皆さん,こんにちは!機械学習エンジニアの柏木(@asteriam)です.
コネヒトでは,テクノロジー推進部に所属し,組織横断的に機械学習(ML)施策の実施・推進を通してサービスグロースする役割を担っています.
はじめに
MLチームでは,少人数ながらレコメンドエンジンの開発*1やカテゴリ類推*2などの機械学習を用いたサービス開発を実施しています.一方でプロダクション環境に投入するMLシステムの数が増えると,それら1つ1つが属人的になったり,テストが不十分だったり,運用が疎かになったり,それ以外に技術的にも負債が蓄積するケースがあります.私たちのチームでもこれらが課題の1つとなっています.
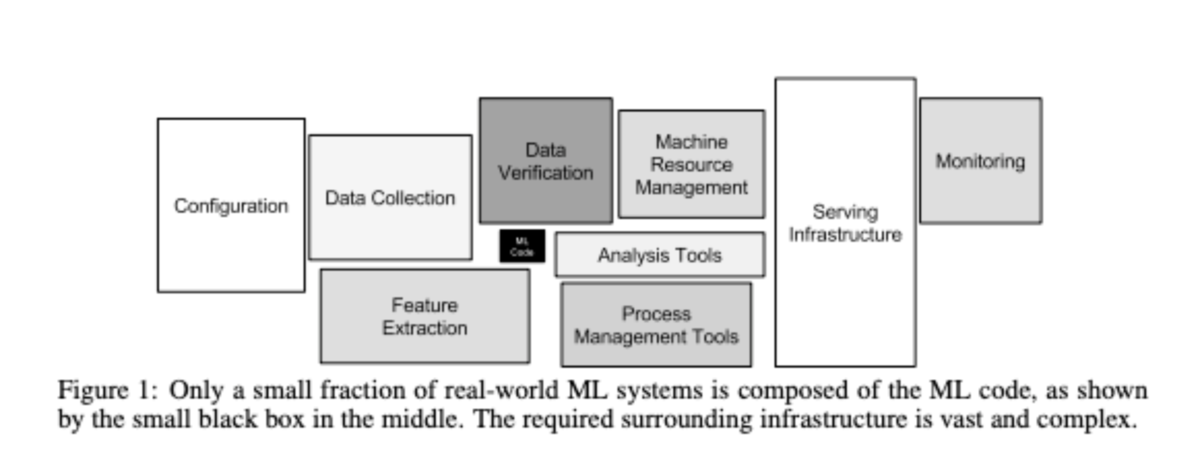
上図はよく目にするMLシステムの技術的負債の図*3ですが,MLシステムはモデル開発だけでなく,MLシステムを支える周辺のインフラや各種メトリクスのモニタリングなど考慮すべき項目が多くあります.加えてMLシステムの特性でもあるリリース後の継続的な学習・デプロイにも対応していく必要があり,これに対して場当たり的な対応をするとますます負債が溜まっていくことが考えられます.これらを解消していくためにもMLOpsが重要になってきます.
今回は,現状のMLシステムの技術的負債を定量化するために,ガイドラインとしてML Test Scoreを用いてスコアリングした内容になります.これを実施した目的は,MLOpsを実践するために何が足りていないか(AS-IS),そして何が必要なのか(TO-BE)を把握するためです.本来はMLシステムの技術的負債を可視化することを目的にしたものですが,これをMLOps実践の道標へと転用しました.
MLOpsを進めることで,少ない人数でも効率的かつ技術的負債を少なくしてMLシステムを回すことができるので,より施策を検討する時間やユーザーにとって良いサービスを作っていく部分に注力して行きたいと思っています.
※現在,このスコアリングした内容を元にMLOpsをAWSのサービスを用いて進めていますが,その内容については別の機会にご紹介出来たらと思います.
目次
MLOpsについて
最近色々とMLOps関連の話がありますが,包括的な内容としては,「MLOps Principles」や「ゆるふわMLOps入門」がとても参考になります.ここで述べられているMLOpsとは,MLシステムの構築運用に伴い生じる以下の課題を,効率的かつ継続的に取り組んでいくためのフレームワークや考え方のことになります.(MLOpsの定義は文脈により様々なのでご注意下さい)
- バージョン管理
- データセット,モデル,パラメータ,設定ファイルやその他生成物のバージョン管理など
- テスト
- データのバリデーションテスト,パイプラインテスト,単体/結合テスト,パフォーマンステストなど
- 自動化
- モデル作成のワークフローの自動化,CI/CDを使ったシステムの自動化など
- 再現性
- 特徴量生成の再現性,モデルの再現性,開発環境とプロダクション環境の環境差分など
- デプロイ
- プロダクション環境への継続的なデプロイなど
- モニタリング
- データドリフト,モデルの劣化,推論のパフォーマンスなど
加えて,組織的な問題や上記開発プロセスのイテレーティブな実行などもあります.
かなり広範囲でやるべきことが色々とあるなという印象ですが,MLOpsにもレベルがあるのでそちらを参考にしても良いかもしれません.
レベルの参考になるものとして,Microsoftが定義しているMachine Learning Operations maturity modelというMLOpsの成熟度を表すものがあります.これによると下図のレベル0~4までの5段階にまとめられています.
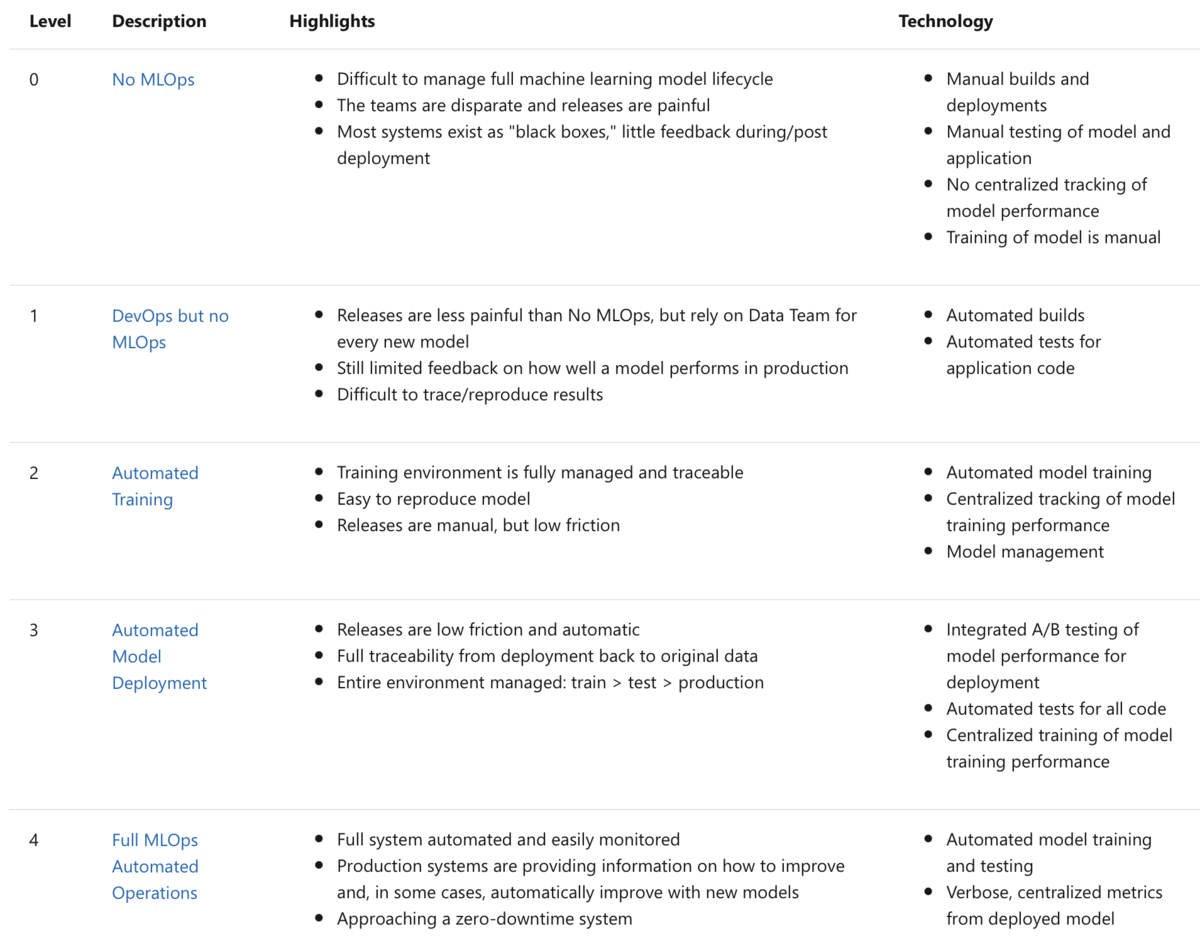
MLOps maturity modelは,人/カルチャー・プロセス/構造・オブジェクト/技術を定性的に評価するもので,各レベルで上記課題に関連する内容が整理されています.これを確認することで自分達のチームがどこに位置して何が出来ているのか,また逆に何が出来ていないのかを把握することができます.
ちなみに僕たちのチームは現状レベル2で一部テストに関する項目は不十分なところが存在しています.対応出来ていない部分を把握することで次にどこに手を付ければ良いかを判断したり,もしくは何から手を付けたら良いかわからない場合には一度こちらを参考にして,自分達のチームに足りていない部分を整理し,優先順位を立てて取り組むのが良いと思います.
ML Test Scoreとは
今回のメイントピックになります.MLOps maturity modelと似た内容がこちらにも含まれていますが,MLOps maturity modelが定性的に評価するものに対して,ML Test ScoreはMLシステムを定量的に評価できるものになります.
これはGoogleが発表したThe ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reductionという論文で紹介されているものになります.また日本語訳された記事([抄訳] The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction)もあるので,参考にしてみて下さい.
ここでは,「オンラインで継続的に学習され,推論を行う教師ありの機械学習システム」を前提にしています.論文で言及されているテスト項目は大きく以下の4つになります.
- 特徴量とデータのテスト
- モデル開発のテスト
- 機械学習インフラのテスト
- 機械学習のモニタリングテスト
各項目に7つの検査項目があり,スコアリング方法は「結果をドキュメント化し,テストを手動実行している」場合は0.5ポイント,「テストを自動的に繰り返し実行できるシステムがある」場合は1.0ポイントとなっています.4つのテスト項目毎にポイントを合計(7つの検査項目の合計)し,4つのテスト項目のポイントの最小値が最終的なML Test Scoreになります.これはどれか1つだけ高くても良くなく,4つのテスト項目すべてが重要であることを意味しています.ML Test Scoreを上げるためには,4つのテスト項目すべてのポイントを上げる必要があります.
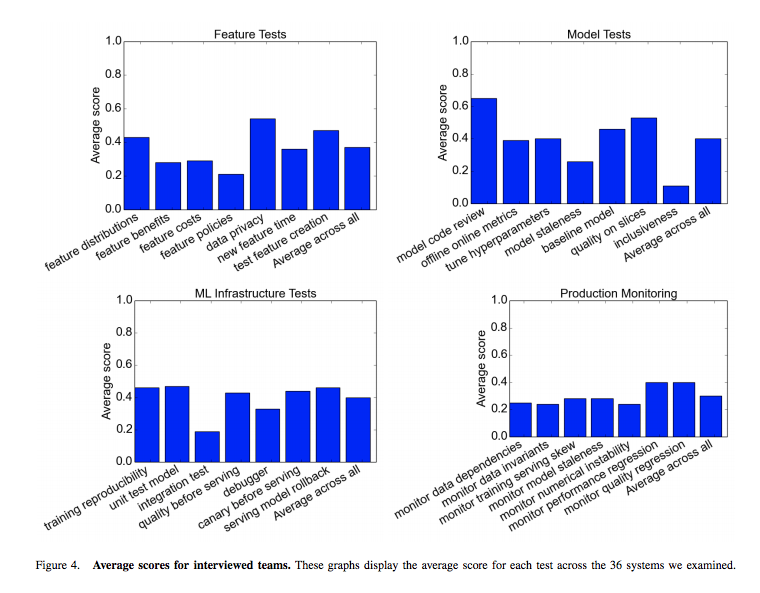
Googleのいくつかのチームを対象にした調査では,80%以上のチームが上記4つのテスト項目の多くを実施出来ていなかったということです.下図は調査したチームの4つのテスト項目のスコア平均値になりますが,Googleでも高得点が取れていないことがわかります.やはりMLシステムの構築運用時に生じる課題をクリアすることが難しいと改めて感じます.
また,ML Test Scoreの解釈も記載されています.(下記表は[抄訳] The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reductionからの引用)
| ポイント | 解釈 |
|---|---|
| 0 | プロダクションシステムというよりは研究プロジェクト |
| (0, 1] | 総合的にテストはされていないが,可能な限り信頼性向上に努めている |
| (1, 2] | 基礎的なプロジェクトの要求事項は通過した.しかし,信頼性向上のためのさらなる投資が必要とされる |
| (2, 3] | 適切なテストがされている,だが更に自動化の余地が残っている |
| (3, 5] | 信頼性の高い自動化されたテストとモニタリングレベル.ミッションクリティカルな状況でも問題はない |
| > 5 | 卓越したレベルの機械学習システム |
どのようにML Test Scoreをスコアリングしたのか
まず代表となる機械学習プロジェクトを選択し,それをベースにスコアリングをするようにしました.実際のプロジェクトに当てはめてスコアを付けていくのがイメージも付けやすいし良いと思います.
スコアリングは日本語訳をしてくれているShunya Uetaさんが公開してくれているGoogle Spread Sheetsを用いて行いました.簡単に計算できるようになっているので,非常にありがたかったです!
各検査項目については論文を見て頂ければわかりますが,検査項目とその内容,さらにどのようにすればいいか(How)が書かれています.しかし,それだけだと少しわかりづらい部分もあるので,検査項目の内容をもう少し噛み砕いて自分達のケースだとどうなるかを議論しました.
例えば,特徴量とデータのテスト項目にある「Data 2: 有効な特徴量かどうかを判別できていること」では,以下のように考えています.
- 「Data 2: 有効な特徴量かどうかを判別できていること」とは?
- 不要な特徴量を使わないようにする
- どういう特徴量かを把握することが大切
- タスク毎に有効/無効な特徴量がある
- 自動化するイメージとしては,GBDTのFeature Importanceを確認して,閾値以下の値を切り捨てる
こちらは一例ですが,全ての項目に対して内容を深掘りをして,具体的にイメージしやすいようにしました.また,スコアを付ける上で手動・自動の定義は先に述べたように定義がありますが,この部分もどういった状態であれば自動化された状態なのかと再定義をしています.
機械学習インフラのテストについての手動・自動の定義をサンプルとして載せておきます.いざ実際に自動化をしていく時に,どういった状態になればいいかわからないと進んで行かないと感じたので,チーム内で議論しながら整理して行きました.

項目については,自分達のチームに必要だと思うものは追加したり,中にはピンと来ない項目もあって削除しようかと考えるものもありました,スコアリングはあくまで一つの指標なので拘りすぎなくても良いかなと考えています.最初に書いた目的のためにより良くなるのであればアップデートしていくことが大事だと思っています.(本来は検査項目の数を合わせないとスコアが本来の値と乖離してしまうので,ご注意下さい)
ML Test Scoreでスコアリングした結果
4項目についてスコアリングした結果,OVERALL ML TEST SCORE = 1.5(参考値)になりました.各項目のスコアは以下になります.
- 特徴量とデータのテスト: 合計スコア = 2.5
- モデル開発のテスト: 合計スコア = 2.0
- 機械学習インフラのテスト: 合計スコア = 1.5
- 機械学習のモニタリングテスト: 合計スコア = 2.5
解釈によると「基礎的なプロジェクトの要求事項は通過した.しかし,信頼性向上のためのさらなる投資が必要とされる」というレベル感になります.結果を見ると,インフラの部分がまだまだ足りていないことがわかります.また検査項目毎で見ていくと0の項目も多く,まずは手動でも実践しないといけないなと感じる部分が多くありました.
伸びしろも多くあるので,これをベースに足りていない部分を補強して1つずつMLOpsを進めて行きたいと思います.
おわりに
今回は,ML Test Scoreを使って現状の機械学習システムのスコアリングを実施しました.現状把握をすることが出来たので,ようやくスタートラインに立てたかなと思います.まだまだ足りていない部分は多いですが,出来ることが多くあるのでツールなどを活用しながら進めて行きたいと思っています!これからが楽しみですね!!
最後に,私たちのチームではデータを活用したサービス開発を一緒に推進してくれるデータエンジニアを募集しています. 少しでも興味を持たれた方は,ぜひ一度お話させてもらえるとうれしいです.
参考
- Hidden Technical Debt in Machine Learning Systems
- MLOps Principles
- ゆるふわMLOps入門
- Machine Learning Operations maturity model
- The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
- [抄訳] The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
- Continuous Integration and Deployment for Machine Learning Online Serving and Models
- MLOps: Continuous delivery and automation pipelines in machine learning