皆さん,こんにちは!MLエンジニアの柏木(@asteriam)です.
今回は前回のエントリーに続いてその後編,パイプライン構築の話になります. tech.connehito.com
はじめに
再掲になりますが,我々は以下の構成で今回の検索基盤を構築しています.
- 検索エンジン:Amazon OpenSearch Service
- データベース:Amazon Aurora
- データ同期(ETL):AWS Glue
- ワークフロー・パイプライン:AWS Step Functions・Lambda・EventBridge
後編は,検索エンジンに定期的に安定してデータを同期するために構築しているワークフロー・パイプラインに関する内容になります(下図の全量データ同期パイプラインの部分).
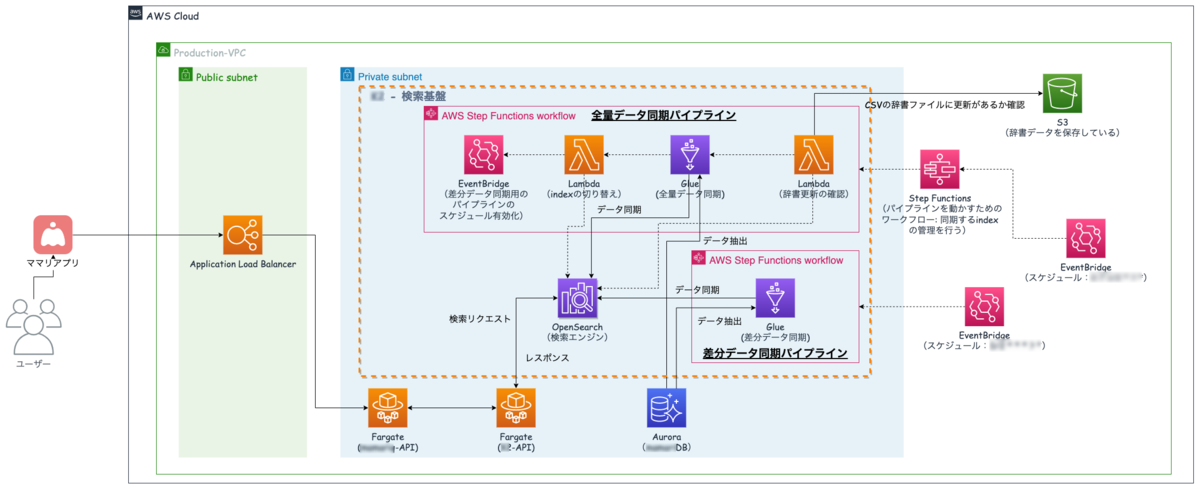
もう少し具体的には,OpenSearchのindexの管理方法について説明した後に,パイプラインの話とパイプラインのコード管理の方法の順番で紹介していきたいと思います.
目次
OpenSearchのindex管理
我々は2つのindexを用意し,その上段にaliasを置く方法でOpenSearchのindexを管理しています.aliasを置く理由としては,以下の理由が一番大きいです.
- アプリケーション側で接続先を毎回変更する必要がない
また,接続先の変更ミスなどが発生すると適切なドキュメントにアクセスできなくなるといったこともあり,アプリケーション側からは常に同じ接続先にすることで上記問題を気にせずにリクエストを検索エンジンに投げることができます.

indexに入るデータはGlueから同期されるようになっており,後述するパイプラインを用いてデータが安全に入る仕組みを構築しています.
一方で,我々はOpenSearchのReindex APIを使ってindexの作り替えをしているのではなく,全量データを数日(サービス仕様のためボカしています)に1回洗い替え作業を実施し,indexを一度削除してから新規で作り替えを行っています.そのタイミングで,裏側でaliasを切り替えている状況になります.
なぜindexの作り替えを毎回実施しているのか
数日に1回全量データの洗い替え作業を実施しており,このタイミングでindexの作り替えを行っています.洗い替え作業を行う理由としては,
- データの漏れや欠損が発生していた場合にそれらを洗い替え時に拾うことができるため
この処理はデータの取りこぼしがあった時の保険的な役割が大きいです.そのため,Reindex APIは既存のindexのコピーになるので,それだけだと不十分で毎回indexを作り替えることをしています.
indexの切り替えフローの紹介
洗い替え時のindexの切り替えフローを紹介しようと思います.流れとしては下図のようになっています.
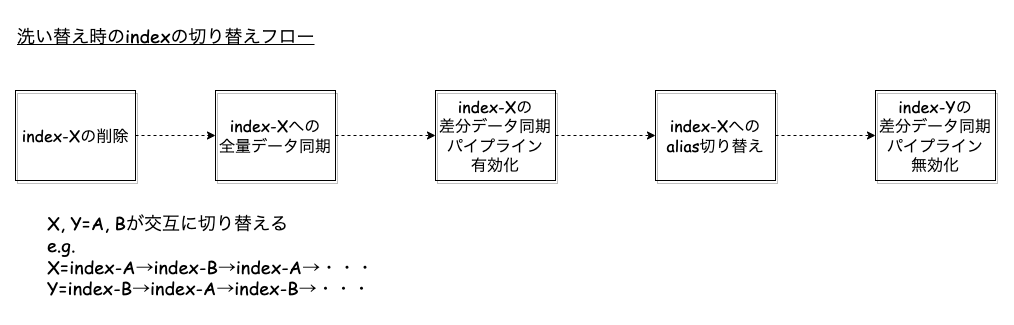
今,indexAとindexBの2つがあるとして,aliasはindexBを向いている(alias→indexB)とします.差分データの更新がindexBで続いており,indexAはスタンバイ状態になります.
まず,indexAの削除をした後,AWS Glueによる全量データの同期をindexAに対して行います.これによりindexAに最新のデータが入った状態になります.その後aliasの向き先をindexBからindexAに変更します(alias→indexA).これで取りこぼしがあった場合でも,補完することができ,データをindex化することができます.あとは次回洗い替え時にAとBが入れ替わった形でまた処理が実行されます(indexAとBで交互にループしている状態).
これらの処理をStep Functionsのパイプライン上で実現して日々実行されています.
ワークフローとパイプラインの役割
では,実際にパイプラインの処理はどんな感じになっているかを紹介していきます.
今回,ワークフローとパイプラインというように分けていますが,それぞれの役割をまずは説明します.ちなみにこれらはどちらもStep Functionsを用いて構築しています.
- ワークフロー
- 2つのindexに対応したパイプラインがあり,そのどちらを使用するかを制御する
- EventBridgeによるスケジュール実行の対象となり動作する

- パイプライン
- 上図にあるStep Functionsの実体で,辞書更新とデータ同期の処理を行う

なぜワークフローとパイプラインで分けたのか?
なぜこの2つに分けたのかを説明していくと,問題点と解決策は以下のようになりました.
- 問題点:数日に1回のスケジュール設定をEventBridgeで行えなかった
- 開発当初は2つindexに対して用意したパイプラインに対して,それぞれスケジュールを割り当てて実行しようとしていたのですが,数日に1回のスケジュール設定を上手くそれぞれのindexのパイプラインが交互に実行するのができないことがわかった
- 月によって31日がなかったりなどの影響があり
- 開発当初は2つindexに対して用意したパイプラインに対して,それぞれスケジュールを割り当てて実行しようとしていたのですが,数日に1回のスケジュール設定を上手くそれぞれのindexのパイプラインが交互に実行するのができないことがわかった
- 解決策:それぞれのパイプラインを管理するワークフロー的な役割を用意
- 2つのパイプラインを制御する役割として,上段にワークフロー的な役割をするStep Functionsを用意することで,上手くこの問題を回避した
- EventBridgeによるスケジュール設定をこのワークフローに割り当て,現在どのindexに対してaliasが接続しているかをチェックすることで,その後にどちらのパイプラインを流せば良いかを判断している存在とした
この結果,管理するEventBridgeも1つになったのと,ワークフローを確認することでどちらのパイプラインに処理が流れたかを一目で確認することができるようになりました.
全量データ同期パイプラインの詳細
次にパイプラインの詳細を見ていこうと思います.このパイプラインの中には大きく2つの処理パートがあります.
- 辞書更新パート
- データ同期パート

辞書更新への対応
パイプラインの最初の処理に辞書更新の有無を判断しているステップがあります.これはS3に置いてある辞書ファイルが直近で更新があったかをチェックし,更新があればこの辞書更新のパートに処理が進んでいきます.無ければこの処理はスキップされます.
辞書更新のフローを別に切り出すことも可能でしたが,少ない数のパイプラインで管理したいのと,運用を考えた場合に,意識せず上段のワークフローを再実行することで辞書更新も取り込んだ形でindexの更新が行えるのがベストだと思ったのもあり,メインのパイプラインの中に組み込んだ形を取っています.
辞書更新のパートでは,「ユーザー辞書」や「同義語辞書」の更新を行える処理になっています.これらの辞書を更新するためには,OpenSearchの更新を行う必要があり,更新された辞書情報はindexの作り替え時に適用されることになります.
OpenSearchの更新をするためには,パッケージの更新とその関連付けの処理を行う必要があり,こちらの公式ドキュメントが一部参考になるかと思います.
上記処理はStep Functionsのアクションに登録されているので,それらを用いて処理を組み立てています.
OpenSearchのindexの切り替え方法
先述した「indexの切り替えフローの紹介」の章で説明した内容をデータ同期パートでStep Functionsのフローに落とし込んでいます.
OpenSearchへはLambdaを用いてAPIを叩いてindexのdeleteやaliasの切り替えを行っています.
ここでのindexの切り替えステップは,検索システム-実務者のための開発改善ガイドブックの「8.5.1 インデクサの更新」の章でも書かれているように,Blue/Greenデプロイの形になっていて,新しいindexへのデータ投入が完了した後に,aliasの向き先を古いindexから新しいものに変更することで安全にデプロイをしています.その際に,新しいindexへの差分データ同期のパイプラインを有効化,古いindexへの同期処理は無効化することでパイプラインの完全な切り替えが完了します.
データパイプラインのコード管理
最後に,これらの複数のパイプラインをコード管理する方法ですが,AWS SAMによるパイプラインのコード管理を行っています.
AWS SAMとは,AWS Serverless Application Model (AWS SAM) といい,サーバレスなAWSリソースを管理するツールになります.サーバレスに特化したCloudFormationを拡張したものと言え,今回使用したLambda・Glue・Step Functionsなどのリソースは全てコード管理することができます.
ディレクトリ構成は以下のような感じになります.
.
├── README.md
└── sam
├── env
│ ├── dev
│ │ ├── samconfig.toml
│ │ └── template.yaml
│ └── prd
│ ├── samconfig.toml
│ └── template.yaml
├── functions/(Lambdaの定義)
├── glue
│ ├── dev/(GlueJobの定義)
│ └── prd/(GlueJobの定義)
└── statemachine/(StepFunctionsの定義)
- Step FunctionsとLambdaは共通化し,Glue Jobはdev/prdで個別にスクリプトを用意し,環境差分はtemplate.yamlの定数で定義
- 共通変数はtemplate.yamlのParametersに記載
コード管理することで,いくつか利点があります.
- 設定した内容を別環境に簡単に適用することができる
- コードレビューが可能になり,設定ミスや漏れなどに気づきやすい
- 環境依存部分をパラメータ化することで,テンプレートファイルで簡単に管理・切り替えが可能
ABテストを実施する際など,同一の環境をもう1セット用意する必要がある場合でもコード管理しておくこと,コマンド一発で環境を用意できるので,コード管理の恩恵を多分に受けています.
細かい設定ファイルの中身についてはここでは記載しないですが,今度登壇させて頂くJAWS DAYS 2022(2022-10-08 (土))でもう少し説明しようと思っていますので,気になる方はこちらのイベントを確認して貰えると嬉しいです!(資料は公開予定ですので,そちらでも可能です)
おわりに
今回構築したパイプラインは再実行を行いたい場合でも,input情報の設定をすること無く実施できるので,属人性もなく,indexの向き先なども気にせずに実行できるので運用がかなり楽になった仕組みだと感じています.
また,パイプラインもコード管理しておくことでチーム内の他のメンバーが環境構築する際にも簡単に実行できたり,スクラップ&ビルドも容易だったりして整理しておくと色々と恩恵があるなと感じています.
今後もより安心安全で信頼性が高いパイプライン構築のために,改善できる部分はよりブラッシュアップしていこうと思っています.
再掲になりますが,JAWS DAYS 2022でも今回のテックブログの内容を紹介する予定になっていますので,是非興味がある方はイベント登録(無料)して頂いて見て貰えると嬉しいです.
- 登壇時間:2022-10-08(土)14:20~15:00
- タイトル:AWSのマネージドサービスで実現するニアリアルタイムな検索基盤
最後に,コネヒトではプロダクトを成長させたいMLエンジニアを募集しています!!(切実に募集しています!)
もっと話を聞いてみたい方や,少しでも興味を持たれた方は,ぜひ一度カジュアルにお話させてもらえると嬉しいです.(僕宛@asteriamにTwitterDM経由でご連絡いただいてもOKです!)