boto3.client("sagemaker-runtime" )
input_text = {"text" : "推論対象のデータ" }
response = client.invoke_endpoint(
EndpointName='エンドポイント名' ,
Body=json.dumps(input_text),
ContentType='application/json' ,
Accept='application/json'
)
result_body = json.load(response['Body' ])
pred = float (result_body['predictions' ])
print (pred)
サービングシステムはテキストの前処理を行った後に学習済みモデルによる推論を行い,違反確率をML APIに返却する
サービングシステムはS3に保存されているモデルアーティファクトをロードしてデータを待ち受けている
それでは,サービングシステムを構築する部分を紹介していきます.
学習済みモデルを含んだ推論コンテナの設定(モデルの作成)
この処理ステップでは,「モデルの作成」を行います.この処理を行う上で用意するコードは以下になります.
今回も公式のサンプルコードを参考にしたので,確認してみて下さい.amazon-sagemaker-examples/advanced_functionality/scikit_bring_your_own
用意するコード
Dockerfile.cpu(今回はgpu版のDockerfileも使用しているため.cpuを付けて区別しています)
推論エンドポイントとしてデプロイするコンテナ
ファイル内でserve.pyの実行権限を与えておく必要があります
serve.py
NginxとGunicornを起動するPythonスクリプトで,コンテナ起動時に実行されるスクリプト
実行されるコマンド: docker run <イメージ> serve
公式のサンプルをそのまま流用
inference.py
Flaskアプリで,独自の処理を書くことができ,リクエストに応じて機械学習モデルの読み込みや推論処理を行う
今回は生データを受け取り,シーケンスに変換し推論を行う
ヘルスチェック時にモデルのロードを行う
"""推論を行うflaskサーバー
生のテキストデータを受け取り,モデルに入力できる形式に変換する
BERTモデルに変換したデータを入力することで推論を行う
"""
import json
import os
import sys
import traceback
from typing import List, Tuple
import numpy as np
from flask import Flask, Response, jsonify, make_response, request
import tensorflow as tf
from transformers import AutoTokenizer, TFBertModel
MAX_LENGTH = 512
MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking'
SAVED_MODEL_NAME = 'bert_model.h5'
prefix = "/opt/ml/"
model_path = os.path.join(prefix, "model" )
tokenizer_bert = AutoTokenizer.from_pretrained(MODEL_NAME)
def text2features (texts: List[str ], max_length: int ) -> List[Tuple[np.ndarray, np.ndarray, np.ndarray]]:
"""テキストのリストをTransformers用の入力データに変換
input_ids, attention_mask, token_type_idsの説明はglossaryに記載されている
cf. https://huggingface.co/transformers/glossary.html
Args:
texts (List[str]): 分類対象のテキストデータが入ったリスト
max_length (int): 入力として使用されるシーケンスの最大長
Returns:
List[Tuple[np.ndarray, np.ndarray, np.ndarray]]: input_ids, attention_mask, token_type_idsが入ったリスト
"""
shape = (len (texts), max_length)
input_ids = np.zeros(shape, dtype="int32" )
attention_mask = np.zeros(shape, dtype="int32" )
token_type_ids = np.zeros(shape, dtype="int32" )
for i, text in enumerate (texts):
encoded_dict = tokenizer_bert.encode_plus(text, max_length=max_length, pad_to_max_length=True )
input_ids[i] = encoded_dict["input_ids" ]
attention_mask[i] = encoded_dict["attention_mask" ]
token_type_ids[i] = encoded_dict["token_type_ids" ]
return [input_ids, attention_mask, token_type_ids]
class ScoringService (object ):
"""モデルのロードと受け取ったデータから推論を行う
"""
model = None
@ classmethod
def get_model (cls):
"""事前にロードできていない場合はモデルをロードする
"""
if cls.model is None :
cls.model = tf.keras.models.load_model(os.path.join(model_path, SAVED_MODEL_NAME), compile =True )
return cls.model
@ classmethod
def predict (cls, input : List[Tuple[np.ndarray, np.ndarray, np.ndarray]]) -> float :
"""入力データに対して,推論を行う
Args:
input (List): 推論対象のデータで,リストの要素に対して推論を行う
"""
loaded_model = cls.get_model()
return loaded_model.predict(input )
app = Flask(__name__)
@ app.route ("/ping" , methods=["GET" ])
def ping ():
"""コンテナの動作とヘルスチェックを行う,モデルのロードが成功すればヘルス判定される
"""
health = ScoringService.get_model() is not None
status = 200 if health else 404
return Response(response="" , status=status, mimetype="application/json" )
@ app.route ("/invocations" , methods=["POST" ])
def inference ():
"""
毎分毎にデータが送られてきて,リアルタイムで推論を行う.
テキストデータを受け取り,モデルが受け入れられる形式に変換を行い,予測確率(0.0~1.0)を返す.
"""
data = request.get_data().decode("utf8" )
data = json.loads(data)
text = text2features([data['text' ]], MAX_LENGTH)
predictions = ScoringService.predict(text)
return make_response(jsonify(predictions=str (predictions[0 ][0 ])), 200 )
nginx.conf
Nginxの設定ファイル
8080番ポートで /pingもしくは /invocationsにアクセスがあった場合に,Gunicornに転送する
公式のサンプルをそのまま流用
wsgi.py
Gunicornの設定ファイル
推論コード(inference.py)をimportする
用意するコードからわかるように,サービングシステムの実態はWeb ServerにNginx,Application ServerにGunicornを使いフレームワークとしてFlaskを利用しています.
CreateModelで主に設定する内容
モデルに名前を付ける
推論コンテナの設定
推論コード
サーブファイル
アーティファクト(=モデル)のパス設定
イメージ
"Model-Creating-Step ": {
"Type ": "Task ",
"Resource ": "arn:aws:states:::sagemaker:createModel ",
"Parameters ": {
"PrimaryContainer ": {
"ContainerHostname.$ ": "States.Format('{}-{}', 'prod-sample-con', $$.Execution.Name) ",
"Environment ": {
"PYTHON_ENV ": "prod "
} ,
"Image ": "<アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/sample:latest-cpu ",
"Mode ": "SingleModel ",
"ModelDataUrl.$ ": "$.ModelArtifacts.S3ModelArtifacts "
} ,
"ExecutionRoleArn ": "arn:aws:iam::<アカウントID>:role/StepFunctions_SageMakerAPIExecutionRole ",
"ModelName.$ ": "States.Format('{}-{}', 'prod-sample-m', $$.Execution.Name) "
} ,
"Catch ": [
{
"ErrorEquals ": [
"States.ALL "
] ,
"Next ": "NotifySlackFailure "
}
] ,
"ResultPath ": null ,
"Next ": "EndpointConfig-Step "
}
ModelDataUrl: TrainingJobの出力結果から参照しており,モデルが保存されているS3のパスを指定します.ここで指定したパスが’/opt/ml/model’に同期されるので,推論コードで呼び出してモデルをロードすることができます.ExecutionRoleArn: ロールにアタッチするポリシーはSageMaker Roles を参考にしてみて下さい.ここで嵌ってしまったのですが,Actionに"iam:PassRole"が必要になるので注意です.
エンドポイントの構成を設定
この処理ステップでは,モデルをデプロイするために使用する「エンドポイントの構成を作成」を行います.
CreateEndpointConfigで主に設定する内容
デプロイするモデルの指定(CreateModel時に付けたモデルの名称)
プロビジョニング用のリソース
エンドポイント構成の名前
"EndpointConfig-Step ": {
"Type ": "Task ",
"Resource ": "arn:aws:states:::sagemaker:createEndpointConfig ",
"Parameters ": {
"EndpointConfigName.$ ": "States.Format('{}-{}', 'prod-sample-ec', $$.Execution.Name) ",
"ProductionVariants ": [
{
"InstanceType ": "ml.t2.large ",
"InitialInstanceCount ": 1 ,
"ModelName.$ ": "States.Format('{}-{}', 'prod-sample-m', $$.Execution.Name) ",
"VariantName.$ ": "States.Format('{}-{}', 'prod-sample-v', $$.Execution.Name) "
}
]
} ,
"Catch ": [
{
"ErrorEquals ": [
"States.ALL "
] ,
"Next ": "NotifySlackFailure "
}
] ,
"ResultPath ": null ,
"Next ": "Endpoint-Creating-Step "
}
InstanceType: 推論サーバーのマシンスペック(インスタンスタイプ)をここで決めます.今回は最低スペックのml.t2.mediumだとメモリ不足になったので,メモリ8GBのマシンを選択しました.この辺りは常時稼働しているので費用面と相談しながらスペックを決める必要があると思います.
エンドポイントの作成とデプロイ
この処理ステップでは,エンドポイント設定を用いて「エンドポイントの作成」を行います.ここで最終的に設定されたリソースを起動し,モデルをその上にデプロイします.
CreateEndpointで主に設定する内容
デプロイするモデルの指定(CreateModel時に付けたモデルの名称)
使用するエンドポイント構成の指定(CreateEndpointConfig時に付けたエンドポイント構成の名称)
エンドポイントの名前
"Endpoint-Creating-Step ": {
"Type ": "Task ",
"Resource ": "arn:aws:states:::sagemaker:createEndpoint ",
"Parameters ": {
"EndpointConfigName.$ ": "States.Format('{}-{}', 'prod-sample-ec', $$.Execution.Name) ",
"EndpointName.$ ": "States.Format('{}-{}', 'prod-sample-e', $$.Execution.Name) "
} ,
"Catch ": [
{
"ErrorEquals ": [
"States.ALL "
] ,
"Next ": "NotifySlackFailure "
}
] ,
"End ": true
}
処理が正常に完了するとSageMakerのコンソール上でエンドポイントを選択すると,指定したエンドポイント名のステータスが「InService」になっていることを確認できます.
SageMakerのコンソール画面 - エンドポイント
また,エンドポイントを誤って削除したり,想定とは違う状態だった場合にロールバックが必要になることがありますが,これはモデルとエンドポイント設定が残っていればいつでも復元可能です.エンドポイントの作成は手動でもできるのでSageMakerのコンソールから設定すると良いと思います.
機械学習システムを開発して
今回新しく検閲システムを開発し,その中でデータ抽出からモデルの学習,そしてモデルのデプロイまで一気通貫した機械学習パイプラインを構築しました.このプロジェクトでは,推論システムも構築する必要があったため,そもそもStep Functionsでモデルのデプロイまで持っていけるのかというところから技術検証したり,推論速度といった非機能要件なども検討して処理を考える必要があったりと難しい部分もありました.また,PoCは別のメンバーが担当していたこともあり,Jupyter Notebookからプロダクション用のシステムに合わせたコードを作り上げる部分や再現性を取る部分でも苦労がありました.
これらの苦労の甲斐あって?無事に本番稼働しているこのシステムの状況としては,コスト削減という部分で,当初の期待通りxx万円/月のカットに寄与できていたり,サービス品質向上という部分では,質問の回答率が上がるといった成果が出ています.
一方で,推論の精度面で多少の検知漏れがあったりと少し改善が要求されたりする可能性があり,この辺りは継続的に改善が必要で,まさにMLOpsだなと感じています.
また,この取り組みは全ての投稿をチェックすることから,より違反確率が高い投稿のみを重点的にチェックすることができるため,作業量が減り作業者の精神的負荷が減ったり,作業効率化も上がるといった作業者側のメリットだけでなく,モデルが違反確率が高いと返した投稿の中にも問題ない(正常)投稿も含まれているため,これらを人間が正しく判定し直すことで,今後のモデル改善時に使える有効なアノテーションデータとして蓄積することができるメリットもあります.これらの取り組みはまさに「Human-in-the-Loop 」が上手く機能している状態ではないでしょうか.
おわりに
今回は前編・後編と2つの記事に分けてSageMakerとStep Functionsを用いた機械学習パイプラインにより構築した検閲システムの内容を紹介しました.特にStep FunctionsでのTrainingJobの活用例やモデルのデプロイ部分を組み込んだパイプラインに関する事例はあまり公開されていない内容かと思うので,是非参考にして頂ければと思います.
今回の取り組みはCSチームと連携して進めたことにより良い成果が出つつあると思うので,これからもサービスの品質向上やグロースに対して他チームと協力する中で機械学習を導入することでよりその価値を発揮していければと思います.
最後に,コネヒトではプロダクトを成長させたいMLエンジニアを募集しています!!(切実に募集しています!)@asteriam にTwitterDM経由でご連絡いただいてもOKです!)
www.wantedly.com