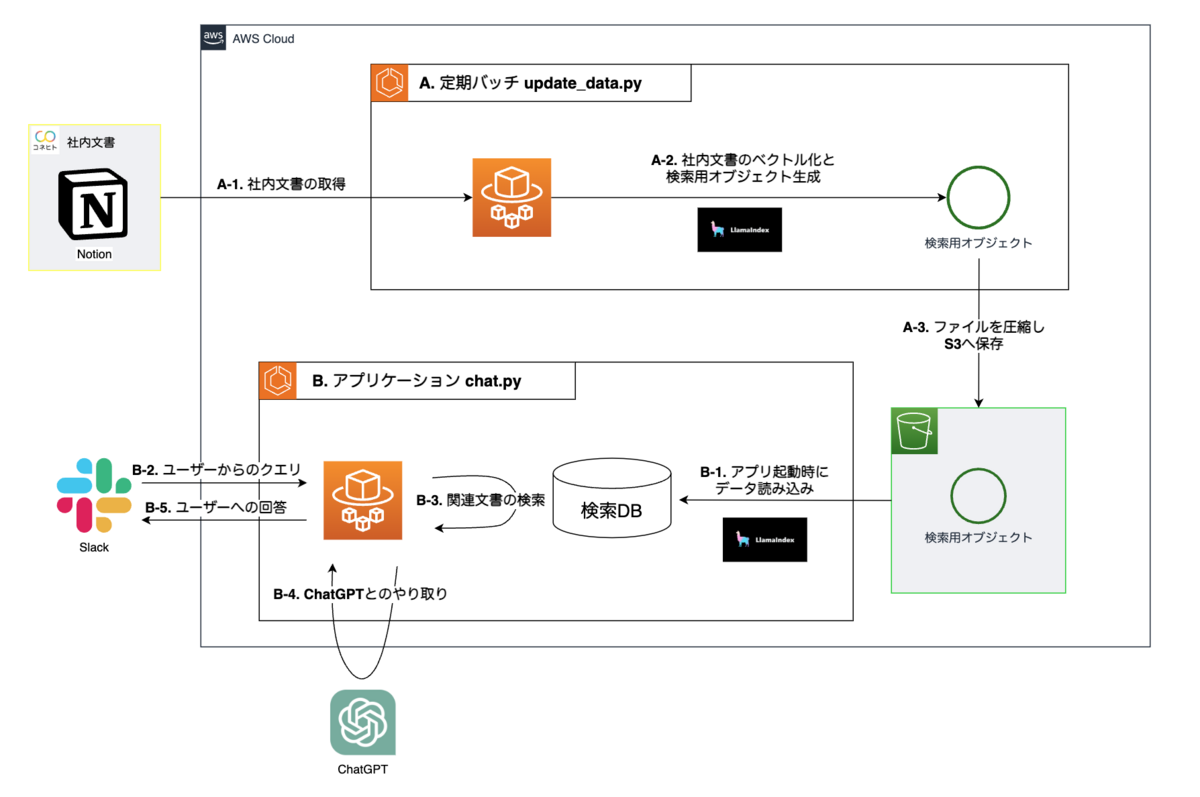
みなさんこんにちは。MLエンジニアのたかぱい(@takapy0210)です。
最近、久しぶりに機動戦士ガンダムSEEDを見直しました。(来年には劇場版の公開もあります)
地球連合軍第7機動艦隊に所属するパイロットであるムウさんの
「君は出来るだけの力を持っているだろう?なら、出来ることをやれよ」
というセリフが好きです。
相手をリスペクトしつつ、でもお前はもっとできるだろ?という期待も込もった、良い言葉だなと感じます。
さて本日は、レコメンドで使用頻度の高い類似アイテムの計算処理を2パターンで実施し、どんな差分がでるのか?を検証した結果をお話ししようと思います。
この記事はコネヒト Advent Calendarのカレンダー 10日目の記事です。
目次
背景
コネヒトの運営するコミュニティサービスママリでは、様々な部分でレコメンデーション機能が提供されています。 今後もレコメンデーションロジックの改善を継続的に行っていく中で、類似するアイテムをどのように計算するのか?は重要な課題の1つです。
類似アイテムを計算する1つのHowとして、昨今話題になっているLLMを使う方法が考えられます。
LLMを用いることで様々なEmbedding(ベクトル)を取得することができ、このベクトルを用いることでアイテム間の類似度を計算することができます。
本記事では以下の2パターンで算出したベクトルを用いて、類似アイテム(ここで言うアイテム=質問)を抽出し、比較・考察してみようと思います。
- Amazon Bedrockの埋め込みモデルで取得したベクトル
- item2vecで計算したベクトル
前半でそれぞれのベクトル取得方法を簡単に説明し、後半では実際にいくつかの質問を用いてどのような類似アイテムが算出できるのか?を見ていこうと思います。
Amazon Bedrockの埋め込みモデルでベクトルを取得する
Amazon Bedrock(以下、Bedrock)とは、テキスト生成AIをはじめとする基盤モデル (Foundation Model) を提供するAWSのサービスです。Bedrockで使用できる基盤モデルには、Amazon自身が開発提供するTitanやAnthropicのテキスト生成AIであるClaudeなどがあります。
以下のようなコードで、Bedrockの埋め込みモデルを使ってテキストのベクトルを取得することができます。
import json import boto3 bedrock_runtime_client = boto3.client('bedrock-runtime', region_name="ap-northeast-1") def get_bedrock_embedding(input_str, bedrock_runtime_client): bedrock_body = { "inputText": input_str } body_bytes = json.dumps(bedrock_body).encode('utf-8') response = bedrock_runtime_client.invoke_model( accept="*/*", body=body_bytes, contentType="application/json", modelId="amazon.titan-embed-text-v1", ) response_body = json.loads(response.get("body").read()) embedding = response_body.get("embedding") return embedding text = "帝王切開で出産、退院時に痛み止めもらった方、いつぐらいまで飲んでましたか?" vec = get_bedrock_embedding(input_str=text, bedrock_runtime_client=bedrock_runtime_client)
今回、Bedrockで取得したEmbeddingはOpenSearchに格納し、その機能を利用して類似質問を抽出しています。 OpenSearchへの格納方法などは、以下のブログに書いていますので、興味のある方はこちらもご覧ください。
item2vecで計算したベクトルを取得する
item2vecとは、自然言語処理におけるword2vecの概念をアイテム推薦などに適用したものです。
word2vecは単語をベクトルとして表現し、これらのベクトルを使って単語間の意味的な関係を捉えることができますが、item2vecでは、この考えを商品や映画、曲などの「アイテム」に適用することができます。*1
今回はママリの質問閲覧ログデータを用いてitem2vecの学習を行いました。学習にはgensimライブラリを用いています。
学習に使用したデータは以下のようなイメージです。
| user_id | question_id | event_dt |
|---|---|---|
| 100 | 19064176 | 2023-10-15 |
| 100 | 19073732 | 2023-10-16 |
| 100 | 19037730 | 2023-10-16 |
| 101 | 18892007 | 2023-10-15 |
| 101 | 18891679 | 2023-10-16 |
| ... | ... | ... |
まずは、このデータをgensimのモデルに入力できるように、系列データに変更していきます。
series_df = pd.DataFrame(df.groupby(['user_id', 'event_dt'])['question_id'].apply(list)).reset_index() series_df = series_df.rename(columns={'question_id': 'order_question'})
こうすることで、以下の様なDataFrameを取得することができます。
| user_id | event_dt | order_question |
|---|---|---|
| 100 | 2023-10-15 | [19084888, 18932714, 18925535 …] |
| 100 | 2023-10-16 | [19060467, 19055834, 19047868 …] |
| 101 | 2023-10-15 | [19096491, 19011148, 19095622 …] |
| 101 | 2023-10-15 | [18921942, 18921942, 18921939 …] |
| ... | ... | ... |
最後にこのデータをgensimに渡し、item2vecモデルの学習を行います。
import multiprocessing from gensim.models import Word2Vec corpus = series_df['order_question'].values.tolist() cpu_count = multiprocessing.cpu_count() model = Word2Vec( corpus, vector_size=50, window=5, hs=1, min_count=1, sg=1, workers=cpu_count, seed=42 )
類似アイテムの抽出は以下の様に行うことができます。
for i in model.wv.most_similar(target_q_id, topn=3): print(f"類似質問ID:{i[0]}, 類似度:{round(i[1], 4)}")
比較検証結果
上記2種類のロジックで取得したベクトルを用いて、どのような類似質問が取得できるのか類似度TOP3を取得して比較します。(今回はコサイン類似度を用いています)
「入力クエリ欄」に記載した質問内容に興味のあるユーザーに対して、どんなものが推薦されるのか?という想定で検証してみます。(Bedrockの場合は入力クエリがテキスト、item2vecの場合入力クエリは質問IDになりますが、ここでは分かりやすいようにテキストで統一して記述します)
※以下で掲示している質問文は一部改変しております
パターン1:ディズニーランドの情報が知りたいユーザー
入力クエリ
ディズニー詳しい方や最近行った方回答お願いします! 10月中旬の平日にディズニーランドへ行くのですが、朝何時から開園並んで何時に入園できましたか? ハロウィンのパレードはプレミアアクセスを購入予定ですが、何時までに入れば買える可能性ありますか?
取得結果
Bedrockの類似アイテムTOP:3
①:10月ディズニーインパについて。 今平日でも入園待ちですごいことになっているみたいですね。10時とかだとスムーズに入園できそうですが、その頃だともうプライオリティパスは取れないですかね?取れても夜の時間とかでしょうか? ハニーハントかモンスターズインクを取る予定です!
②:10/3ディズニー、平日、ハロウィンの情報です!どなたかの参考になれば嬉しいです。6:30ランド到着で一般前から10列目くらいで入場できました。プライオリティパスは入場してすぐで10:10~11:10の回でした!ハモカラ1時間前に地蔵で前から3列目、うちはそのままスプブ待ちでチップ、デール停車位置で前から2列目とれました。
③:皆さんディズニー行く時何時に行きますか?シーもハロウィンだと混むんでしょうか…? 何かYouTubeみて旦那が、7時半には並んだ方がいい!とか言ってますが、子連れでその時間から並ぶって無理あるでしょと思うのですが…笑朝イチじゃないとショーやプライオリティパスもすぐなくなってしまいますか? 来週水曜にディズニーシーに行く予定です。。 全然詳しくないので教えて頂きたいです。
item2vecの類似アイテムTOP:3
①:皆さんの意見を聞かせてください! 何年振りかにディズニーランドに行きます!2歳と4歳の子供を連れていきます! 13日は平日なので多少は空いてる?!チケット料金が安いです。 14日だった場合は親が一緒にこれるので私と旦那の負担が少ない?休日なので混んでる&チケット料金が高いです。 皆さんだったらどちらに行きますか?? 1つ気になるのが13日がシーが早く閉まる?のでランドが混みそうと言う事です。。 ディズニー初心者過ぎて…皆さんの力を貸してください。
②:ここ何年もディズニーに行ってなく、最後に行ったのは10年近く前、、、 その頃は紙のファストパスの時代でしたが今はアプリでとる?んですよね? 5歳3歳1歳の子供連れで久しぶりのディズニーで不安すぎます。 ディズニーランドに行くのですが1日の流れどのようにするのがいいですかね? まったくの無知なのでこうした方がいいよなどあったら教えてほしいです!
③:ここ数日でディズニー行った方教えて下さい! 平日で混んでますか?乗り物の待ち時間どのくらいでしょうか?コロナ禍のガラガラ時以降行ってなくて。。
パターン2:帝王切開後の身体への影響が気になるユーザー
入力クエリ
帝王切開の方にお聞きしたいです。もうすぐ産後1ヶ月になります。骨盤ガタガタで尾てい骨も痛いし足あげるのも痛いし、ゆっくりしか歩けません。みなさんは骨盤ベルトしていましたか?
取得結果
Bedrockの類似アイテムTOP:3
①:臨月になりお尻と足の付け根痛いです。 頭がおりてきていたり、靭帯が緩んだりと原因はいろいろあるみたいですが、これは出産が近いのかな…?? とにかく痛みに対しては骨盤ベルトで抑えてます。 同じように股関節の痛みを感じた方、どの位の期間で出産になりましたか??
②:赤ちゃんがもう産まれても大丈夫な状態らしく、たくさん歩くように言われました。 昨日と今日、いつもより多めに歩いたのですが、先ほどから恥骨がいつもにまして割れるような痛みがきてしまいました。 その前から恥骨は痛かったのですが、歩くのも困難になるほどです。それに加えて、股関節も痛いです。 昨日の検診では赤ちゃん、まだ全然降りてきてないと言われましたが赤ちゃんがおりてきてるんでしょうか?
③:産後50日過ぎましたが、恥骨がまだ痛過ぎます。いつになったら解放されますか? 妊娠後期から恥骨激痛で歩くのやっとで、産んだら解放されるかと思いきや、全然痛い・・・ 骨盤矯正は、先週から行き始めましたが、産後も恥骨痛あった人、いつから無くなりましたか?
item2vecの類似アイテムTOP:3
①:出生後、しばらく哺乳瓶で、その後スムーズに直母授乳に移れますか? 25日の月曜日に帝王切開にて出産しました。 術後の私の回復具合、我が子の体調などなどいろんなことを考慮して、しばらくは哺乳瓶でミルクまたは搾乳した母乳をあたえていくことになり、その方法で1週間近く経ちました。 最初の3日間はミルクを使用、4日目以降搾乳した母乳のみ飲ませています。 同じように、最初は哺乳瓶でその後母乳に移られた方、どうでしたか??特に抵抗なく直母に移れるのもでしょうか?
②:帝王切開で出産、退院時に痛み止めもらった方いつぐらいまで飲んでましたか?
③:出産して入院中なんですが、特に足首から下のむくみがすごく、象の足みたいになってるんですがしばらくはこんな感じなんですかね?
パターン3: ドラム式洗濯機を買うか迷っているユーザー
入力クエリ
縦型洗濯機からドラム式洗濯機に乗り換えた方にお聞きしたいです! 電気代と水道代はどのくらい高くなりましたか? 大体で構わないので教えてください。
取得結果
Bedrockの類似アイテムTOP:3
①:現在、縦型の洗濯機を使っていますが、ドラム式に買い替えることにしました。 明日、電気屋さんに行くのですが、 全く無知なので、おすすめの洗濯機を教えてください! また金額も20万ぐらいかな…と思っているのですが、どのぐらいするのでしょうか?
②:みなさんは洗濯機って縦型使ってますか? それともドラム式洗濯乾燥機ですか? うちは縦型ですが、ドラム式ほしいです。でも高い...
③:洗濯機買って5年経つんですが、縦型で容量が8キロ。 子どもが2人になり洗濯物が増えて、週末は1日に2回まわすこともよくあります。 容量が少ないのがストレスで買い替えたい気持ちもあるのですが、まだ5年だしな〜と迷っています。 もし次買うならドラム式がいいですが高い。。。ドラム式を使われてる方は洗濯後乾燥までされてる方が多いんですかね?縦型、ドラムどちらがおすすめですかね??皆さんどちら使われてるかも教えて欲しいです☺️
item2vecの類似アイテムTOP:3
①:マイホームを購入した時にサービスでつけてもらったオプションや家具家電など参考にさせてもらいたいので教えて下さい
②:コンビニで2,000円の買い物をするのに、 ①楽天カードで支払い ②楽天ペイで支払い(クレカからチャージ) どちらがお得なんでしょうか?
③:年少1人、1歳1人のお子様が居るご家庭の月の食費を教えてください!また旦那さんのお昼ご飯代も込みかどうかも教えて貰えるとありがたいです
パターン4:離乳食の2回食をいつから始めるか気になっているユーザー
入力クエリ
生後5ヶ月半から離乳食を始めました。 2回食にするのは離乳食が始まって2ヶ月後である7ヶ月半くらいかな?と思っていたんですが、6ヶ月の時点で2回食検討中、またはされている話も聞いたりします。 みなさん2回食はいつから始められましたか?
取得結果
Bedrockの類似アイテムTOP:3
①:離乳食についてです。 みなさんいつから2回食に移行しましたか? 5ヶ月から始めてもう1ヶ月と1週間が過ぎました。調べると2回食を始めるのはだいたい7ヶ月からか、始めて1ヶ月経ったらと見ます。 もちろん子どもの様子によって進めていくものだとは思いますが、2回食にするのがすごく気が乗らなくて笑
②:6ヶ月から離乳食を始めた方、いつから2回食にしましたか?5ヶ月で始める時より早めに2回食にした方がいいとかあるんでしょうか、、進め方がよく分からず困っています。
③:5ヶ月から離乳食始めました。 今7週目で(6ヶ月の2週目)いつから2回食を始めるか悩んでます。今日から始めようかな、、と。 みなさん2回目はいつ頃から、何時頃あげてましたか?
item2vecの類似アイテムTOP:3
①:10ヶ月検診で肥満気味と言われました。 男の子で身長73センチの11キロです。離乳食を始めたのが6ヶ月後半からで遅く、量もあまり食べなかったのですが、1ヶ月くらい前から本格的に3回食にして量は小鉢2つ程度です。量は測ったことなかったのですが、 今回測ってみたら25ml+30ml+50mlの冷凍パックしたものを解凍し味噌汁に野菜をプラスしたおかゆとじゃがいもと野菜を潰してコンソメで味付けのポテトサラダで、105g?食べているのかなと思いました。ただ、毎回このくらい食べる時もあれば半分食べたかなくらいで残す時もあります。 本やネットには離乳食の間隔は4時間あけて18時以降は食べさせないと書いてあり、先生には1度に量を食べれなければ間食としてご飯をあげてくださいと言われましたが、その場合はあける時間間隔は無視してもいいのでしょうか。 正直、間食をあげるタイミングもわからないです。 10ヶ月のお子さんがいらっしゃる方は、毎食どのくらい食べているのでしょうか?
②:まだ自分でコップを持って飲めない赤ちゃん、コップ飲みの練習ってどうやりましたか? 現在生後6ヶ月で、生後5ヶ月の頃から離乳食デビューに合わせて麦茶でのコップ飲みを始めました。 ダイソーで売っているトレーニングコップを使用していて、取っ手の部分を握ったりはしますがそのまま自分の口に持っていくのはまだできません。なので私がコップを持って飲ませていますが、麦茶がたくさん口に入るのかむせてしまったりしてイマイチ上手くあげられません。 自分で持って飲んでむせたり溢したりしてだんだんコップに慣れるイメージなのですが、親が飲ませていて練習になるんでしょうか? 1ヶ月続けてもなんの進展もないので不安になってしまいました。 ぜひ教えてください。
③:離乳食をあげてる時間教えてください。 現在生後6ヶ月で5ヶ月の頃から離乳食あげてますがまだ一回食です。 離乳食はモリモリ食べすぎてるくらいなのですが、二回食にするのがめんどくさくて… でもそろそろ二回食を考えなきゃな〜と思ってるので、何時に離乳食をあげているのかみなさんの離乳食スケジュール教えてください。 三回食をもう始めている場合は今後のために三回食の時間も教えて欲しいです。 うちは今10時に離乳食をあげています。 離乳食とミルクはバラバラです。
パターン5:オムツのサイズアップをいつからすれば良いか悩んでいるユーザー
入力クエリ
オムツのサイズアップについてです。 生後1ヶ月で、まだ新生児サイズを使っているのですが、太ももにかなり跡がついています。 ですが、お腹周りはゆるゆるです。 サイズアップした方がいいのかな?と思い、試しに試供品のSサイズを使ってみたら、太ももはぴったりですがお腹の方はオムツがかなり上まで来てゆるゆるです。 このような場合でもサイズアップしたほうがいいのでしょうか?
取得結果
Bedrockの類似アイテムTOP:3
①:オムツの新生児サイズからSサイズへのサイズアップっていつ頃でしたか? また、どんな感じになったらサイズアップした方が良いのか教えて下さい。
②:オムツのサイズについて質問させてください! 生後2ヶ月の男の子がいます。 私の母乳外来受診のため、授乳の様子も見てもらえるということで息子も一緒に受診したのですが、付けているオムツが小さいからサイズアップしたほうがいいと言われました。 体重は約5800gでテープのSサイズを使ってます。 最近ようやく太もも周りがちょうどよくなってきたかなぁと自分的には思ってた矢先助産師さんに小さいと言われたのですが、やはりMサイズへ変えるべきでしょうか?
③:オムツのサイズ別の使用量について。 2400gで生まれ、1ヶ月半新生児用を使用しメリーズファーストプレミアムを5袋使いました。 1ヶ月半となり、4000gになったのでオムツをSサイズにしました! 皆さんはSサイズ、Mサイズ、Lサイズをそれぞれ何ヶ月頃から使用し、何袋使いましたか?? もちろん、赤ちゃんの体型それぞれなのは承知で参考までに。 また、何ヶ月の何キロからSサイズorMサイズからテープオムツをパンツオムツにしましたか??
item2vecの類似アイテムTOP:3
①:生後1ヶ月と半月です。 夜間の授乳が5~6時間くらい初めて空いたのですが、こうやって徐々に夜の時間を延ばしていってもいいんですかね? 最近、日中はずっと起きています。。。早めに昼夜の感覚をつけたいと思ってます!
②:生後1ヶ月 4キロです。 アマゾンセールでおむつを買いたいです。 今使っているものの次のサイズをストックしておくつもりです。 6キロからのMサイズを購入しますがテープタイプとパンツタイプだとどちらが良いのでしょうか?
③:現在生後1ヶ月、まもなく2ヶ月になる息子の育児について相談させてください。ご機嫌に起きている時で、あやすのも授乳も終えている時は皆さんどうされてますか? ご機嫌で1人でおしゃべりしてる時はそのままベッドやハイローチェアで眠るのを待っていても良いのでしょうか?
考察
それぞれのパターンについて簡単にまとめてみます。
| パターン | Bedrock | item2vec |
|---|---|---|
| 1:ディズニーランドの情報が知りたいユーザー | 「プレミアアクセス」や「時間状況」などの単語表現をうまく拾い、類似したアイテムが推薦されている | ディズニーランド全般に関する幅広い情報が推薦されている |
| 2:帝王切開後の身体への影響が気になるユーザー | 骨盤や股関節の痛みといった、身体への影響に関連するアイテムが推薦されている | どちらかと言えば帝王切開に関連したアイテムが推薦されている |
| 3:ドラム式洗濯機を買うか迷っているユーザー | 洗濯機を選ぶ基準やおすすめの洗濯機に関連するアイテムが推薦されており、購入を検討しているユーザーには有用そう | 家庭生活全般(主にお金関連)に関連するアイテムが推薦されている |
| 4:離乳食の2回食をいつから始めるか気になっているユーザー | 離乳食の2回食移行に関連したアイテムが推薦されている | 赤ちゃんの健康管理や飲み物の練習など、子育ての幅広い側面をカバーしたアイテムが推薦されている |
| 5:オムツのサイズアップをいつからすれば良いか悩んでいるユーザー | オムツのサイズに重点を置いたアイテムが推薦されている | パターン4の時と同様に子育ての幅広い側面をカバーしたアイテムが推薦されている |
Bedrockによる推薦は、細かいテキスト内容部分も考慮された類似アイテムが計算できていそうです。(テキストをベクトル化して類似度を計算しているので当たり前と言えば当たり前ですが)
一方でitem2vecによる推薦は、ドンピシャな推薦というよりは、同一トピック内ではあるものの、もう少し幅広いアイテムが計算されていそうです。
おわりに
本記事では、Bedrockとitem2vecを用いて類似アイテムの計算と比較検証を行ってみました。
レコメンデーションには大きく分けて「探索 (Exploration)」と「活用 (Exploitation)」があると言われています。
探索とは、何らかのアルゴリズムによってユーザの嗜好に最も合うであろうアイテムが決定される中で、あえて嗜好に最も合うもの"ではない"アイテムを推薦することを言います。
探索の主な目的は新しい知見を得ることです。これにより、ユーザーの好みや興味の変化に適応することができます。
逆に、現時点で最もユーザの嗜好に合うと計算されたアイテムをそのまま推薦することを活用と言います。
一般的にこの2つはトレードオフの関係になっています。
今回の考察結果から、item2vecの推薦はユーザーの興味トピックとしては近いが、そのトピックの中から幅広いアイテムを抽出しているため、どちらかというと探索向けの推薦として利用できそうだなと感じました。
一方でBedrockによる推薦は、興味を持った具体的なアイテムと似ているものをピンポイントで推薦するため、活用向けの推薦に利用できそうだなと感じました。
今後も推薦の目的や状況に合わせたレコメンデーションロジックの検証・改善を繰り返し、より良いユーザー体験を届けていきたいと思います。