はじめに
はじめまして、8月にコネヒトに入社したy.ikenoueです。
突然ですがみなさん、生成AIは使っておりますでしょうか? ChatGPTやStable Diffusionといった代表的な生成AIの発表から約1年が経過し、そろそろブームも落ち着くかと思っていたのですが、つい先日もOpenAI DevDayにてChatGPTに関する様々なアップデートが発表されるなど、相変わらず目まぐるしい日々が続いていますね。
弊社における生成AIの活用状況はというと、以前に下記の記事にて、Slack上でChatGPTと会話できる環境を社内提供しているという取り組みをご紹介しました。
本日は、上記の社内ツールに新たに追加した「社内文書の参照機能」についてご紹介します。
「社内文書の参照機能」の概要と開発動機
まずは「社内文書の参照機能」の概要と開発にいたった動機についてご説明します。
「社内文書の参照機能」は、その名の通り、ChatGPTが社内に存在する文書を参照したうえで、回答を生成する機能となっております。 というのも、ChatGPTを始めとする大規模言語モデルは、学習時に用いたデータ以外の知識を持っていません。そのため例えば、「経費を精算するにはどういった手順を踏む必要がありますか?」という質問を投げかけたとしても、ChatGPTは一般的な経費精算手順について述べるのみで、特定の企業における正しい経費精算の手順を詳細に回答することは不可能となっています。「社内で発生するQAをChatGPTに回答してもらおう」といった発想はChatGPTを業務で活用するうえで真っ先に思い浮かぶ案の一つかと思いますが、上記の例に代表されるように、質問者が求める情報を正確に提供することができないという場面は非常に多いです。
このような課題に対する解決策として「検索拡張生成 (RAG: Retrieval Augmented Generation)」という技術が知られています。(以降「RAG」と略します。) RAGは、生成AI技術に対して検索技術を掛け合わせることで、本来の生成AIが知り得ない情報に関する回答を可能にする技術です。 ここで、簡素な図を使ってRAGについて説明します。

上記のように、RAGでは、ユーザーが発信したメッセージを生成AIに渡す前に、文書の検索を実行するステップが発生します。(上図②) 検索ステップでは、予め準備された文書の中からユーザーが発信したメッセージと関連性が高い(≒ユーザーが求める回答を生成するために役立つ可能性が高いと考えられる)文書の抽出を試みます。 そして、見つけ出した文書をユーザーが発信したメッセージと一緒に生成AIに与えることで、生成AIが生成する回答の信頼性を高めることができるという仕組みになっています。
この度実装した「社内文書の参照機能」では、以上に述べたRAGの技術を用いて、社内制度やナレッジが書かれた文書の検索とそれらの文書に基づく回答生成を実現しています。 特に今回は、可能な限り低コストで本機能を実現することを重視しており、Azure Cognitive SearchやOpenAIの文章埋め込みモデルといったRAGを実践する際に用いられることの多い有料サービスを使用しない方法を採用しています。低コストで本機能を実現したいと考えている皆さんのお役に立つ内容になっているかと思いますので、参考になれば幸いです。
「社内文書の参照機能」の実現方法
ここからは「社内文書の参照機能」を実現するために用いた具体的な手法について説明していきます。以下は、今回構築したシステムの簡易的な構成図です。
■ 簡易構成図
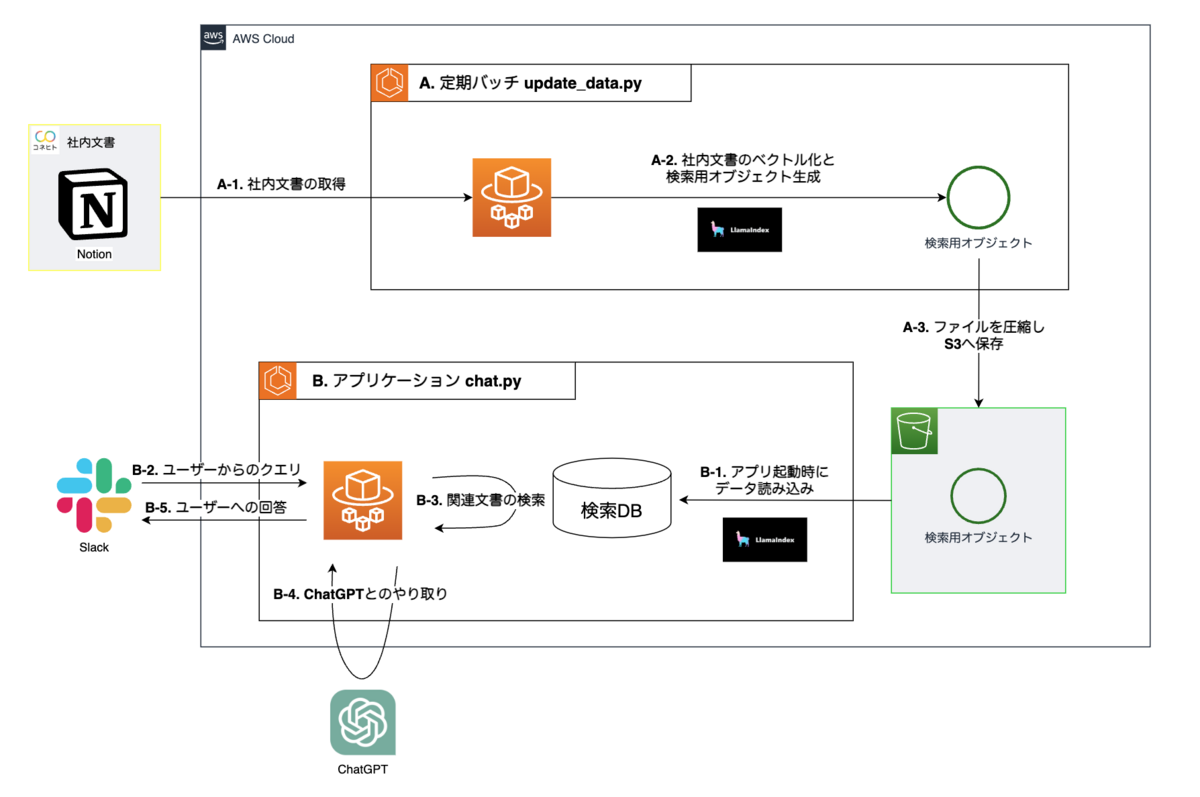
このシステムによって実行される処理は、「A. 定期バッチ」として行うもの(構成図上部)、「アプリケーション」の実行時に行うもの(構成図下部)の2つに大別されます。以降は、これらを分けてご説明します。
「A. 定期バッチ」では、検索を実行するために必要となる社内文書の取得及び検索用インデックスの構築を行います。今回は、検索手法としてベクトル検索を採用しているため、事前準備として文書のベクトル化を行いベクトルインデックスを構築する必要があります。
「B. アプリケーション」には、ユーザーから受け取ったメッセージに基づく関連文書の検索やOpenAIのAPIを通したChatGPTとのやり取り、ユーザーへの回答送信などを実行します。また、アプリケーションの起動時には、「A. 定期バッチ」で作成された検索用のオブジェクトを読み込みます。
当記事では、「社内文書の参照機能」に特有な下記の3つの手順に焦点を当て、それぞれで実行する処理の中身についてご説明します。
「A. 定期バッチ」
- 手順① 社内文書のベクトル化 (構成図A-2に該当)
「B. アプリケーション」
- 手順② ユーザーのメッセージに関連する文書の抽出 (構成図B-1〜B-3に該当)
- 手順③ ChatGPTに与えるプロンプトの構築 (構成図B-4に該当)
手順① 社内文書のベクトル化 (構成図A-2に該当)
手順①では、社内のマニュアルやナレッジが記載された文書をベクトル化する際の処理についてご説明します。これは、手順②の「ユーザーのメッセージによる関連する文書の抽出」においてベクトル検索を行うための事前準備にあたります。
はじめに、文書をベクトル化するためのアルゴリズムとしては、HuggingFaceにて公開されているモデルmultilingual-e5-small を採用しました。2023年11月時点では、文書をベクトル化するためのモデルの主要な候補としてOpenAI製のtext-embedding-ada-002 がありますが、今回は下記の点を考慮してmultilingual-e5-small の採用を決定しました。
- 最初はなるべくコストを掛けずに機能の実現可能性・実用性を検証したい
- ベンチマークにおいて、
multilingual-e5の性能がtext-embedding-ada-002と大差ないことが報告されている。(※)
※ multilingual-e5には、モデルサイズ別にsmall / base / largeの3つのバリエーションがありますが、largeサイズの性能はベンチマークによってtext-embedding-ada-002を上回っています。
以下に、multilingual-e5-smallによるベクトル化を実行するためのコードを記載します。実装には、PythonライブラリのLlamaIndexを用いています。
# 手順①-1. モジュールのインポート import torch from langchain.embeddings import HuggingFaceEmbeddings from llama_index import Document, ServiceContext, StorageContext, VectorStoreIndex, set_global_service_context from llama_index.node_parser import SimpleNodeParser from llama_index.text_splitter import TokenTextSplitter from llama_index.vector_stores import SimpleVectorStore # 手順①-2. 埋め込みモデルに関する設定 EMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu" # 埋め込みモデルの計算を実行する機器 embed_model = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-small", model_kwargs={'device': EMBEDDING_DEVICE}) node_parser = SimpleNodeParser(text_splitter=TokenTextSplitter(separator=" ", chunk_size=512, chunk_overlap=64)) service_context = ServiceContext.from_defaults(embed_model=embed_model, node_parser=node_parser) set_global_service_context(service_context) # 手順①-3. 社内ドキュメントをLlamaIndexのDocument型のデータに変換 llamaindex_documents = [] ## ※ 下記の変数original_documentsは、社内ドキュメントを要素とするリスト型の変数であり、 ## 各要素は社内ドキュメントの「タイトル」「本文」「URL」が格納された辞書型のデータとします。 for document_dict in original_documents: llamaindex_documents.append(Document( text=document_dict["本文"], metadata={ "タイトル": document_dict["タイトル"], "URL": document_dict["URL"], }, excluded_embed_metadata_keys=["url"] )) # 手順①-4. 文書のベクトル化を実行し、文書検索用のオブジェクトを構築 index = VectorStoreIndex.from_documents(llamaindex_documents) # 手順①-5. 構築した検索用のオブジェクトを保存 persist_dir = "./my_storage" index.storage_context.persist(persist_dir=persist_dir)
コードの内容について一部解説します。
手順①-2のブロックでは、ベクトル化を実行する際の設定として「ベクトル化を実行するモデルの種類」「計算デバイス」「テキスト分割方法」を決めています。特に「テキスト分割方法」では、今回使用するモデルmultilingual-e5-small の対応シーケンス長が最大512トークンであることから、各文書をあらかじめ512トークン以下の粒度で分割するよう設定しています。
手順①-3のブロックでは、オリジナルの社内文書をLlamaIndexが求めるデータ型 (Document型)に変換する処理を行っています。特にexcluded_embed_metadata_keys=["url"]の部分では、metadataに指定したデータの内、ベクトル化の対象外とするものを指定することができます。このように、「何らかの用途で後から参照する可能性はあるが、検索の用途では意味をなさないためベクトル化の対象からは外したい」といったデータは、ベクトル化の対象から除外することをおすすめします。
手順①-4のブロックでは、ベクトルインデックスを中心とする検索用のオブジェクトを生成します。 文書のベクトル化処理もこのセクションで実行しているので、元の文書量が膨大な場合は処理にそこそこの時間を必要とします。(参考までに、弊社の全文書に対してm2チップを搭載したノートPCで処理を実行した場合、約3時間ほどの時間を要しました。)
手順② ユーザーのメッセージに関連する文書の抽出 (構成図B-1〜B-3に該当)
ここからは、ChatGPTとやり取りを行うアプリケーションの動作時に実行する処理となります。手順②では、ユーザーから受け取ったメッセージと関連性が高い社内文書を見つけ出す処理についてご説明します。
## 〜 コードが重複するため省略 〜 ## 手順①-1及び2の「埋め込みの設定」処理をここで実行 ## 〜 コードが重複するため省略 〜 # 手順②-1. モジュールのインストール from llama_index import load_index_from_storage from llama_index.retrievers import VectorIndexRetriever # 手順②-2. 手順①で構築した検索用オブジェクトのロード persist_dir = "./my_storage" storage_context = StorageContext.from_defaults(persist_dir=persist_dir) loaded_index = load_index_from_storage(storage_context) # 手順②-3. ベクトル検索を行い、関連性の高い上位5つの文書を抽出 retriever = VectorIndexRetriever(index=loaded_index, similarity_top_k=5) ## ※ 下記の変数user_messageには、ユーザが入力した文字列が格納されているものとします retrieved_text_list = retriever.retrieve(user_message)
手順②-2では、手順①で保存したデータを読み込むことで、検索用のオブジェクトをメモリ上に展開しています。
手順②-3では、ベクトル検索を行うことで、ユーザーから受け取ったメッセージと関連性が高い社内文書を見つけ出す処理を行います。注意点として、retriever.retrieve(user_message)の部分では、ユーザから受け取ったテキストに対するベクトル化処理を行っています。ここで使用するモデルは、手順①で社内文書をベクトル化した際と同じモデルである必要があります。
手順③ ChatGPTに与えるプロンプトの構築 (構成図B-4に該当)
最後に、手順②で抽出した文章をユーザーから受け取ったメッセージに追加することで、ChatGPTに与えるプロンプトを作成します。
まずはコードを記載します。
# 手順③-1. 手順②で抽出したドキュメントをユーザーから受け取ったメッセージの末尾に追加 reference_documents = "" for retrieved_text in retrieved_text_list: # 検索にヒットした社内ドキュメントの内容及びタイトルを取得 document_content = retrieved_text.node.text document_title = retrieved_text.node.metadata["タイトル"] reference_documents += f"\n## 文書「{document_title}」\n{document_content}\n" # ユーザーのメッセージに、関連文書を追加 user_message += f"\n\nただし、下記の文書を参考にして回答してください。\n{reference_documents}"
上記の処理を実行することで、ChatGPTに与えるプロンプトは以下のような文字列になります。
{ユーザーから受け取ったオリジナルのメッセージ}
ただし、下記の文書を参考にして回答してください。
## 文書「{文書1のタイトル}」
{文書1の本文}
## 文書「{文書2のタイトル}」
{文書2の本文}
## 文書「{文書3のタイトル}」
{文書3の本文}
## 文書「{文書4のタイトル}」
{文書4の本文}
## 文書「{文書5のタイトル}」
{文書5の本文}
このように、ユーザーのメッセージに加えてそれに関連する社内文書を渡すことで、ChatGPTが社内独自のマニュアル・ナレッジに基づいた回答を生成することが可能となります。
「社内文書の参照機能」の使用例
それでは、今回の機能搭載によりChatGPTの回答に具体的にどのような変化が生じるようになったのか、実際の例をお見せします。
以下では「社員が書籍購入補助制度の有無について尋ねる」という場面を想定し、
- before: オリジナルのChatGPTをそのまま使用した場合
- after: 「社内文書の参照機能」を使用した場合
として、それぞれの回答例を比較しています。
before: オリジナルのChatGPTをそのまま使用した場合
まずは、「社内文書の参照機能」を使用しない場合の回答結果です。

そもそも「コネヒト(弊社)の制度について知りたい」という意図をChatGPTに伝えていないため、ChatGPTの回答は一般的な書籍購入補助制度について述べるにとどまっています。また、弊社の書籍購入補助制度の詳細は外部に公開されているものでもないため、その点でもオリジナルのChatGPTに正確な回答を期待することはできない質問となっています。
after: 「社内文書の参照機能」を使用した場合
続いて、今回新たに搭載した「社内文書の参照機能」を使用した場合の回答例です。(社外に公開していない情報を含んでいるため、マスクしている箇所があります。)
※ 下記のユーザーメッセージ内に含まれる「コネヒト」という文字列は今回搭載した機能を動かすためのトリガーの役割を果たすのみで、ChatGPTに送信するメッセージからは除外する処理をアプリ側で行っています。

回答内で言及されている”スキルアップ支援制度”は弊社の書籍購入補助制度の名称です。弊社固有の名称を用いて制度に関する具体的な説明が行われていることから、実際の文書の内容に基づく回答が生成されていることがわかります。(弊社ではドキュメントの管理にNotionを使用しているため、ChatGPTの回答の末尾にNotionページへのリンクを追記することで、回答のソースとなった文書にアクセスできるような導線を引いています。)
おわりに
以上、当記事ではChatGPTに社内文書を参照させたうえで正確な回答を生成させる機能の実現例をご紹介しました。
この機能は社内でリリースしてから約2ヶ月が経過するのですが、嬉しいことに「新入社員のオンボーディングに使いたい」や「社内制度に関するQA一次対応に使いたい」など、具体的なケースでの活用を希望する声があがっています。
弊社では、今後もベクトル検索や生成AIといった技術を積極的に活用することで社内の業務効率化やプロダクトの提供価値向上に挑戦していきます。その際は、得られた知見を同様に記事化してご紹介しますので、引き続き当ブログに注目いただけると幸いです!