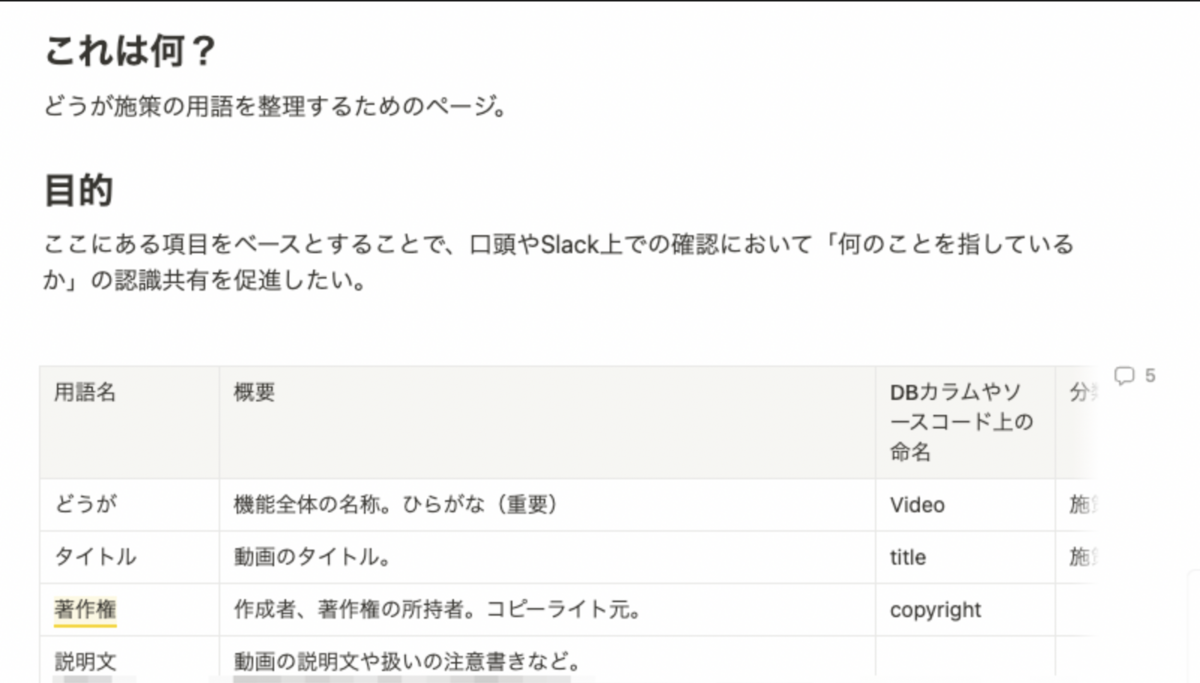
※ この記事は、AWS (Amazon Web Services) の技術支援を受けて執筆しています。
はじめに
この記事はコネヒトアドベントカレンダー 8日目の記事です。
コネヒト Advent Calendar 2023って?
コネヒトのエンジニアやデザイナーやPdMがお送りするアドベント カレンダーです。
コネヒトは「家族像」というテーマを取りまく様々な課題の解決を 目指す会社で、
ママの一歩を支えるアプリ「ママリ」などを 運営しています。
adventar.org
こんにちは!コネヒトの機械学習エンジニア y.ikenoueです。
突然ですがみなさん、Amazon Bedrockをご存知でしょうか。
aws.amazon.com
Amazon Bedrock(以下、Bedrock)は、テキスト生成AIをはじめとする基盤モデル (Foundation Model)*1を提供するAWSのサービスです。単に基盤モデルを呼び出して出力結果を得るだけにとどまらず、ファインチューニングやナレッジベースの構築によるRAG(検索拡張生成, Retrieval Augmented Generation)*2の実現など、基盤モデルに関する様々な操作を統一的なAPIから利用することができます。Bedrockで使用できる基盤モデルには、Amazon自身が開発提供するTitanの他、Anthropicのテキスト生成AIであるClaude、Stability AIの画像生成AIであるStable Diffusionなど、多様な用途をカバーしたモデルが含まれます。
さらに、Bedrockが提供する基盤モデルの中には埋め込みモデル*3がラインナップされています。埋め込みモデルは、画像や自然言語といったデータを特定の次元のベクトルに変換するためのモデルです。埋め込みモデルによって生み出されたベクトルは元のデータの特徴を反映したものとなり、「機械学習モデルに入力する特徴量として用いる」「ベクトル同士の類似性を計算することで検索やレコメンデーション用途に使う」といった活用が考えられます。
そこで本日は、Bedrockの埋め込みモデルを用いたテキストのベクトル化を実践します。さらに、埋め込みモデルによって生成されたベクトルの活用例として「ベクトル検索」*4システムのプロトタイピングを行います。具体的には、Bedrock埋め込みモデルによって生成されたベクトルデータによるベクトル検索の実行結果と従来の全文検索*5の実行結果を比較することで、埋め込みモデルの性能やベクトル検索の特徴に関する理解を深めることを目的とします。
※ 「手っ取り早くベクトル検索と全文検索の比較結果を見たい!」という方は、こちらからお読みください!
※ 当ブログでは、過去にも埋め込みモデルや検索システムに関する記事を公開しています。興味のある方は、下記のリンクからご覧ください。
tech.connehito.com
tech.connehito.com
tech.connehito.com
プロトタイピングの動機
まずは、今回のプロトタイピングを行うに至った動機についてご説明します。
弊社コネヒトでは、母親向けのQ&Aを主なコンテンツとするママリというコミュニティサービスを運営しています。
ママリには毎月十万件以上の質問が新たに投稿されており、これらの大量の質問データの中からユーザーが求めるものを見つけ出すための検索システムは、AWSのOpenSearch Serviceを用いて自社で構築しています。*6現在の検索システムでは、単語の出現頻度に基づく検索アルゴリズムである全文検索をベースとした手法を採用しているのですが、ここにクエリと文書の意味的な類似性に基づく検索を可能とするベクトル検索技術を取り入れることで、ユーザーの検索体験の改善につなげたいという狙いがあります。
またママリでは、質問のレコメンデーション*7や検閲を行う機械学習モデル*8を運用しています。埋め込みモデルによって獲得したベクトルをこれらのモデルの特徴量として活用することで、モデルの精度向上が期待できるのではないかという仮説をもっています。
このように、ママリにおいて埋め込みモデルの活用範囲は非常に広いと考えています。
さらに、弊社ではインフラにAWSを採用しているため、AWS上の他のサービスとの連携を考慮するとBedrockは有力な選択肢となります。
以上のような背景から、まずはBedrockの埋め込みモデルの性能や使い勝手を確認するための検証第一弾として、今回のプロトタイピングを実施することになりました。
プロトタイピングの概要
続いて、今回のプロトタイピングの概要についてご説明します。
繰り返しになりますが、この記事ではベクトル検索と全文検索を行った際に、両者の検索結果にどのような違いが生じるのかを比較することで、両者の検索手法の強み・弱みを可能な限り明らかにしていきます。
この際、ベクトル検索を実行するために必要なベクトルデータは、Bedrockの埋め込みモデルによって生成します。ベクトル検索の実行結果の妥当性を通して、埋め込みモデルの性能に対する理解も同時に深めていきます。
埋め込み及び検索の対象となるデータにはママリの実データを使用します。具体的には、2023年10月に投稿された十万件以上の質問文を対象とします。
以降は、プロトタイピングの手順を以下3ステップに分け、順番にご説明します。
- ステップ① Bedrockの埋め込みモデルによるベクトルの生成
- Bedrockの埋め込みモデルを用いて、ママリの質問データ(2023年10月文)をベクトル化します。
- ステップ② OpenSearch Serviceによる検索システムの構築
- ママリの質問文及びステップ①で生成したベクトルデータをAWSのOpenSearch Serviceのマネージド型ドメインに格納することで検索システムを構築します。
- ステップ③ 「全文検索」と「ベクトル検索」の実行と検索結果の比較
- ステップ②で構築した検索システムを用いて、ママリの質問文に対する「全文検索」と「ベクトル検索」を実行します。そして、両者の検索結果にどのような違いが生じるのかを定性的に比較します。

ステップ① Bedrockの埋め込みモデルによるベクトルの生成
最初のステップとして、Bedrockの埋め込みモデルを用いたテキストのベクトル化を行います。
まずは、埋め込みモデルの選定基準についてご説明します。
2023年12月8日現在、Bedrockにはテキストデータを対象とした埋め込みモデルとして下記3種類が提供されています。
※ マルチモーダルモデルであるTitan Multimodal Embeddings G1は比較の対象外としています。
3つのモデルのうち、「Embed English」(Cohere)は対応言語が英語のみとなっていることから、日本語データを対象とする今回のプロトタイピングでは選択肢から外れました。
残った2つのモデルに関しては、主にコンテキスト長の差を重視し「Titan Embeddings G1 - Text」(Amazon)を選択しました。コンテキスト長は、埋め込みモデルが入力として考慮することのできる最大のトークン数を指します。「Embed Multilingual」(Cohere)のコンテキスト長は512までとなっていますが、ママリの質問データにはこれを超えるものが存在することから、コンテキスト長が最大8000トークンまでと余裕のある「Titan Embeddings G1 - Text」 (Amazon)が適しているという判断になります。
次に、BedrockのAPIを呼び出し、テキストをベクトル表現に変換するためのコードをご紹介します。
プログラミング言語には、Pythonを使用しています。
import json
import boto3
bedrock_runtime_client = boto3.client('bedrock-runtime', region_name="ap-northeast-1")
def bedrock_embedding(input_str):
bedrock_body = {
"inputText": input_str
}
body_bytes = json.dumps(bedrock_body).encode('utf-8')
response = bedrock_runtime_client.invoke_model(
accept="*/*",
body=body_bytes,
contentType="application/json",
modelId="amazon.titan-embed-text-v1",
)
return json.loads(response.get("body").read()).get("embedding")
コードの要点を取り上げて解説します。
はじめに、Bedrockのモデルを呼び出す際は、bedrock-runtimeに接続したclientが持つinvoke_model()というメソッドを使用します。このメソッドには、モデルの入力とするテキストをキー"inputText"に対応する値として設定したJSON形式のデータを渡す必要があります。
使用するモデルの種類は、引数modelIdに与えます。先述の通り、今回のプロトタイプでは「Titan Embeddings G1 - Text」(Amazon)を使用するため、このモデルのIDに該当する"amazon.titan-embed-text-v1"を指定しています。
なお、モデル名とIDの正式な対応関係は下記のコードで出力されるモデル一覧から知ることができます。
bedrock = boto3.client(service_name='bedrock')
print(bedrock.list_foundation_models())
invoke_model()メソッドのレスポンスには"embedding"という要素が含まれており、これがテキストの埋め込み結果に該当するベクトルデータです。ちなみに、このレスポンスには"embedding"の他に、元のテキストのトークン長が格納された"inputTextTokenCount"が含まれているため、この値を参照することで埋め込みモデルの利用にかかったコストを個別のデータ単位で正確に把握することができます。
ステップ② OpenSearch Serviceによる検索システムの構築
続いて、AWSのOpenSearch Serviceを用いた検索システムの構築についてご説明します。
このステップでは、特にベクトル検索を実行するためのインデックスの構築方法に焦点を当てています。
なお、このステップのプログラムを実行するには、事前にOpenSearch Serviceのドメインを構築しておく必要がありますが、分量が非常に長くなるためこの記事では説明の対象外とします。ドメインの構築方法については、代わりに下記の公式ドキュメントを御覧ください。
以下は、全文検索とベクトル検索の両者に対応したインデックスを作成するためのPythonコードです。実装にはopensearch-pyというライブラリを用いています。
from opensearchpy import OpenSearch, RequestsHttpConnection
from opensearchpy.helpers import bulk
from requests_aws4auth import AWS4Auth
region = 'ap-northeast-1'
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
host = 'XXX.ap-northeast-1.es.amazonaws.com'
port = 443
client = OpenSearch(
hosts = [{'host': host, 'port': port}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection,
timeout=1000
)
def add_documents_to_index(client, index_name, document_dict):
actions = []
for i, document_id in enumerate(document_dict):
actions.append({
"_op_type": "index",
"_index": index_name,
"_id": document_id,
"_source": {
"document": document_dict[document_id]["document"],
"embedding": document_dict[document_id]["embedding"]
}
})
if i % 100 == 0:
bulk(client, actions)
actions = []
else:
bulk(client, actions)
上記のコードでは、”document”フィールドにオリジナルのテキストデータ、”embedding”フィールドにテキストの埋め込み表現を追加しており、それぞれのフィールドを全文検索、ベクトル検索の実行時に使用します。
また、データの登録時には関数bulkを用いて複数件のデータを一度にまとめて登録することで、処理にかかる時間を削減しています。一方で、あまりに多くのデータを一度に転送しようとするとbulkの実行時にエラーが発生することがあるため、ここではデータを100件ごとに区切って処理を実行しています。(一度に登録できるデータ件数の上限は一つのデータあたりの容量などに依存します。)
ステップ③ 「全文検索」と「ベクトル検索」の実行と検索結果の比較
最後に、構築したシステムを用いて検索を実行します。
以下は、全文検索、ベクトル検索を実行するためのPythonコードです。
def search(query_str, search_type, size=5):
if search_type == "vector":
vec, _ = bedrock_embedding(query_str, bedrock_runtime_client)
query = {
"size": size,
"query": {
"knn": {
"embedding": {
"vector": vec,
"k": 10
}
}
}
}
else:
query = {
"size": size,
"query": {
"match": {
"document": query_str
}
}
}
results = client.search(index=index_name, body=query)
return results
関数searchでは、引数search_typeに”vector”を指定した場合はベクトル検索、それ以外の場合は全文検索用のDSL (ドメイン固有言語: Domain Specific Language) を用いるように条件分岐を行っています。
またベクトル検索を行うには、事前に検索クエリの埋め込み表現を獲得する必要があります。そこで、ステップ①で掲載した関数bedrock_embeddingを使ってテキストデータをベクトルに変換する処理を実行しています。
それでは、いよいよ準備が整ったので、全文検索とベクトル検索の検索結果を比較していきましょう。
今回の比較検証では、以下5つのケースを取り上げてそれぞれの検索結果に対する考察を行います。
- ケース1. クエリが一つの単語で構成される場合
- ケース2. クエリが複数の単語で構成される場合
- ケース3. クエリに固有名詞を含む場合
- ケース4. クエリに誤字を含む場合
- ケース5. クエリに文章を使用した場合
検索クエリ: 保育園
まずは、検索クエリが一つの単語で構成される場合の例を見ていきます。以下は、保育園を検索クエリとして用いた場合の検索結果です。
| 検索ランキング |
全文検索 |
ベクトル検索 |
| 1 |
【愛知県瀬戸市の保育園について】瀬戸市の保育園について教えてください (...以下略...) |
保育園ってどのくらい前から探すものですか?? |
| 2 |
親の都合で保育園を8月いっぱいで退園させてしまいました (...以下略...) |
八幡西区でベビーカー置き場のある保育園はありますか? |
| 3 |
千葉県香取市の保育園についてまんまる保育園、香西保育園、たまつくり保育園どんな感じか (...以下略...) |
滋賀県愛荘町にお住まいの方!保育園の応募なんですが、この辺り出身ではないので (...以下略...) |
| 4 |
【通勤途中の保育園と家の近くの保育園、どちらに預けるべきかについて】モヤモヤしてます (...以下略...) |
山形市内から天童市内周辺まででおすすめの保育園はありますか?0歳児クラスがあるところ (...以下略...) |
| 5 |
保育園についてです。今生後7ヶ月の娘が保育園に通っているのですが、3回食にならないと保育 (...以下略...) |
通園て何が必要ですか?保育園です。 |
※ 質問文の全体を掲載すると文章が長くなりすぎてしまう場合があるため、質問文の意味や検索クエリとの関連性が正しく伝わる程度に一部の情報を省略して掲載しています。
両者ともに上位五件の検索結果には保育園という単語が含まれており、正常に検索が行われていると言えそうです。保育園という単語だけではユーザーがどういう情報を求めているのかを判断することが難しいため、検索結果の良し悪しについては、今回のケースではこれ以上の評価することができません。
そのうえで両者の検索結果の違いに着目すると、以下のような傾向が見受けられます。
- 全文検索では、質問内に
保育園というワードが複数個含まれている質問が上位に並んでいる
- ベクトル検索では、
保育園というワードを含みつつも、質問の全体の文章量が少ない質問が上位に並んでいる
全文検索では、クエリと文書の一致度を計算する際に、クエリと文書の単語の出現頻度を考慮しているため、クエリと文書の単語の出現頻度が高いほど検索結果の上位に位置づけられる傾向があるためこういった結果が生まれたと推察できます。
一方、ベクトル検索では、単語の出現頻度ではなくクエリと文書の意味的な類似性に基づき検索スコアが計算されます。今回のケースでは、クエリが保育園という一単語のみで構成されているため、文章が長くなるほど(保育園以外の情報が加わるほど)、保育園からは意味が離れていく作用が働いていると考えられます。
ケース2. クエリが複数の単語で構成される場合
検索クエリ: 保育園 お弁当
続いて、クエリ内に複数の単語が含まれる場合を比較しましょう。以下は、ケース1の保育園に一単語を追加した保育園 お弁当を検索クエリとして用いた場合の検索結果です。
| 検索ランキング |
全文検索 |
ベクトル検索 |
| 1 |
年少さんのお弁当の量ってどんなかんじですか?保育園で初めてお弁当あり (...以下略...) |
保育園の園外保育で給食の方、お弁当はどうされていますか? |
| 2 |
19日に保育園のお弁当の日があります。お弁当のおかずについてです。 (...以下略...) |
幼稚園 お弁当オススメおかずありますか? |
| 3 |
保育園の行事でお弁当を持たせる時 普段給食なのでお弁当は作らないので (...以下略...) |
保育園の遠足のお弁当。ほんっと下手くそで泣きそうです (...以下略...) |
| 4 |
年長 遠足のお弁当 今度、保育園の遠足でお弁当持っていきます (...以下略...) |
幼稚園のお弁当は何入れてますか? |
| 5 |
保育園に入ってから初めての遠足が明後日あります!初めてのお弁当です (...以下略...) |
保育園や幼稚園から帰宅後、家でもおやつやジュースを食べますか? |
基本的な検索結果の傾向はケース1と似通っているものの、ベクトル検索の結果に興味深い点があります。それは、検索ランキングの二位と四位に保育園ではなく幼稚園を含む文書が出現したことです。これは、保育園と幼稚園が意味的に類似しているため、ベクトル検索では保育園と幼稚園を同じような意味を持つ単語として扱っているものと考えられます。
また、検索ランキングの五位にお弁当がなくおやつやジュースが含まれる質問があることも同様の理由であると言えそうです。
ケース3. クエリに固有名詞を含む場合
検索クエリ: 多摩総合医療センター
ここからは、検索クエリが特殊な特徴をもつ場合の比較検証を行います。まずは、検索クエリに固有名詞を含む場合です。固有名詞は一般名詞と比べて文書内の出現頻度が低い傾向にあり、その言葉の意味を埋め込みモデルが学習することは困難です。そうなると、ベクトル検索では固有名詞を含む文書を正しく検索することが難しいのではないかと考えられますが、どういう結果が生まれるか見ていきましょう。
以下は、検索クエリに多摩総合医療センターという特定の病院名を与えた場合の例です。
| 検索ランキング |
全文検索 |
ベクトル検索 |
| 1 |
榊原記念病院、多摩総合医療センター、どちらで分娩するか悩んでいます。(...以下略...) |
広島県西条の八本松にある高橋ホームクリニックご存知の方に質問です。(...以下略...) |
| 2 |
- |
吹田徳洲会病院でご出産された方いらっしゃいませんか? (...以下略...) |
| 3 |
- |
神奈川県海老名市付近の婦人科検診と不妊治療が行える病院を探しています (...以下略...) |
| 4 |
- |
仙台市太白区付近でセミオープンおすすめの病院を教えてください。(...以下略...) |
| 5 |
- |
熊本県合志市でおすすめの婦人科教えてください (...以下略...) |
全文検索では、多摩総合医療センターについて記述されたデータがヒットしています。(多摩総合医療センターを含む質問は一件しか存在しなかったため、検索結果はこれのみ)
一方で、ベクトル検索を用いた場合の検索結果には多摩総合医療センターを含む文書は上位五件以内には現れませんでした。検索結果として並んだ質問を詳細に見ていくと、地域名と病院を含むという共通点が見受けられるため、多摩総合医療センターと意味的に類似する質問がヒットしているとは言えそうですが、直接的に多摩総合医療センターという病院名を含むデータを上位に位置づけることはできませんでした。
一つの例を確認しただけでは結論づけるのは尚早ですが、特定の施設や商品等、固有名詞による検索を必要とするケースでは、ベクトル検索より全文検索のほうが求める検索結果を得られやすい傾向にあるのかもしれません。
ケース4. クエリに誤字を含む場合
検索クエリ: 子供 正確
続いて、クエリに誤字を含む場合の検索結果を比較します。
ここでは、『子供 性格と打つつもりが、子供 正確と打ち間違えてしまった』ケースを想定して検索結果を比較します。
| 検索ランキング |
全文検索 |
ベクトル検索 |
| 1 |
すぐに測れる体温計でおすすめありませんか?
(...中略...)
非接触型体温計もあるのですが、全く正確に測れません? |
小学一年生になる息子がいます。小規模の小学校でクラスに7人しか男の子がいません。息子はおとなしい (...以下略...) |
| 2 |
小学校一年生の子供にGPSを持たせようと思いますが、正確に場所とか分かるGPS (...以下略...) |
子供って、なんて純粋で優しいんだろう…私は子供を (...以下略...) |
| 3 |
【犬猫のGPSトラッカーについて】犬猫用のGPS 常に正確な位置を携帯アプリで表示 (...以下略...) |
幼稚園の先生から見て満3歳児クラスの子でこの子はまだお母さんといた方が良いのではと思う子って (...以下略...) |
| 4 |
おでことかにあててピッと一瞬で体温が測れる体温計って正確に測れているんでしょうか? (...以下略...) |
息子は口が悪くなったり怒りっぽい一方で、優しく穏やかな時もあります。 (...以下略...) |
| 5 |
【おすすめの体温計について】医療関係者の方 なるべく早くて正確なおすすめの体温計 (...以下略...) |
男の子は優しいよって言われたけど (...以下略...) |
はじめに全文検索の結果を見てみると、正確を含む質問が並んでいることからクエリとした投げた子供 正確にそのまま素直に一致するデータを返していることがわかります。
一方、興味深いことに、ベクトル検索の結果には子どもの性格に関する質問が上位に並んでいます。
更に、これらの質問は性格という直接的に一致するキーワードを含んでいるわけではなくおとなしいや怒りっぽい等、性格と共起性が高いワードを含む文書たちとなっています。ここからは仮説ですが、埋め込みモデルの学習データにも子供 性格を子供 正確と間違えて使用していた文書が多く含まれていたことが、こういった結果を引き起こしたと可能性があります。その場合、子供 正確という言葉と「子供がおとなしい」「子供が怒りっぽい」といった子供の性格を表す表現が意味的に類似性が高いものとして学習されていると考えても不思議ではありません。
このように、ベクトル検索を用いることでたとえクエリに誤字が含まれていたとしても、クエリ内の他のキーワードとの文脈が考慮されることによって、ユーザーが本来求めている情報を検索結果として返すことができる可能性が示唆されました。
ケース5. クエリに文章を使用した場合
検索クエリ: 先日、4歳の子供に「サンタさんはお父さんなの?」と聞かれました。本当のことを言うべきでしょうか?
最後に、キーワードではなく文章をクエリとして使用した場合の検索結果を比較します。ベクトル検索は、文章の文脈を含む意味的な類似性を計算することができるという性質から、文章をクエリとして使用した場合にこそ全文検索にはない強みを発揮するのではないかと考えています。
また、テキスト生成AIの応用技術として注目を浴びているRAG (検索拡張生成, Retrieval Augmented Generation)では、ユーザーが入力した文章をそのまま検索クエリとして使用することが多いため、このケースはRAGの実践を見据えた検証としても重要であると言えるでしょう。
以下は、先日、4歳の子供に「サンタさんはお父さんなの?」と聞かれました。本当のことを言うべきでしょうか?という短い文章を検索クエリとして用いた場合の検索結果です。
| 検索ランキング |
全文検索 |
ベクトル検索 |
| 1 |
小1男子なんですが、まだサンタさん信じてるんですけどその方が珍しいんですかね?友達にサンタはお父さんとお母さんやでって言われたみたいで ほんまなん?って聞かれました...真実を教える年頃ですか? (...以下略...) |
5歳年長の娘が「サンタってほんとはお父さんとお母さんじゃない?」と言い出しました、、
(...中略...)
あんまり嘘つくのもよくないかな下の子もいるしあと3〜4年は信じてもらってたいです |
| 2 |
あと2ヶ月でサンタさん来ますね!?うちはもう欲しいものが決まってて、サンタさんにこれ貰おうねーとよく話すのですが、(...以下略...) |
小1男子なんですが、まだサンタさん信じてるんですけどその方が珍しいんですかね?友達にサンタはお父さんとお母さんやでって言われたみたいで ほんまなん?って聞かれました...真実を教える年頃ですか?|5歳年長の娘が「サンタってほんとはお父さんとお母さんじゃない?」と言い出しました、、?
(...中略...)
あんまり嘘つくのもよくないかな 下の子もいるしあと3〜4年は信じてもらってたいです |
| 3 |
孫に対して(3歳)言うこと聞かないと機嫌悪くなり
(...中略...)
旦那のお父さんは。子供って中々ご飯食べてくれない時どうしてますか? |
【クリスマスプレゼントについて】ちょっと時期早めの話題ですが…6歳前後のお子さんをお持ちの方に質問です。
(...中略...)
子どもの夢は壊したくないからサンタさんいないんだよっていいたくはないし ... |
| 4 |
〈サンタさんについて〉少し早いですが..サンタさんからのプレゼント?を何歳くらいからやりましたか?直接サンタさんから渡される感じではなく子供達が寝た後、枕元に置くプレゼント?です |
【旦那がサンタについて嘘をついたことについて】旦那と息子と3人でたわいもない会話をしながら食卓を囲んでいた時に今年のクリスマスプレゼント何が欲しいーの?サンタさんにお願いしようね!っと私が言うと、旦那が笑いながら息子に対してサンタなんか居ないからと言いました。 (...以下略...) |
| 5 |
5歳年長の娘が「サンタってほんとはお父さんとお母さんじゃない?」と言い出しました、、
(...中略...)
あんまり嘘?つくのもよくないかな 下の子もいるしあと3〜4年は信じてもらってたいです (...以下略...) |
子供がもう、サンタさんの話してる笑 サンタさんくる?!って何回も聞いてくる (...以下略...) |
検索クエリと同じく「サンタさんは実在しないことを子供に正直に伝えるべきか」をテーマとした質問に該当するものとしては、全文検索は1位と5位の2件、ベクトル検索は1位〜4位の4件がランクインしています。この後、6位以降の結果も見渡したところ「サンタさんは実在しないことを子供に正直に伝えるべきか」をテーマとした質問は、ベクトル検索の実行結果により多いという印象を受けました。
やはり、クエリが長くなるほど (クエリに込められる意味の情報量が増すほど) ベクトル検索はその強みを発揮する傾向があると言えそうです。
「ベクトル検索」と「全文検索」 比較結果のまとめ
ここまでの検証で得られた結果を改めて整理します。
- キーワードベースのクエリを用いて検索を実行した場合、全文検索ではそのクエリを文書内に多く含むものが上位に並ぶ傾向があり、ベクトル検索では文書の長さが短いものが上位に並ぶ傾向が見受けられた。
- 誤字を含むクエリを用いて検索を実行した場合、ベクトル検索は誤字ではなく本来検索者が入力しようとしていた情報に関連性の高い文書を検索結果として返すことができる可能性が示唆された。
- 固有名詞を含むクエリを用いて検索を実行した場合、ベクトル検索ではその固有名詞を含む文書を上位に位置づけることが困難な場合があることが示唆された。
- 文章をクエリとして用いて検索を実行した場合、ベクトル検索では文章の文脈を考慮することで全文検索以上にユーザーが求める検索結果を返すことができるという可能性が示唆された。
今回の比較検証ではケースごとに1つのクエリの結果しかご紹介していないため、ベクトル検索と全文検索の検索結果の傾向を一概に判断することはできません。そのうえで、クエリに誤字を含む場合やクエリが文章である場合など、ベクトル検索が全文検索より優れた結果を返す場面が存在することが示唆されたと言えるでしょう。
おわりに
以上、この記事ではAmazon Bedrockの埋め込みモデルを用いたベクトル検索システムのプロトタイピング、及びベクトル検索と全文検索の検索結果の比較検証を行ってきました。
近年は「ハイブリッド検索」という検索手法に注目が集まっており、全文検索とベクトル検索の検索スコアをRRF*9などのアルゴリズムによって統合することで、両者のメリットを活かした検索結果を得ることのできる可能性があります。そこで、今後は「ハイブリッド検索」システムのプロトタイピングにも取り組んでいく所存です。
また、今回のプロトタイピング結果から、Bedrockの埋め込みモデルによって獲得されたテキストのベクトル表現の有用性が確認できたため、今後は検索以外の用途にも活用を広げていきたいと考えています。コネヒト開発者ブログでは、今後も積極的に技術検証の結果を発信していきますので、ぜひ引き続きご注目ください!
それでは、今回の記事が皆さんのお役に立てれば幸いです。お読みいただきありがとうございました!
コネヒトCTO永井からのコメント
生成AI分野の進歩は、目覚ましいものがあると日々感じています。コネヒトでは、これまでAWSのサービスを基盤として、事業を着実に成長させてきました。AWSの堅牢で柔軟なインフラは、私たちのプロダクト開発において不可欠なものになっています。
そして、今回のBedrockを用いた検証結果には、この技術を用いることがユーザーの検索体験の改善につながるという手応えがありました。さらに将来的には、今回検証したベクトル検索技術とテキスト生成AIを組み合わせて使うことで、これまでにない新たなユーザー体験を提供することができる可能性も感じています。今後もコネヒトではスピード感をもってプロダクトに実装し実験を繰り返しながら、より良いユーザー体験を創造していきたいと考えています。