皆さん,こんにちは!MLエンジニアの柏木(@asteriam)です.
ここ最近は検索エンジン内製化プロジェクトに携わっていて,検索エンジニアとして,検索基盤の主にデータ連携・同期の実装を1から構築したりしていました.7月中旬にABテストまで持っていくことが出来たので,ひとまず安心しているところです.ここからはユーザーの検索体験向上のために検索品質の改善に力を入れていく予定です!
はじめに
今回新しく検索基盤をAWSのマネージドサービスを活用して構築しました!本エントリーでは,タイトルにもあるように,検索基盤の肝であるDBから検索エンジンへのデータ同期をAWS Glueを用いてニアリアルタイムで実施したお話になります.我々は以下の構成で今回の検索基盤を構築しています.
- 検索エンジン:Amazon OpenSearch Service
- データベース:Amazon Aurora
- データ同期(ETL):AWS Glue
- ワークフロー・パイプライン:AWS Step Functions
また,Step Functionsを使ったワークフロー・データ同期パイプラインに関する内容も別ブログで紹介したいと思います.全量データ同期に伴うreindexの仕組みや運用を意識したシンプルなワークフロー構成の紹介などをしようと思っています.
今回は以下の内容を紹介していこうと思います.
- AWS Glueで実現するデータ同期とは
- OpenSearchへのデータ連携でハマったところ
- 今後の取り組み
※ 今回はGlueのDBやOpenSearchとの細かい設定方法や検索エンジン内製化プロジェクトの発足した背景などに関しては,触れないのでご了承下さい🙏
目次
AWS Glueで実現するデータ同期とは
ここからは実際にGlueを用いて検索エンジンへのデータ同期をどのようにして構築したかを紹介していきます.
全体アーキテクチャ
まずは今回の検索基盤の全体アーキテクチャを紹介しておこうと思います.
- 太線矢印が「データの流れ」
- 点線矢印が「制御の流れ」
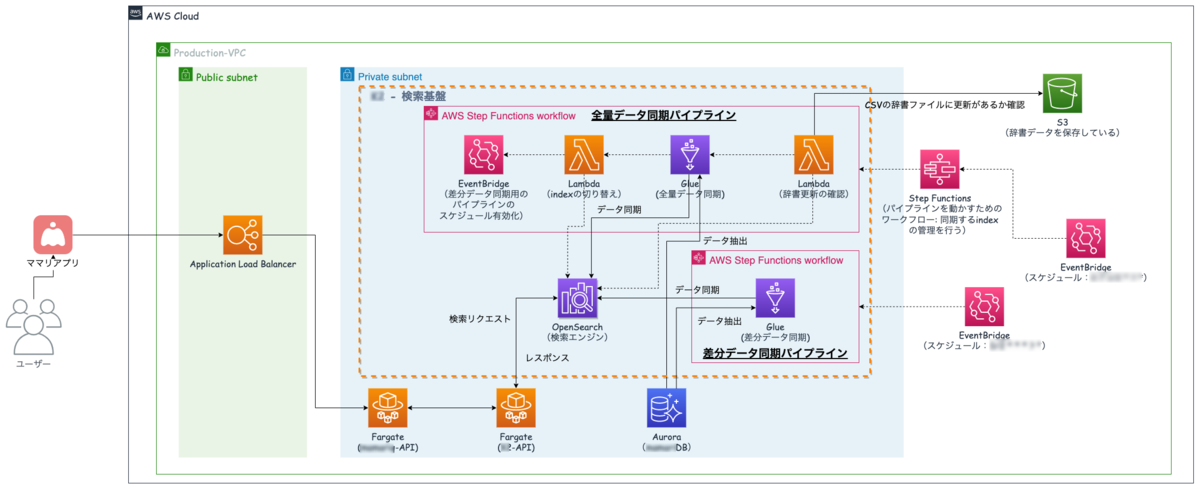
中央にあるOpenSearch(検索エンジン)に対して,2つのパイプラインを流し込んでデータを同期しています.
- 全量データ用の同期パイプライン
- 全量データの同期は,差分データ同期で取り逃がしたデータを拾ったり,バックアップ的な意味合いで定期的に実行しています.ただ1回の同期に時間がかかるので,頻繁には実施できません.
- 特定のテーブルの全データを対象に総入れ替え(洗い替え)を行います.
- 差分データ用の用の同期パイプライン
- 差分データの同期は,よりリアルタイムにアプリ上で生成されたデータを検索できるようにするために構築しています.
- 直近x分以内に更新があったデータのみを対象に同期を行います.
全量データ用のパイプラインはさらに上段で実行スケジュールを管理するワークフローが存在しています.この辺りのワークフローやパイプラインの話は別ブログで紹介します.
AWS Glueによるデータ同期
Glueは様々なデータソースからターゲットソースに向けてサーバーレスでETLができるマネージドサービスになります.バックエンドでSparkが動いているので,高速なデータ処理が可能となっています.Glue Studioという新しいUIがあり,見やすく簡単に設定できてめっちゃ使いやすいです!また,使い勝手も悪くないと思います.
今回AWS Glueを選択した理由
AuroraからOpenSearchへのデータ同期の方法はGlueの他にも,AWS Database Migration Service (AWS DMS) を使う方法がありますが,今回の差分データ抽出や今後発生しうる複雑なデータ抽出が発生した場合に,柔軟に対応できるというところでGlueを選択しました.
前提としてマネージドサービスで運用したいという気持ちがあります.これは運用していく人数も限られている中で,データ同期を行うという本筋以外の周辺の管理運用に時間やコストを割けないというのもあります.
Glueはコネクターを使って簡単にOpenSearchへデータを同期できたり,組み込みの変換処理・フィルターが用意されていたりと便利な機能が色々とあるので,AWSでETL処理をするなら最初の選択肢としてありだと思います.
データ同期の流れ
さてさて今回は上記理由からGlueを選択することにし,データソースのDBであるAuroraからデータを抽出し,Glueを用いてターゲットソースの検索エンジンであるOpenSearchにデータを同期しています.
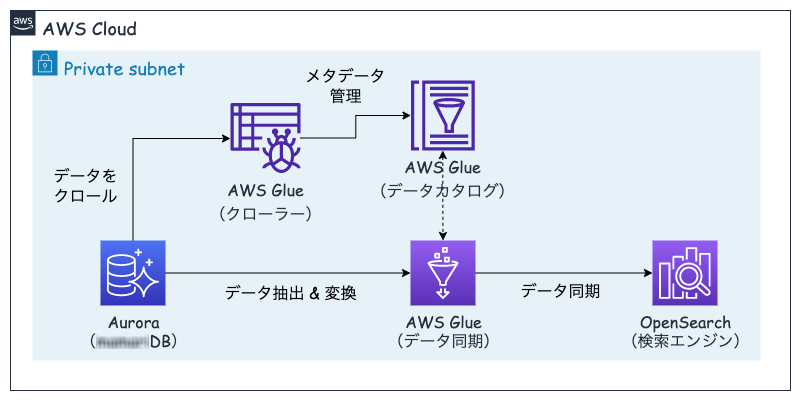
Glueを使った流れは以下のようになります.
- データベースからデータをクロールする
- クロールしたらデータカタログにメタデータを管理する
- データカタログのメタデータを元にデータソースからデータを抽出する
- ジョブを実行してターゲットにデータを同期する
手動やスケジュールなどでGlue Jobを実行したタイミングで3, 4が実行される
- Auroraへの接続
- JDBC接続
- インスタンス名・データベース名・ユーザー名・パスワードを設定
- OpenSearchへの接続
- コネクターが用意されているので,subsctribeして同じくJDBC接続
こちらの公式ドキュメントにも設定の仕方が分かりやすく書いてあるので参考にしてみて下さい.
Glue Jobの設定
Glue Jobの設定はGlue Studioという新しいUIを使って簡単に設定することができます. 決めるのはデータソースとターゲットだけです.ここで事前に上に書いたコネクターを有効化しておく必要があります.
- データソース:Data Catalog
- ターゲットソース:Elasticsearch Connector
全量と差分データの同期フローのDAGは以下のようになり,差分処理が入るかどうかの違いになります.
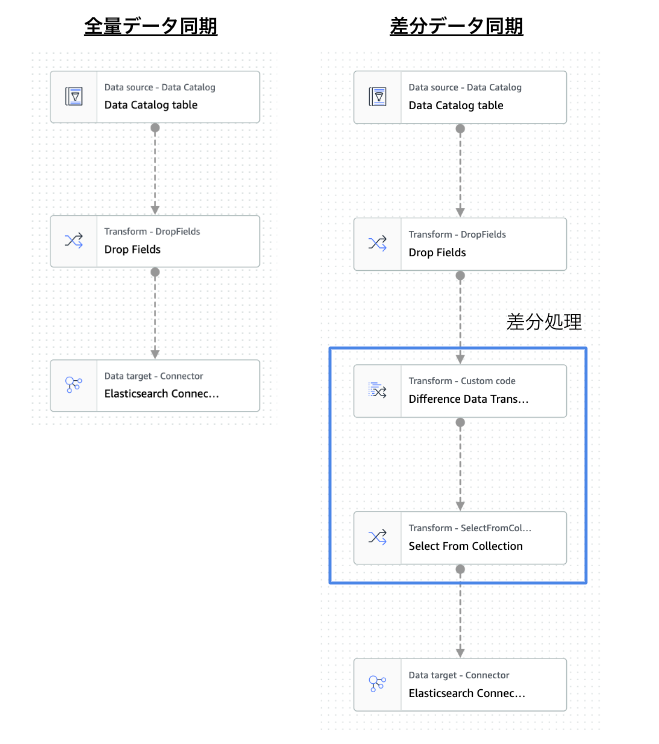
Glue Jobには最初から用意されている組み込みのTransform処理があり,それを繋ぐだけで簡単に処理を追加することができます.また,カスタム処理も作ることができ,今回の差分処理はカスタム処理を使っています.
# 青枠の部分を抜粋しています. from datetime import datetime, timedelta, timezone from awsglue.dynamicframe import DynamicFrame, DynamicFrameCollection from awsglue.transforms import DropFields, SelectFromCollection # 現在時刻からX分前の時刻を取得 JST = timezone(timedelta(hours=+9), 'JST') now = datetime.now(JST) lastXmin = now + timedelta(minutes=-X) # 差分データ抽出用のクエリ query = f''' select * from myDataSource where modified > '{lastXmin}' ''' def sparkSqlQuery(glueContext, query, mapping, transformation_ctx) -> DynamicFrame: """対象のクエリに対して,sparksqlを実行する""" for alias, frame in mapping.items(): frame.toDF().createOrReplaceTempView(alias) result = spark.sql(query) return DynamicFrame.fromDF(result, glueContext, transformation_ctx) # Script generated for node Difference Data Transform def DiffDataTransform(glueContext, dfc) -> DynamicFrameCollection: """差分データを抽出し変換する""" # DynamicFrameCollectionをDynamicFrameにする dyf = dfc.select(list(dfc.keys())[0]).toDF() diff_data = DynamicFrame.fromDF(dyf, glueContext, "diff_data") return DynamicFrameCollection({"CustomTransform0": diff_data}, glueContext) SQL_node3 = sparkSqlQuery( glueContext, query, mapping={"myDataSource": DropFields_node2}, transformation_ctx="SQL_node3" ) # Script generated for node Difference Data Transform DifferenceDataTransform_node4 = DiffDataTransform( glueContext, DynamicFrameCollection( {"SQL_node3": SQL_node3}, glueContext ) ) # Script generated for node Select From Collection SelectFromCollection_node5 = SelectFromCollection.apply( dfc=DifferenceDataTransform_node4, key=list(DifferenceDataTransform_node4.keys())[0], transformation_ctx="SelectFromCollection_node5", )
ニアリアルタイムの同期のために
今回の要件として,差分同期はニアリアルタイムのデータ同期が求められハードルが高いものになっています.これを実現するために,GlueのJob bookmarkというオプション機能を使用しています.
Job bookmark機能とは,ジョブの実行状態を保持する機能で,処理済みデータを再度処理しないようにすることで,重複処理や重複データを防ぐことができます.これによりJobの実行時間が劇的に早くなります!ただ,ここはかなりハマったので次の章でも紹介します.
最終的には,Job bookmark機能とworker数(この辺はインスタンスタイプの調整も必要)を調整することでニアリアルタイムなデータ同期を可能にしています!
数分に1回動かすスケジュール実行は以下の2通り考えましたが,最終的に2番目の方法で実装することにしました.
- GlueのJob Schedulerを使う方式
- メリット
- オーバーヘッドが少なくGlueのみでデータ同期を完結できる
- デメリット
- 最低5分間隔でしか設定できない
- X分間隔のジョブを複数作ることで回避できるが複雑で管理も大変
- エラー通知がGlueの設定からはできない(CloudWatch Logsを使えばできそう)
- 最低5分間隔でしか設定できない
- メリット
- Step FunctionsとEventBridgeを使う方式
- メリット
- エラーハンドリングや通知設定がStep Functions内でできる
- EventBridge経由のスケジューリングになり,柔軟な設定が可能
- デメリット
- 複数のサービス間でオーバーヘッドが生じる
- メリット
OpenSearchへのデータ連携でハマったところ
検証中にハマった問題(初歩的なものもあります笑)を紹介したいと思います.
- Too Many Requestsの問題
- これは何も考えずdev環境でOpenSearchにデータを投げたら,発生したエラーです.この原因は単純に同期しようとしているデータ量が多い,またOpenSearch側のインスタンスタイプのスペック不足によるものだったので,dev環境の方もスペックを上げたところ解消されました.
- Job bookmark機能が言うことを聞かない問題
- 予想以上に処理時間がかかった
- 1回のジョブ実行時はブックマークを作ることになるので,通常の実行となります.そのため,それなりに実行時間がかかるということを知らなかったので,効いていないと勘違いしました.差分の同期に関しては,dry-run的な形で一度動かしておく必要があることを学びました.
- KeysとKeysSortOrderの設定
- この問題は,データカタログからデータを抽出するところで設定するadditional_optionsのKeysSortOrderをdescにすると意図した通りに上手く動かないという問題です.OpenSearchへデータ同期するのに,重複データを排除するためにupsert形式で入れているのですが,upsertが効いていないことに気づいて発見しました.
- これはタイムスタンプのように昇順で増加する場合,ascで指定する必要があったみたいです.直感的には,新しい順で並ぶdescにすると思ったのですが,それだと上手く機能しないことが分かりました.(これに全然気づかなくて苦労しました…😅)
- 正:additional_options={"jobBookmarkKeys": ["id", "modified"], "jobBookmarkKeysSortOrder": "asc"}
- Keysは複数取ることができ,id(レコードにおける一意のキー)とmodified(更新日)を指定しています.
- この設定は,Glue Jobの最初のフェーズでデータカタログからデータを抽出する部分でオプションとして設定します(コード例を下に載せておきます).
- 正:additional_options={"jobBookmarkKeys": ["id", "modified"], "jobBookmarkKeysSortOrder": "asc"}
- 予想以上に処理時間がかかった
# Script generated for node Data Catalog table DataCatalogtable_node1 = glueContext.create_dynamic_frame.from_catalog( database="<データカタログに登録されているDB名>", table_name="<上記DBに登録されているテーブル名>", transformation_ctx="DataCatalogtable_node1", additional_options={"jobBookmarkKeys": ["id", "modified"], "jobBookmarkKeysSortOrder": "asc"} )
Glue→OpenSearch間でエラーが発生した場合,なかなか原因を調査して特定するのが難しいなと感じました.CloudWatch Logsに出力するロギングオプションを有効化したりもしていますが,それでも大変です.今後の取り組みでも紹介していますが,Spark UIを立ち上げて詳細を追っていく必要がありそうで,この辺りはもう少し簡単にできるようになると嬉しいなと思います.
今後の取り組み
データ同期部分に関して,今後取り組んでいきたいことを紹介します.
- Glueのジョブ実行時間を収集して見える化
- Start-up timeやExecution timeを計算することで,処理時間が遅くなっているかどうかを知ることでサービスへの影響をプロアクティブに把握することができます
- Glueジョブのモニタリング
- Spark UIによってどこの処理で時間がかかっているかを把握することができるため,ボトルネックを探ることができ,エラー時の原因究明やボトルネックとなっている処理を特定したりすることでより改善を進められる
- 参考
- データ基盤の安定した運用
- 検索エンジンにとってデータが安定して同期されることが必要不可欠なため,どんな状態でも止まらず安定してデータ同期を続けられる仕組みとそれを計測する方法についても定義していきたいと思っています
- Classiさんのブログを参考にさせて貰ってます
- 検索エンジンにとってデータが安定して同期されることが必要不可欠なため,どんな状態でも止まらず安定してデータ同期を続けられる仕組みとそれを計測する方法についても定義していきたいと思っています
今後複数のテーブルを同時に連携していく必要があったり,機械学習によるランキング学習など負荷が発生したり処理時間の問題など色々な課題が生まれてくることが考えられるので,そのためにも状態の把握や監視を進められると良いと思っています.
おわりに
最後に,コネヒトではプロダクトを成長させたいMLエンジニアを募集しています!!(切実に募集しています!)
もっと話を聞いてみたい方や,少しでも興味を持たれた方は,ぜひ一度カジュアルにお話させてもらえると嬉しいです.(僕宛@asteriamにTwitterDM経由でご連絡いただいてもOKです!)