こんにちは。インフラエンジニアの永井(shnagai)です。
今回は、ECS×Fargateで運用しているサービスの「ターゲット追跡ServiceAutoScalling」をチューニングをしたことで、費用が約半分になるという大きな成果を残すことが出来たのでその内容を経緯と共にまとめています。
内容はざっくり下記3点です。
- なぜオートスケールのチューニングをしたのか?
- 「ターゲット追跡ServiceAutoScalling」のチューニング方法
- どんな結果になったか?
なぜオートスケールのチューニングをしたのか?
コネヒトではWebのアーキテクチャはほとんどECS×Fargateの基盤で動かしています。そして、オートスケールとして「ターゲット追跡ServiceAutoScalling」を使うことで、Fargateのメリットを最大限活かす形で運用コスト低くサービス運用を実現しています。
ここらの話は下記のスライドやブログに詳しく書いているので興味がある方はご覧ください。
ECS×Fargateで実現する運用コストほぼ0なコンテナ運用の仕組み/ ecs fargate low cost operation
ECS×Fargate ターゲット追跡ServiceAutoScallingを使ったスパイク対策と費用削減 - コネヒト開発者ブログ
これまで約1.5年ほど初期に設定したオートスケールのしきい値で問題なくサービス運用出来ていたのですが、ある時を境にレイテンシ悪化のアラートが頻発するようになりました。
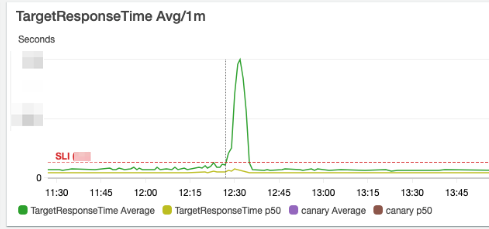
よくわからないレイテンシ悪化だったので、アプリケーション側やインフラ側のレイテンシ悪化前後での変更、そしてアクセス特性の分析といった調査をして原因切り分けを行っていきました。
その中で、現状のオートスケールのしきい値 (CPU使用率を30%程に収束させるような「ターゲット追跡ServiceAutoScalling」の設定)では、特定コンテナのLoadAverage(LA)が跳ね上がり、そのコンテナの処理が遅くなることで平均レイテンシが上振れしているという事象を突き止めました。
スパイク的なアクセスに今までは耐えられていたのですが事象がしばらく続いてしきい値を調整しても事象は収まらなかったので、 「ターゲット追跡ServiceAutoScalling」1本で行くのは限界と判断し、新たにECSの「ステップスケーリングポリシー」を導入しました。
ECSのステップスケーリングポリシーとは何か?
「ターゲット追跡ServiceAutoScalling」がCPU使用率/メモリ使用率/リクエスト数の3つから追跡するメトリクスと値を選択することで、ECS側でタスク必要数 (起動するコンテナ数)をしきい値に収束するように動的にコントロールしてくれる機能なのに対して、「ステップスケーリングポリシー」は特定のトリガが発生した時に一気にスケールアウトして タスク必要数 を増やすような用途に使えます。
今回の対応だと、 CPU Utilization Max の値がしきい値を超えたタイミングで、タスクを3つスケールアウトするような設定を入れました。具体の挙動としては、「ステップスケーリングポリシー」を設定すると、裏でCloudWatchAlarmが作られて、そのアラームをトリガーとしてECS側でスケールアウトが走るような仕組みになっています。
これを入れることで、スパイクの初動の段階で一気にスケールアウトが走るようになりレイテンシ悪化のアラームを抑えることに成功しました。
次なる課題
「ステップスケーリングポリシー」を導入したことによってレイテンシアラームは抑えることに成功したのですが、思想的に十分な余裕を持ってリクエストを迎えるための設定になるのでタスクの起動数が上振れ(費用増)するようになりました。「ターゲット追跡ServiceAutoScalling」のしきい値はそのままに、「ステップスケーリングポリシー」でオートスケールを追加したので当然の結果です。
ここからは、「ターゲット追跡ServiceAutoScalling」のチューニングをして、Fargateタスクの平均起動数を下げることで費用削減にチャレンジしました。
「ターゲット追跡ServiceAutoScalling」のチューニング方法
チューニングの方針として、「タスクあたりのリクエスト数(1コンテナが捌くリクエスト数)」を上げるのを目的に、「ターゲット追跡ServiceAutoScalling」でしきい値としているCPUUtilization avgを上げていくアプローチをとりました。
下記のキャプチャは、CloudWatchで見られる RequestCountPerTarget の推移なのですが、短期で見ると振れ幅ありつつも長期トレンドでは徐々に下がっていることがわかります。これが下がるということは、全体のリクエスト数は少しずつ成長しているとした場合に、1タスクあたりのコスト効率が悪化していることを意味します。
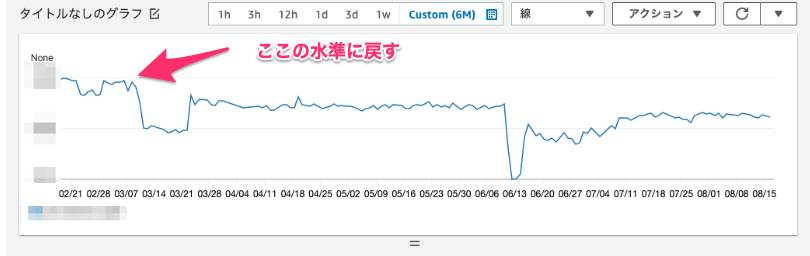
「ターゲット追跡ServiceAutoScalling」のチューニング方法としては、下記を繰り返して最適値を探りました。
- しきい値とするCPUUtilization avgの値を1%インクリメント
- 2日間問題が起きないかという様子を見る
- ガードレールメトリクスとして、アラートならずともレイテンシ悪化がゆるやかに起きていないかをチェックする
- 問題なければ1に戻る。該当期間にアラートが出たらしきい値を元に戻して2の様子見期間へ。
この繰り返しで1ヶ月程かけて最適値を探りました。チューニング方針が慎重すぎないか?という感想をもしかしたらもたれるかもしれません。
ただ、本番運用サービスでチューニングを行うので出来るだけリスクを抑えたいという判断から時間はかかりますが、1%ずつの調整を行うことにしました。
また、しきい値調整のオペレーション自体は軽く、監視も基本的にはアラートがならない限りはアクションしないという方針で取り組んだので、長い時間をかけることが出来たというのも正直なところです。
モニタリングには、CloudWatchを使ってモニタを作り、チューニングが与える変化をウォッチしていました。
下記の4項目を一つのモニタにまとめています。
- ALBのReqCount(該当サービスのリクエスト数)
- ECS CPUUtilization avg(該当ECSサービスのCPU使用率 平均)
- ECS CPUUtilization max(該当ECSサービスのCPU使用率 最大)
- ECS RunningTaskCount(該当ECSサービスで起動しているタスク数)
例えば、このモニタからこんなことが読み解けるような作りになっています。
- ALBのReqCountが急激に上がった時に、ECS CPUUtilization maxがしきい値を超えてECS RunningTaskCountが3タスクスケールアウトしており、ECS CPUUtilization avgはしきい値前後で収束している
- 夜間でALBのReqCountが落ちてくると、ECS CPUUtilization avgが収束し、RunningTaskCountが最小値の値までスケールインした
また、CloudWatchは水平/垂直の注釈を入れれるので設定変更のタイミングやしきい値に注釈を入れることでグラフを見ただけで読み取れる情報が格段に増えます。この機能は便利だなと思っています。

どんな結果になったか?
チューニングは、アラートが鳴るギリギリのところまでレイテンシが悪化する状況が見えてきたところで一旦インクリメントは終わりとして、しきい値から少しゆるめた落ち着いたところでFixさせました。
結果として目標においていた、以前の水準まで「タスクあたりのリクエスト数(1コンテナが捌くリクエスト数)」を上げることに成功しました。また、それに応じてSavingsPlansで購入する Compute Savings Plans を半分ほどに削減することが出来、システム運営費の削減に成功しました。
※この半年後のSavingsPlansの切れるタイミングで、測定したところ従来の半分くらいの購入で良いことが判明した

最後に宣伝です! コネヒトでは一緒に成長中のサービスを支えるために働く仲間を様々な職種で探しています。 少しでも興味もたれた方は、是非気軽にオンラインでカジュアルにお話出来るとうれしいです。