皆さん,こんにちは!機械学習エンジニアの柏木(@asteriam)です.
今回はタイトルにもあるようにモデルの学習からデプロイまで一気通貫した機械学習パイプラインをSageMakerとStep Functionsで構築し,新しく検閲システムを開発したお話になります.
こちらのエントリーで紹介されている機械学習を用いた検閲システムの技術的な内容になります.
※ 検閲システムの細かい要件や内容については本エントリーでは多くは触れないのでご了承下さい.
はじめに
今回のエントリーは内容が盛り沢山になっているので,前編と後編の2つに分けて紹介することにします.
- 前編:SageMaker TrainingJobを用いたモデル学習を行い,SageMaker Experimentsに蓄積された実験結果をS3に保存するまでの話
- 前回紹介したテックブログ「SageMaker Experimentsを使った機械学習モデルの実験管理」の内容を実際のプロダクション環境に適用した内容になります.
- 後編:SageMakerのリソースを用いてモデルのデプロイ(サービングシステムの構築)をStep Functionsのフローに組み込んだ話
- モデル学習後の一連の流れで,推論を行うためにモデルのデプロイやエンドポイントの作成をStep Functionsで実装した内容になります.
本エントリーはSageMakerとStep Functionsで機械学習パイプラインを構築しようと考えている人や独自の推論処理をSageMakerで動かしたい人向けの内容になります.
これらの内容に関する事例やテックブログは世の中にあまりなく,トライ・アンド・エラーを繰り返すことが多かったので,今後同じようなことを実装しようと考えている人の一助になればと思います.
ソニー創業者の井深大さんも以下のような名言を残されており,今回のプロジェクトは改めてSageMakerとStep Functionsの理解を深めることができ自分自身大きな経験となりました.
トライ・アンド・エラーを繰り返すことが、「経験」「蓄積」になる。独自のノウハウはそうやってできていく。
目次
- はじめに
- アーキテクチャー概要
- モデル学習にSageMaker TrainingJobを選択した理由
- SageMaker TrainingJobを用いたモデル学習
- SageMaker Experimentsの結果をS3に保存
- おわりに
アーキテクチャー概要
今回実装したシステムのアーキテクチャー概略図は以下のようになります.本エントリーで紹介するのはAWS Step Functionsで組んだ機械学習パイプラインの部分になります.
MLチームではレコメンドシステムもStep Functionsでパイプラインを組んでおり,今回も既に経験&知見があるStep Functionsを使って機械学習パイプラインを作成することにしました.
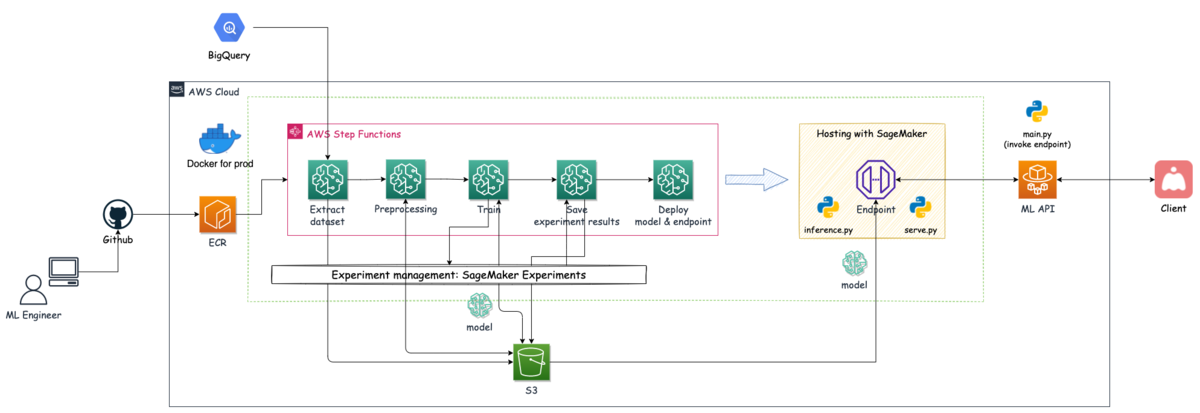
Step Functionsによるパイプラインを実行すると,データ抽出・前処理・モデルの学習・実験結果の保存といった処理が行われ,最終的に推論を行うためのモデルのデプロイが行われます.
デプロイされたサービングシステムはML API(ECS: 実行環境はFargate)からエンドポイントをinvokeされることで処理が走り,結果をML APIに返し,その結果をClientに返す流れになります.(ML APIはClientからリクエストを受けます)
SageMakerのCreateProcessingJob / CreateTrainingJobを使ってデータ抽出・前処理・モデル学習/評価・実験結果の保存まで行っており,モデルを含んだ推論コンテナのデプロイとエンドポイントの作成はSageMakerのCreateModel / CreateEndpointConfig / CreateEndpointを組み合わせて実施しています.
参考までに今回作成したStep Functionsのグラフインスペクターは以下のようなものになります.

今回作成したStep Functionsの処理と対応するSageMakerの処理の対応表は以下になります.
| No. | ステップ名 | SageMakerのアクション | 処理内容 |
|---|---|---|---|
| 1 | Dataset-Extracting-Step | CreateProcessingJob | BigQueryからデータを取得 |
| 2 | Dataset-Creating-Step | CreateProcessingJob | 学習と評価用のデータセット作成 |
| 3 | Model-Training-Step | CreateTrainingJob | モデル作成 |
| 4 | Experiments-Saving-Step | CreateProcessingJob | 実験結果の保存 |
| 5 | Model-Creating-Step | CreateModel | 推論コンテナの設定とモデルの作成 |
| 6 | EndpointConfig-Step | CreateEndpointConfig | エンドポイントの設定 |
| 7 | Endpoint-Creating-Step | CreateEndpoint | エンドポイントの作成とモデルのデプロイ |
次からのパートでは,モデル学習時に使用したTrainingJobの話とSageMaker Experimentsに蓄積された実験結果をS3に保存する話に焦点を当てています.
モデル学習にSageMaker TrainingJobを選択した理由
今回構築するパイプラインでは,以下の要素を含んだ方法で実現したいと考えていました.
- 実験の再現性を担保するために,SageMaker Experimentsに実験結果を保存したい
- 学習スクリプトはSDKなどAWS特有の記述を意識せずシンプルに作成したいので,面倒な設定はStep Functionsの定義に押し込めたい
一方で,上記を実現する方法としては2パターンあるかなと思います.
- ProcessingJobを使い,学習用スクリプト(train.py)とSageMaker SDKを用いたラップ用のスクリプトを使う方法
- TrainingJobを用いて,学習用スクリプト(train.py)を使う方法
1つ目の方法に関しては,以前のエントリーで実施した内容で,以前紹介したのはSageMaker Studioから実行した方法ですが,このコードをスクリプト化し,Step FunctionsのProcessingJobで実行する方法になります.こちらはもう少し説明すると,学習用スクリプト(train.py)を用意し,SageMaker SDKのEstimatorクラスを使い用意した学習用スクリプトをラップしたスクリプトを別途用意する必要があります.この場合は,ラップしたスクリプト内部or環境変数として設定用の変数を複数入れてやる必要があるので,複雑になってしまうかなと思います.また,SageMaker SDKのお作法を理解して実装する必要があります.
2つ目の方法は,SageMaker SDKのEstimatorクラスの設定をStep FunctionsのTrainingJobが担う方法です.こちらは設定をStep Functionsの定義に押し込めることができるので,ラップ用のスクリプトを別途用意する必要はなく,学習用スクリプトのみを用意するだけで大丈夫です.こちらの方がコードが複雑にならず,Step Functionsの定義を管理すれば良いです.
今回は2つ目の方法を採用し実装することにしました.(前提として独自のカスタムコンテナイメージを用いる想定です)
※ これらとは別に全てをコード管理して,SageMaker SDKやStep Functions SDKを使ったworkflowを構築する方法もあります.
参考: Amazon SageMaker Processing と AWS Step Functions Data Science SDK で機械学習ワークフローを構築する
SageMaker TrainingJobを用いたモデル学習
それでは実際の設定を見ていきますが,学習用スクリプト(train.py)については具体的な処理は載せることはできないので,実装イメージを載せておきます.
公式のサンプルコードも参考になると思うので,参考下さい.
参考: amazon-sagemaker-examples/advanced_functionality/scikit_bring_your_own
# train.py import argparse import os def main(params): # パラメータの受け取り max_length = params.max_length learning_rate = params.learning_rate epochs = params.epochs batch_size = params.batch_size # 以下にモデル学習に必要な処理を記述する(実際は色々とコードがあるが今回は省略) model_path_prefix = '/opt/ml/model/' model_path = os.path.join(model_path_prefix, 'bert_model.h5') create_model( X_train, y_train, X_valid, y_valid, learning_rate, epochs, batch_size, model_path ) # モデル作成を行う関数: train/validデータやハイパーパラメータなどを引数に渡す ... if __name__ == "__main__": # コマンドライン引数をパースする parser = argparse.ArgumentParser() # モデルのハイパーパラメータ引数 parser.add_argument( "--max_length", type=int, default=512, help="The maximum length of a sentence to use as input" ) parser.add_argument( "--learning_rate", type=float, default=3e-5, help="Learning rate when model is created" ) parser.add_argument( "--epochs", type=int, default=5, help="Number of epochs when model is created" ) parser.add_argument( "--batch_size", type=int, default=12, help="Number of batch size when model is created" ) params, _ = parser.parse_known_args() main(params)
学習したモデルは '/opt/ml/model/' 配下に格納され,このファイルが後述するStep Functionsの定義で指定したファイルパスに同期されます.ここはモデルデプロイ時にも関係してくるので,パス設定は重要になります.
このコードに関する実行権限をDockerfileで与える必要があるので,ここは以前のエントリーの「カスタムコンテナで実行するための準備」の部分を参考にして頂ければと思います.
また,今回はGPU環境での学習になるので,カスタムコンテナイメージを使ってSageMaker TrainingJobを動かす方法は手前味噌ですが,Step Functionsで自作Dockerfileを使ってSageMakerのGPUマシンを動かす方法を参考下さい.
Step Functionsの定義設定 - モデルの学習を行う処理
次にStep Functionsの定義設定でTrainingJobの設定部分だけを取り出して説明していきます.
"Model-Training-Step": { "Comment": "モデル作成処理", "Type": "Task", "Resource": "arn:aws:states:::sagemaker:createTrainingJob.sync", "Parameters": { "RoleArn": "arn:aws:iam::<アカウントID>:role/StepFunctions_SageMakerAPIExecutionRole", "TrainingJobName.$": "States.Format('{}-{}', $$.Execution.Name, $$.State.Name)", "AlgorithmSpecification": { "EnableSageMakerMetricsTimeSeries": true, "MetricDefinitions": [ { "Name": "Train Loss", "Regex": "train_loss: (.*?);" }, { "Name": "Validation Loss", "Regex": "val_loss: (.*?);" }, { "Name": "Train Metrics", "Regex": "train_accuracy: (.*?);" }, { "Name": "Validation Metrics", "Regex": "val_accuracy: (.*?);" } ], "TrainingImage": "<アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/sample:latest-gpu", "TrainingInputMode": "File" }, "EnableInterContainerTrafficEncryption": true, "EnableManagedSpotTraining": true, "Environment": { "PYTHON_ENV": "prod", "SAGEMAKER_PROGRAM": "/opt/program/train.py" }, "ExperimentConfig": { "ExperimentName": "prod-sample-experiment", "TrialName": "training-job", "TrialComponentDisplayName.$": "States.Format('{}', $$.Execution.Name)" }, "HyperParameters": { "max_length": "512", "learning_rate": "3e-5", "epochs": "5", "batch_size": "12" }, "CheckpointConfig": { "LocalPath": "/opt/ml/checkpoints/", "S3Uri": "s3://sample-prod-ml-data/workplace/model/checkpoints/" }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataDistributionType": "ShardedByS3Key", "S3DataType": "S3Prefix", "S3Uri": "s3://sample-prod-ml-data/workplace" } }, "InputMode": "File" } ], "OutputDataConfig": { "S3OutputPath": "s3://sample-prod-ml-data/workplace/model/" }, "ResourceConfig": { "InstanceCount": 1, "InstanceType": "ml.g4dn.xlarge", "VolumeSizeInGB": 10 }, "StoppingCondition": { "MaxRuntimeInSeconds": 86400, "MaxWaitTimeInSeconds": 86400 } }, "Catch": [ { "ErrorEquals": [ "States.ALL" ], "Next": "NotifySlackFailure" } ], "Next": "Experiments-Saving-Step" }
RoleArn: S3, ECRにアクセスでき,SageMakerとStep Functionsのポリシーを持ったロールを指定する必要があります.エラーが発生した場合は適宜必要なポリシーをアタッチして下さい.MetricDefinitions: 学習時に出力しているログから正規表現を用いて結果をExperimentsに保存することができます.必要な評価指標をログ出力しておき,ここで取れるようにしておきます.TrainingImage: ECRに登録したdocker imageのURIを指定します.今回はGPU版のimageを用意してそれを使用しています.EnableManagedSpotTraining:trueを設定することでスポットインスタンスを使った学習が可能になります.ただし,CheckpointConfigを設定していないと状況次第で学習が停止し,また最初から始まってしまうので,注意が必要です.Environment: 環境変数を指定することができます.今回大事なのは,SAGEMAKER_PROGRAMの変数でここで指定したパスのスクリプトが実行されることになります.ExperimentConfig: SageMaker Experimentsに結果を保存する設定を行います.ExperimentNameとTrialNameは事前に作成しておく必要があります.(TrialNameとTrialComponentDisplayNameに関しては指定しない場合,自動的に適当な値が付与されますが,管理する上で把握しておく必要があります)今回はSageMaker Studioで事前に作成していますが,CreateExperimentやCreateTrialを使うことでStep Functionsの処理の1つとして実行することができます.HyperParameters: 学習時に使うハイパーパラメータや実験結果として残しておきたい値を入れておくことで保存されます.OutputDataConfig: 学習済みモデルを保存する場所になります.コンテナ内の’/opt/ml/model/'に保存されたモデルファイルがmodel.tar.gzとして圧縮された形で設定したパスに保存されます.これをモデルデプロイ時のモデルパスに指定する必要があります.
ResultPathはTrainingJobの出力結果を後続の処理で使用したいので,nullの設定はしていません.その他の設定値はCreateTrainingJobを参考下さい.
CloudWatch Logsの結果を見ると,学習が実施できていることがわかります.これでTrainingJobを用いた学習を実施することができました.

SageMaker Experimentsの結果をS3に保存
学習後の実験結果はSageMaker Experimentsに保存されており,UI上だとSageMaker Studioからしか確認することができません.他のビジネス指標などと比較したい場合に毎回SageMaker Studioを見に行ったりすることは大変ですし,ダッシュボードなどで同時に見れることが望ましいです.コネヒトではBIツールとしてredashを使っているので,結果をcsvでS3に保存しておくとAthena経由でredash上で確認することができます.
モデル学習のステップの後に,実験結果の保存を行うステップを入れて対応しています.
upload_experiments.pyというスクリプト内で,SageMaker SDKを使用してsagemaker.analytics.ExperimentAnalyticsから記録した実験結果にアクセスして,必要な情報をデータフレームに整理して結果をcsvとしてS3にアップロードする流れになります.
SageMaker SDKを使用して実験結果を取得してみると,モデルの学習に要した時間が取得できなかったため上述したTrainingJobの出力結果をStep Functionsのステップで環境変数として渡すことで工夫しています.スクリプト内にos.environ['TRAINING_START_TIME']とos.environ['TRAINING_END_TIME']のような形で変数を受け取り終了時刻から開始時刻を引くことで経過時間を算出しています.この計算した値や学習した日付などの情報も合わせてデータフレームに記録するようにしています.
以下がTrainingJobの出力結果(不要な部分は一部削除しています)です.
{ "TrainingJobName": "4fc2550d-d694-3a8c-607a-368bbdd2a97d-Model-Training-Step", "ModelArtifacts": { "S3ModelArtifacts": "s3://sample-prod-ml-data/workplace/model/4fc2550d-d694-3a8c-607a-368bbdd2a97d-Model-Training-Step/output/model.tar.gz" }, "TrainingJobStatus": "Completed", "HyperParameters": { "batch_size": "12", "epochs": "5", "learning_rate": "3e-5", "max_length": "512" }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3_PREFIX", "S3Uri": "s3://sample-prod-ml-data/workplace/", "S3DataDistributionType": "SHARDED_BY_S3_KEY" } }, "CompressionType": "NONE", "RecordWrapperType": "NONE" } ], "OutputDataConfig": { "S3OutputPath": "s3://sample-prod-ml-data/workplace/model/" }, "CreationTime": 1644856394459, "TrainingStartTime": 1644856580969, "TrainingEndTime": 1644873275331, "LastModifiedTime": 1644873275331, "SecondaryStatusTransitions": [ { "Status": "Starting", "StartTime": 1644856394459, "EndTime": 1644856580969, "StatusMessage": "Preparing the instances for training" }, { "Status": "Downloading", "StartTime": 1644856580969, "EndTime": 1644856654265, "StatusMessage": "Downloading input data" }, { "Status": "Training", "StartTime": 1644856654265, "EndTime": 1644873137479, "StatusMessage": "Training image download completed. Training in progress." }, { "Status": "Uploading", "StartTime": 1644873137479, "EndTime": 1644873275331, "StatusMessage": "Uploading generated training model" }, { "Status": "Completed", "StartTime": 1644873275331, "EndTime": 1644873275331, "StatusMessage": "Training job completed" } ] }
Step Functionsの定義設定 - 実験結果の保存を行う処理
Step Functionsの定義設定は以下のようになっており,この処理はProcessingJobを使用しています.
"Experiments-Saving-Step": { "Type": "Task", "Resource": "arn:aws:states:::sagemaker:createProcessingJob.sync", "Parameters": { "AppSpecification": { "ImageUri": "<アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/sample:latest-cpu", "ContainerEntrypoint": [ "python3", "/opt/program/upload_experiments.py" ] }, "Environment": { "PYTHON_ENV": "prod", "AWS_DEFAULT_REGION": "ap-northeast-1", "EXPERIMENT_NAME": "prod-sample-experiment", "TRIALS_NAME": "training-job", "TRIAL_COMPONENT_DISPLAY_NAME.$": "States.Format('{}', $$.Execution.Name)", "TRAINING_START_TIME.$": "States.Format('{}', $.TrainingStartTime)", "TRAINING_END_TIME.$": "States.Format('{}', $.TrainingEndTime)" }, "ProcessingResources": { "ClusterConfig": { "InstanceCount": 1, "InstanceType": "ml.t3.medium", "VolumeSizeInGB": 5 } }, "RoleArn": "arn:aws:iam::<アカウントID>:role/StepFunctions_SageMakerAPIExecutionRole", "ProcessingJobName.$": "States.Format('{}-{}', $$.Execution.Name, $$.State.Name)" }, "Catch": [ { "ErrorEquals": [ "States.ALL" ], "Next": "NotifySlackFailure" } ], "ResultPath": null, "Next": "Model-Creating-Step" }
Environment: 環境変数に1つ前のTrainingJob(モデル学習ステップ)の出力結果であるTRAINING_START_TIMEとTRAINING_END_TIMEを参照して使用しています.これが先ほど説明した部分になります.
保存したcsvをデータフレームで表示する以下のような形になります.Trainingtimeとdatetimeが追加した部分になります.

おわりに
本エントリーの前編はモデル学習とその実験結果の保存に焦点を当てて紹介しました.Step FunctionsのSageMaker TrainingJobを使用したパイプライン構築を行った事例はほとんどないと思っているので,参考になれば嬉しいです.ちなみにSageMaker StudioのJupyter Notebookを使った手動実行の事例はいくつか存在していますし,公式のサンプルノートブックも多数あります.
今回の紹介した部分はMLOpsでいうところの「実験管理」や「パイプライン構築」にあたり,再現性や継続的な学習(Continuous Training)に繋がる部分になると思っています.
例えばパイプラインは,EventBridgeを使うことで定期的にモデルの更新を実施することが可能になりますし,モニタリングしている指標の変化を検知し,それをトリガーにしてモデルの更新を行うなどの方法も考えられます.
また,SageMaker Experimentsに実験結果を保存していくことでチームで結果を共有することができ,どういったパラメータでオフラインの評価指標がどうだったかなど知見として残し再現性を担保できるようになったのは大きな前進かなと思います.
一方で,TrainingJobを使う点において少し辛い点を書くと以下が挙げられます.
- デバッグがしんどい
- 実行時間がそれなりにかかる
動作確認するためにStep Functionsで処理を組んで実行すると起動するまでに時間がかかるのと,コード変更が入った時に毎回ECRにイメージをpushしてから再実行となるので,デバッグするのに一苦労かかります.そもそもエラーが分かりづらいという部分もありますが...笑
後編では,作成したモデルのデプロイと推論を行うためのエンドポイントのデプロイの部分について紹介します.
最後に,コネヒトではプロダクトを成長させたいMLエンジニアを募集しています!!(切実に募集しています!)
もっと話を聞いてみたい方や,少しでも興味を持たれた方は,ぜひ一度カジュアルにお話させてもらえると嬉しいです.(僕宛@asteriamにTwitterDM経由でご連絡いただいてもOKです!)