皆さん,こんにちは!機械学習エンジニアの柏木(@asteriam)です.
本エントリーはコネヒトアドベントカレンダーの15日目の記事になります.
今回は機械学習モデルの実験管理をする際に使用しているAWSのSageMaker Experimentsの活用例を紹介したいと思います.
アドベントカレンダー1日目でたかぱいさんがSageMaker Processingの使い所を紹介してくれているので,こちらも併せて参考下さい.
はじめに
前回のエントリー*1でML Test Scoreの話をしましたが,その際にMLOpsの大事な要素である再現性(モデル学習など)に触れました.今回はこのモデル学習の再現性のために必要な実験結果(ハイパーパラメータの引数の値,モデル評価指標など)の管理をSageMaker Experimentsでしているというお話です.
※本エントリーは主にSageMaker Experimentsで実験管理しようとしている人向けの内容になります.
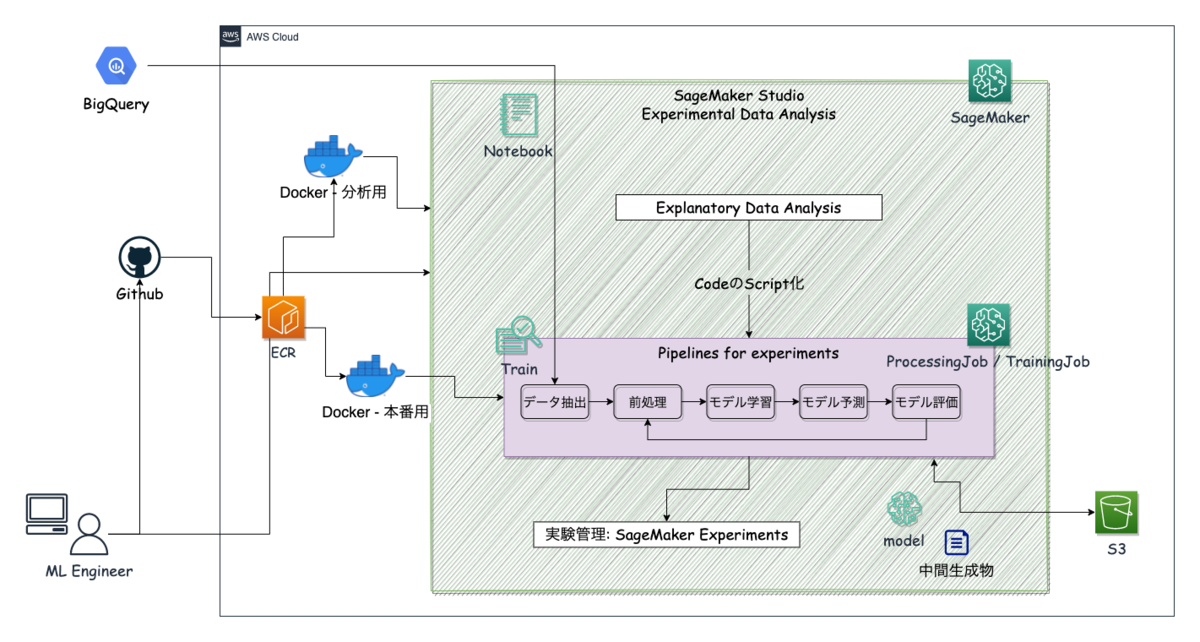
今回説明する部分は,こちらのアーキテクチャーの概略図でいうと,AWSで実験的にデータ分析を行う環境の「実験管理: SageMaker Experiments」になります.
トーマス・エジソンも以下のような名言を残しているので,何回も無駄な実験を繰り返さないため,また振り返った時にわかるように実験管理はきちんととしようねという気持ちです.
私は今までに一度も失敗をしたことがない。電球が光らないという発見を今まで二万回しただけだ。 それは失敗じゃなくて、その方法ではうまくいかないことがわかったんだから成功なんだよ。
目次
- はじめに
- SageMaker Experimentsとは?
- なぜSageMaker Experimentsなのか
- SageMaker Jobについて
- Estimatorを実行して,実験管理を行う方法
- Experiment Analyticsで結果をDataFrameで確認
- (おまけ)Trainコード(train.py)のTips
- 今後について
- おわりに
- 参考(再掲)
SageMaker Experimentsとは?
SageMaker Experimentsとはなんぞや?というと,公式ドキュメントによると以下のような機能になります.
Amazon SageMaker Experiments is a capability of Amazon SageMaker that lets you organize, track, compare, and evaluate your machine learning experiments.
機械学習モデルの再現性を担保するために必要な情報(モデルのバージョン管理や学習の追跡・比較・評価など)を収集して管理することができる機能で,記録をGUI上から確認することができます.(SageMaker ExperimentsはAmazon SageMaker Studioと連携されているので,SageMaker Studio (Jupyter Labのインターフェース)の画面から確認できます)
機械学習はイテレーティブな実験が必要になりますが,何度もモデル学習を行っていると,どのモデルが最も性能が良くてその時のハイパーパラメータや評価指標の値が何で設定はどうだったかなど,きちんと管理しておかないとわからなくなります.これらの実験管理をSageMakerを使った学習時にも実施できるのが,SageMaker Experimentsになります.
なぜSageMaker Experimentsなのか
実験管理のツールは,OSSの製品も多くあり代表的なものでいうとMLflowなどがあると思います.その中でなぜ私たちがSageMaker Experimentsを使うのかというと,大きく2点あります.
- AWSの各種サービスを機械学習プロジェクトで使用しており,それらと相性が良いもの
- 再現性に必要なメタデータを管理でき,チームで共有しながら簡単に確認できること
①について,いくつかメリットがあります.
- データ同期はS3と簡単に行える
- SageMakerのリソースを使って実験した際に,AWSのSetting情報も収集することができる
- ログはCloudWatch Logsで確認することができる
- Step Functionsに組み込んでパイプラインを動かした時にも実験のログが取れる
②については,他のツールでも実現できるところかなと思います.一方でMLflowなどを使う場合,共有するとなるとトラッキング用にサーバーをホスティングする必要性があったり,それを別途管理・運用する必要が出てきます.
これらを踏まえた上でまずはSageMaker Experimentsで色々と試していこうということになりました.
一方で少し物足りない or 使いづらい部分もあります.
- 実験後の結果に対して,どうゆう実験内容だったかなどのコメントを入れることができない
- 実装方法がSageMakerのフレームワークに則る必要があり,その理解に時間がかかる
SageMaker Jobについて
Create an Amazon SageMaker Experimentから拝借した下記表ですが,Jobとして主に使うのはTrainingとProcessingの2つになるかなと思います.特に実験管理を行う場合には,TrainingのEstimatorを使うことになります.今回はこのEstimatorに焦点を当てたいと思います.
| Job | SageMaker Python SDK method | Boto3 method |
|---|---|---|
| Training | Estimator.fit | CreateTrainingJob |
| Processing | Processor.run | CreateProcessingJob |
| Transform | Transformer.transform | CreateTransformJob |
Estimatorを実行して,実験管理を行う方法
カスタムコンテナでTraining Jobを実行し,Estimator.fitを利用してトレーニングモデルの実験管理を行います.
カスタムコンテナで実行するための準備
AWS SageMakerのTraining Jobを実行するためには,SageMakerのお作法に則る必要があります.
SageMakerのTraining Jobを実行する際,デフォルトではdocker run {image} trainのコマンドが実行されます.このことから,trainというファイルを用意し,コマンドにパスを通し,実行権限を付与する必要があります.
一方で,DockerfileにSAGEMAKER_PROGRAMの環境変数を設定すれば,ここで指定したプログラムが実行されます.参考までにDockerfileの記述例を載せておきます.
ただし,sagemaker-trainingのpythonライブラリをインストールしていないと,正常に動作しなくなるので注意して下さい!
FROM python:3.8 # Set some environment variables. # PYTHONUNBUFFERED keeps Python from buffering our standard # output stream, which means that logs can be delivered to the user quickly. ENV PYTHONUNBUFFERED=TRUE # PYTHONDONTWRITEBYTECODE keeps Python from writing the .pyc files which # are unnecessary in this case. ENV PYTHONDONTWRITEBYTECODE=TRUE RUN apt-get -y update && apt-get install -y --no-install-recommends \ curl \ sudo \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* # Install 'sagemaker-training' library COPY requirements.lock /tmp/requirements.lock RUN python3 -m pip install -U pip && \ python3 -m pip install -r /tmp/requirements.lock && \ python3 -m pip install sagemaker-training && \ rm /tmp/requirements.lock && \ rm -rf /root/.cache # Timezone jst RUN ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime # Locale Japanese ENV LC_ALL=ja_JP.UTF-8 # Set up the program in the image ENV PROGRAM_DIR=/opt/program COPY src $PROGRAM_DIR WORKDIR $PROGRAM_DIR ENV PATH="/opt/program:${PATH}" # SageMaker Training RUN chmod +x $PROGRAM_DIR/train.py ENV SAGEMAKER_PROGRAM $PROGRAM_DIR/train.py CMD ["python3"]
以下の記事が参考になったので,挙げておきます.
Experimentsを使った実験管理
今回はSageMaker Studio (Jupyter Labのインターフェース)を使って実験を行う場合を想定しています.
- SageMaker Experiments SDKをインストールしていない場合は,インストールします.
pip install sagemaker-experiments
# 必要なライブラリのインポート import time import boto3 import sagemaker from sagemaker import get_execution_role from sagemaker.inputs import TrainingInput from sagemaker.estimator import Estimator from smexperiments.experiment import Experiment from smexperiments.trial import Trial from smexperiments.trial_component import TrialComponent from smexperiments.tracker import Tracker from sagemaker.analytics import ExperimentAnalytics # ロールやセッションの設定 role = get_execution_role() sess = sagemaker.Session() sm = boto3.Session().client('sagemaker') region = boto3.session.Session().region_name account = sess.boto_session.client('sts').get_caller_identity()['Account'] print(f'AccountID: {account}, Region: {region}, Role: {role}') # ECRにあるコンテナを指定 service_name = <service name> tag = 'mlops' image = f'{account}.dkr.ecr.{region}.amazonaws.com/{service_name}:{tag}' print('Image:', image)
SageMaker Experimentsには,Experiment・Trial・Trial Componentsがあり,左側から順番に上位の概念(クラス)になっています.これにプラスして,Trial Componentsに実験の情報などを記録することができるTrackerというものがあります.SageMaker Experiments SDKというSDKが用意されているので,これを用いてコードに組み込んでいきます.
例えば,あるプロジェクトを考えてみると...
- 1つのExperimentを作成する(これが1プロジェクトに相当)
experiment_nameにはこの実験のプロジェクト名を付けるイメージ- 一度作成すると同一名称では作成できない
- UIから削除できないので,注意が必要(コマンド実行で削除できるが,下の階層にあるデータを削除してからでないとExperimentの削除ができない)
# experimentの作成 experiment = Experiment.create(experiment_name="mlops-experiment01", description="Sample Experiments for MLOps.", sagemaker_boto_client=sm)
- Tracker.createでTrackerを作成し,それを用いてExperimentのメタデータを記録&追跡
- log_parameters, log_input, log_output, log_artifact, log_metricがあります
- 予め定義しておくものを必要に応じて追加します
- log_parameters, log_input, log_output, log_artifact, log_metricがあります
# trackerの作成 with Tracker.create(display_name=f"tracker-{int(time.time())}", sagemaker_boto_client=sm) as tracker: tracker.log_input(name="input-dataset-dir", media_type="s3/uri", value='s3://mlops/input/') tracker.log_input(name="output-dataset-dir", media_type="s3/uri", value='s3://mlops/output/')
- Trial.createで実行するTraining JobごとにTrialを作成
- Experimentに紐づく実験単位
- Training JobのTrialを作成し,Tracker情報を追加
# trialの作成 trial_name = f"training-job-{int(time.time())}" experiments_trial = Trial.create( trial_name=trial_name, experiment_name=experiment.experiment_name, sagemaker_boto_client=sm, ) # trial_componentの付与 sample_trial_component = tracker.trial_component experiments_trial.add_trial_component(sample_trial_component)
以下の記事は今回の記事のようにExperimentsを使用した記事になっていて,とても参考になりました.
Estimatorを定義して実行する
モデル作成を行うために,Estimatorを定義します.Estimatorクラスの引数にmetric_definitionsとhyperparametersを渡すことで学習ログのメトリクスとハイパーパラメータを記録することができます.
- metric_definitions: 正規表現を用いて学習ログからメトリクスを抽出できる(参考: Define Metrics)
- hyperparameters: trainスクリプト内でArgumentParserを用いてパラメータを渡せるようにすることで,セットしたハイパーパラメータを使って実験を行える
- sagemaker.estimator.Estimator().set_hyperparameters()でハイパーパラメータをセットできる
例えば,メトリクスとしてRMSEを使って学習する場合,metric_definitionsには以下のような正規表現を入れておくとログを取得することができます.(ただし,この辺りはtrain.pyの中でどのようにログを出力しているかにも依るので,適宜自身のコードに合わせて修正が必要になります)
# S3に保存されているデータのパス s3_train_data = sagemaker.inputs.TrainingInput( s3_data=<S3のデータセットパス>, ) # モデル作成 estimator = Estimator( image_uri=image, role=role, instance_count=1, environment={"PYTHON_ENV": "dev"}, instance_type="ml.m5.large", sagemaker_session=sess, output_path=<モデルのアウトプットパス>, base_job_name="training-job", metric_definitions=[ {'Name': 'Train Loss', 'Regex': 'train_loss: (.*?);'}, {'Name': 'Validation Loss', 'Regex': 'val_loss: (.*?);'}, {'Name': 'Train Metrics', 'Regex': 'train_root_mean_squared_error: (.*?);'}, {'Name': 'Validation Metrics', 'Regex': 'val_root_mean_squared_error: (.*?);'}, ], ) # ハイパーパラメータのセット estimator.set_hyperparameters( epochs=15, batch_size=1024, learning_rate=0.1, momentum=0.9, embedding_factor=20 ) training_job_name = f"estimator-training-job-{int(time.time())}" estimator.fit( {'train': s3_train_data}, job_name=training_job_name, # trialの情報を指定 experiment_config={ "ExperimentName": experiment.experiment_name, "TrialName": experiments_trial.trial_name, "TrialComponentDisplayName": estimator_trial_component.display_name, }, wait=True, )
こんな感じのログが出ると学習が始まっています.(wait=Trueを設定した場合のみ)
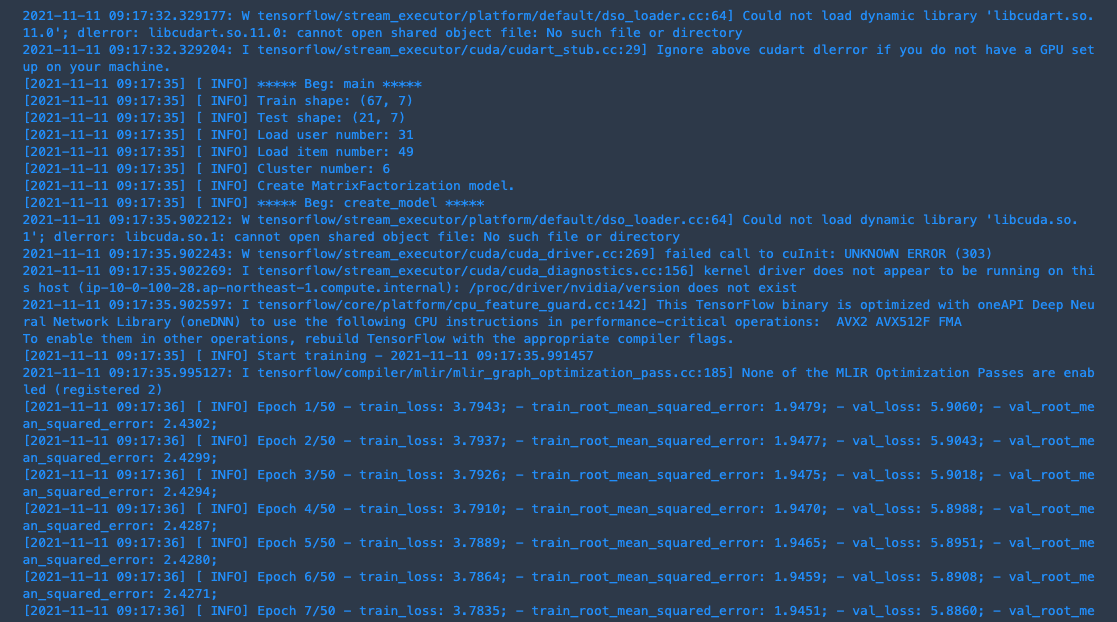
上手く学習が回って終了すると下図のように(Experiments and trialsから該当のTrial Componentsを見る),MetricsやParametersに指定した値が取れていることを確認することができます.


Experiment Analyticsで結果をDataFrameで確認
Experimentsに記録されているメタデータをDataFrameで確認することができるのがExperiment Analyticsになります.
- experiment_nameを引数に指定することで,実験結果を取得しDataFrame表示することが可能
- デフォルトだと全件取得されるので,欲しい実験だけフィルターして取得することも可能
trial_component_analytics = ExperimentAnalytics(
experiment_name="mlops-experiment01",
search_expression={
"Filters":[{
"Name": "DisplayName",
"Operator": "Equals",
"Value": "hogehoge"
}]
},
)
analytic_table = trial_component_analytics.dataframe()
display(analytic_table)

(おまけ)Trainコード(train.py)のTips
最後にEstimatorで実行されるtrain.pyのコードを書く際のTipsを載せておこうと思います.
Estimatorの機能の1つに,「Estimator.fit()のinputs引数で指定したデータはdocker上の'/opt/ml/input/data'に同期される」というものがあります.
例えば,Estimator().fit(inputs={'train': s3_train_data})とすると,データは'/opt/ml/input/data/train'配下にs3_train_dataで指定したデータセットが全て配置されるという形です.(ファイル指定した場合はそのファイルが,ディレクトリ指定した場合はディレクトリ以下のファイルが全て配置されます)
このことを知っていると,コード中にS3からデータをダウンロードする処理を書いている場合,そういったダウンロード処理が不要になるので便利です!
s3_train_data = sagemaker.inputs.TrainingInput(s3_data='s3://mlops/input/train.csv') Estimator().fit(inputs={'train': s3_train_data}) → S3にある'train.csv'が'/opt/ml/input/data/(inputsに指定した辞書のkeyが入る)/train.csv'に配置される dataset = '/opt/ml/input/data/train/train.csv' train = pd.read_csv(dataset)
参考
今後について
学習部分に関して実施していきたいことが大きく2つあります.
- Step FunctionsにSageMaker CreateTrainingJobを組み込む
- 現在,毎日レコメンドエンジンの学習が回っており,それをStep Functionsのパイプラインで実行しています.その際にSageMaker CreateProcessingJobを使っているのですが,これだと実験管理が十分にできないため,それをTraining Jobに置き換えて実行するというものです.これによりExperimentsに情報を蓄積できるため学習のログを簡単に可視化したり,オンラインのビジネス指標と比較したりすることもできます.
- SageMaker Pipelinesの活用
- ProcessingJobやTraining Jobを組み合わせることで,パイプラインを構築することができます.これを用いるとDAGによるフローの可視化をすることができたり,構築したパイプラインをそのままデプロイすることもできます.将来的にSageMakerでServingするところまで考えるとこの辺りの使用感を理解しておきたいところです.
おわりに
今回はSageMaker Experimentsを活用して,機械学習モデルの実験管理をしているということを紹介しました.自分自身がカスタムコンテナを使って学習実行して完了するまで少し苦労したので,この記事が参考になればと思います.
前回紹介したML Test Scoreの改善に向けてAWSのマネージドサービスを上手く活用しながら,今後も引き続きMLOpsを推進していきたいと思います.
最後に,私たちのチームではデータを活用したサービス開発を一緒に推進してくれるデータエンジニアを募集しています. もっと話を聞いてみたい方や、少しでも興味を持たれた方は,ぜひ一度カジュアルにお話させてもらえると嬉しいです.(僕宛@asteriamにTwitterDM経由でご連絡いただいてもOKです!)