こんにちは。
今回はCakePHPのバージョン4.3から非推奨機能に追加されたTestFixture の対応をしたのでバックエンドエンジニアの共同制作でブログに書いてみました。
冒頭〜導入手順5までは高橋で、手順6以降は西中が書いております。
以前PHP8.1にアップデートした際にCakePHPのバージョンも4.2から4.3にアップデートしました。
その時のブログはこちら↓
https://tech.connehito.com/entry/2023/03/31/195819
この時からテストを実行する度に以下のような警告が出るようになりました。
Deprecated Error: You are using the listener based PHPUnit integration. This fixture system is deprecated, and we recommend you upgrade to the extension based PHPUnit integration. See https://book.cakephp.org/4/en/appendices/fixture-upgrade.html
/var/www/html/server/vendor/cakephp/cakephp/src/TestSuite/Fixture/FixtureInjector.php, line: 79
対象のリポジトリは元々CakePHP3系で作られていたので、テストに使うテーブル定義はFixtureクラスの中に定義されていました。
ですが、CakePHPのマイグレーションを利用しておらず、いわゆるマスタとなるようなテーブル定義は別のリポジトリで管理されています。
そのため、テーブル定義が二つの場所にある二重管理状態になっていました。
CakePHPの公式ドキュメントではCakePHPのマイグレーションを使った方法については詳細に記述されているのですが、DDLファイルを使った方法は簡潔に記述しかありません。ネットで探してもあまり見つからなかったので、同じように躓いた人の役に立てれたら嬉しいなと思っています。
目次
前提
対応方法をご紹介する前に前提条件をお伝えします。
PHP: 8.1
CakePHP: 4.3
PHPUnit: 9.6.5
AWS
ECS
Amazon Aurora MySQL v2(MySQL5.7)
DBのスキーマ管理はアプリケーションコードとは別リポジトリ
GitHub Actions
導入手順
mysqldumpによって取得したDDLファイルからテストのテーブル定義を使うように変更しました。
1. アプリケーションリポジトリにDDLファイルを/config/schema配下に置く
DDLファイルは以下のSQLコマンドで生成しました。
mysqldump -u[ユーザー] -h[ホスト] -P[ポート] -p[パスワード]
FixtureやFactoryでレコードを追加する際に、AUTO_INCREMENTの値が1ではない場合主キーが重複してしまうため、awkコマンドを使って初期値を変換しました。
awk '{ gsub(/AUTO_INCREMENT=[0-9]+/, "AUTO_INCREMENT=1"); print }' "base_test.sql" > "test.sql"
2. phpunit.xmlを変更する
phpunit.xml から <listeners> ブロックを削除し、以下の内容を phpunit.xml に追加しました。
ref: https://book.cakephp.org/4/en/appendices/fixture-upgrade.html
< extensions>
< extension class = "\Cake**\T**estSuite\Fixture\PHPUnitExtension" />
</ extensions>
3. tests/boostrap.phpに追記する
1で置いたDDLファイルを使用してテーブル定義を取得します。
ref: https://book.cakephp.org/4/ja/development/testing.html#creating-test-database-schema
$testSqlFile = dirname(__DIR__) . '/config/schema/test.sql';
(new SchemaLoader())-> loadSqlFiles($testSqlFile, 'test');
4. Fixtureクラスからテーブル定義を削除する
実施したリポジトリは元々CakePHP3系で作られていたので、テストに使うテーブル定義はFixtureの中に定義されていました。
段階的なアップグレードを行っていたため、Fixtuer内にまだテーブル定義は残っている状態です。
そのため、まずは各Fixtureクラスからごっそりテーブル定義ブロックを削除していきます。
<?php
namespace App\Test\Fixture;
use Cake\TestSuite\Fixture\TestFixture;
/**
* ArticlesFixture
*
*/
class ArticlesFixture extends TestFixture
{
/**
* Table name
*
* @var string
*/
public $table = 'articles';
public $connection = 'test_hoge';
- /**
- * Fields
- *
- * @var array
- */
- // @codingStandardsIgnoreStart
- public $fields = [
- 'id' => ['type' => 'integer', 'length' => 11, 'unsigned' => true, 'null' => false, 'default' => null, 'comment' => '', 'autoIncrement' => true, 'precision' => null],
- 'title' => ['type' => 'string', 'length' => 255, 'null' => false, 'default' => '', 'collate' => 'utf8mb4_general_ci', 'comment' => '', 'precision' => null, 'fixed' => null],
- 'description' => ['type' => 'string', 'length' => 255, 'null' => false, 'default' => '', 'collate' => 'utf8mb4_general_ci', 'comment' => '', 'precision' => null, 'fixed' => null],
- 'status' => ['type' => 'integer', 'length' => 3, 'unsigned' => false, 'null' => false, 'default' => '0', 'comment' => '', 'precision' => null, 'autoIncrement' => null],
- 'created' => ['type' => 'datetime', 'length' => null, 'null' => true, 'default' => null, 'comment' => '', 'precision' => null],
- 'modified' => ['type' => 'datetime', 'length' => null, 'null' => true, 'default' => null, 'comment' => '', 'precision' => null],
- '_indexes' => [
- 'index_status' => ['type' => 'index', 'columns' => ['status'], 'length' => []],
- ],
- '_constraints' => [
- 'primary' => ['type' => 'primary', 'columns' => ['id'], 'length' => []],
- ],
- '_options' => [
- 'engine' => 'InnoDB',
- 'collation' => 'utf8_general_ci',
- ],
- ];
/**
* Records
*
* @var array
*/
public $records = [
︙
];
}
また、$recordsの中に配列がある場合、今まで$fieldsのtype指定していたのでこのように独自でjson形式にしなければなりません。
$records = [
[
'id' => 1,
'urls' => [
0 => [
'type' => 1,
'url' => 'https://www.example1.co.jp',
],
1 => [
'type' => 2,
'url' => 'https://www.example2.co.jp',
],
],
],
[
'id' => 2,
'urls' => [
0 => [
'type' => 1,
'url' => 'https://www.example1.co.jp',
],
1 => [
'type' => 2,
'url' => 'https://www.example2.co.jp',
],
],
],
];
// テストで使用するのにjson形式に変換する
foreach ($records as $seq => $record) {
if (is_array($record['urls'])) {
$records[$seq]['urls'] = json_encode($record['urls']);
}
}
$this-> records = $records;
以下のように直接json形式にするでも大丈夫です。
$records = [
[
'id' => 1,
'urls' => '[{"type": 1,"url": "https://www.example1.co.jp"},{"type": 2,"url": "https://www.example2.co.jp"}',
]
[
'id' => 2,
'urls' => '[{"type": 1,"url": "https://www.example1.co.jp"},{"type": 2,"url": "https://www.example2.co.jp"}',
]
];
5. ユニットテストを回してみる
今回実施したリポジトリではDockerコンテナを利用しているので、コンテナの中に入ってPHPUnitを回すようにしていました。
元々、composer.json 内でPHPUnitを定義しているため、composer から呼び出せるようになっています。
"scripts ": {
"post-install-cmd ": [
"App \\ Console \\ Installer::postInstall "
] ,
"post-create-project-cmd ": "App \\ Console \\ Installer::postInstall ",
︙
"test ": "phpunit --colors=always "
} ,
テストコードの件数が少ない場合は気にしなくて良いのですが、テスト件数が多くテスト実行後に結果を見ようとするとターミナル上で見切れてしまうことが多々あったので実行結果はテキストファイルに書き出すようにしていました。
その時、composerのタイムアウトが発生してしまうことがあるので予め環境変数を上書きしてタイムアウトが起きないように設定した上でテストを実行し、出力したファイルを見比べながらテストコードを実情にあった形で直していきます。
$ export COMPOSER_PROCESS_TIMEOUT=0
$ composer test > text.log
CakePHPのFixtureはどうやら主キーやユニークキーが重複してしまうFixtureのレコードも許してしまい、レコード重複エラーが発生してしまうという事象が頻発してしまいました。
このリポジトリではFixture Factoriesを利用しているので、重複が出ないようにテストケース内でFactoryクラスを使ってレコードを作成するように書き換えることで既存のテストに影響が出ないように修正を行いました。
ref: https://tech.connehito.com/entry/2022/07/22/100000
これで一応Fixtureの警告は消えましたが、これだとテーブル定義を変更した場合にアプリケーションリポジトリのDDLファイルを手動で更新しなくてはなりません。
テーブル定義を管理しているリポジトリに変更があった場合に自動でAWSのS3にDDLファイルをアップロードし、アプリケーションリポジトリでそのDDLファイルをダウンロードしてくるという仕組みを作ることになりました。
6. 自動化
6.1. DDLファイルをS3のバケットにアップロードする
テーブル定義変更の度にリポジトリ内のDDLファイルの変更を行わないといけないだけでなく、弊社の場合、複数のリポジトリで同じDBを参照しているということが多々あるため、スキーマ定義の変更の度に各リポジトリ内のDDLファイルを書き換えるのは手間だという問題もありました。
今回の本題であるスキーマ定義のDDLファイルをダウンロードする仕組みは、正にこの問題を解決する手段として考えたものでした。
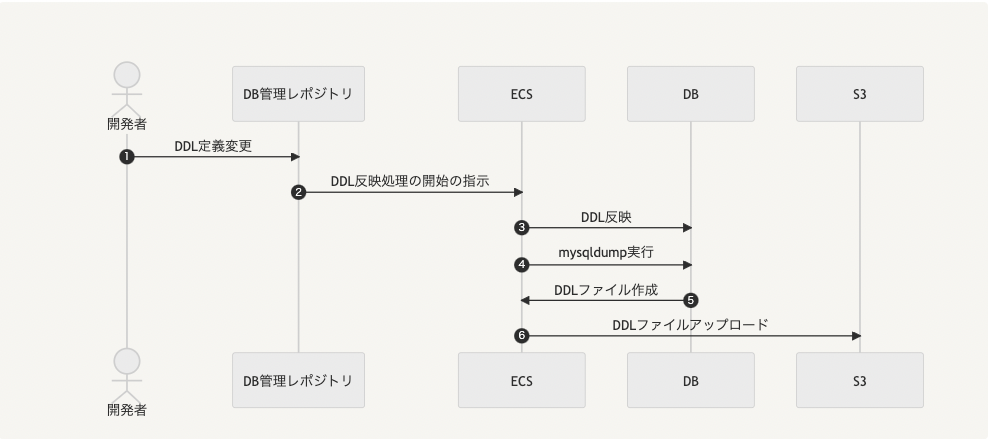
弊社では前述の通り、 Ridgepole を使ってスキーマ定義を管理しているのでスキーマ定義の変更が発生したタイミングでDDLファイルを作成し、S3のバケットにアップロードする仕組みを作成しました。
簡単に流れを説明するとこのようになっています。
開発者がテーブル定義を変更し、スキーマ定義管理用のリポジトリに push します。
スキーマ定義管理用のリポジトリに設定されているGitHub ActionsがDDL反映処理の実行のためのECSを起動します。
この一連の処理については過去にブログで投稿しているので、そちらを参考にしてください。
refs: https://tech.connehito.com/entry/2019/10/08/165500
前述のDDL反映を行います。
ECS内でmysqldumpコマンドを実行します。
各スキーマのDDLファイルを取得し、ローカルに保存します。
この記事の冒頭で紹介させていただいたawkコマンドを使ってDDLファイルの一部を書き換える処理も行っています。
S3にファイルをアップロードします。
S3へのアップロードフロー
6.2. S3のバケットからDDLファイルをダウンロードする
「S3のバケットからDDLファイルをダウンロードする」ということは決まったのですが、「じゃあどのタイミングでDDLファイルをダウンロードするのが適切なんだろう?」という課題が出てきました。
そこで考えたのがこの3つのタイミングでした。
テスト実行時にDDLファイルをダウンロードする
DockerビルドのタイミングでDDLファイルをダウンロードする
Dockerコンテナを立ち上げたタイミングでDDLファイルをダウンロードする
テスト実行時にDDLファイルをダウンロードする
最初に思いついたのはこの方法です。
毎回テストの度に最新のDDLファイルをダウンロードすれば最新のスキーマ定義でテストが実行できるというメリットはあります。
ですが、
通信エラーでS3のバケットからDDLファイルをダウンロードできなかった場合にテストが動かなくなってしまう
スキーマ定義の変更は頻繁に行われるわけではないので、毎回DDLファイルをダウンロードするのは無駄
という問題があったため、却下となりました。
DockerビルドのタイミングでDDLファイルをダウンロードする
Dockerコンテナをビルドするのはそんなに頻繁ではないので一見良さそうに思えます。
ですが、
テストコードは本番環境には不要なため、不要なファイルがDockerイメージに含まれてしまう
DDLファイルを含める分、Dockerイメージが大きくなってしまう
本番環境には不要なファイルをダウンロードするために、DockerイメージをビルドするためのCIの設定にAWSのキーを設定しないといけない
という問題があったため、こちらも却下となりました。
Dockerコンテナを立ち上げたタイミングでDDLファイルをダウンロードする
ローカルでDockerコンテナを立ち上げる際に必ず実行するシェルファイルがあるため、そちらにDDLファイルをダウンロードする処理を追加しました。
ローカルのDockerコンテナは何かライブラリの更新・変更のような大きな変更があったらビルドし直すということもあり、いまの開発スタイルではこのタイミングが適切だろうということになり、このタイミングでDDLファイルをダウンロードすることになりました。
また、「なんかスキーマ定義合ってないかも?」となった時でも「まず最初にDockerコンテナを立ち上げ直してみよう」という手段が取れるので、問題解決の第一歩の負担が重くないことも良さそうだねという話になりました。
実際のシェルの処理とは異なりますが、以下のように aws-cli の aws s3 cp コマンドでS3のバケットからダウンロードし、 tests/bootstrap.php で読み込めるようにしました。
# copy table schema files from s3
aws s3 cp s3://[DDLファイルのあるバケット]/メインで使うDB.sql /tmp/ && \
aws s3 cp s3://[DDLファイルのあるバケット]/連携して使うDB1.sql /tmp/ && \
aws s3 cp s3://[DDLファイルのあるバケット]/連携して使うDB2.sql /tmp/ && \
aws s3 cp s3://[DDLファイルのあるバケット]/連携して使うDB3.sql /tmp/
cp /tmp/*.sql /var/www/html/config/schema/
弊社のリポジトリはローカルのディレクトリを /var/www/html ディレクトリにマウントする形にしているので、マウントの対象外の /tmp ディレクトリにDDLファイルをダウンロードし、実際に読み込むファイルはマウント後のディレクトリにコピーしたものを利用する形にしています。
// Load one or more SQL files.
$ddlFiles = [
'test' => 'メインで使うDB.sql',
'test_sub1' => '連携して使うDB1.sql',
'test_sub2' => '連携して使うDB2.sql',
'test_sub3' => '連携して使うDB3.sql',
];
$schemaLoader = new \Cake\TestSuite\Fixture\SchemaLoader();
foreach ($ddlFiles as $schema => $file) {
$fullPath = dirname(__DIR__) . '/config/schema/' . $file;
if (!file_exists($fullPath)) {
// ファイルが存在しない場合は /tmp ディレクトリからコピーしてくる
copy('/tmp/' . $file, $fullPath);
}
$schemaLoader-> loadSqlFiles($fullPath, $schema);
}
まとめ
スキーマ定義をダウンロードできる仕組みを入れ、単体テストで利用できるようにしました。
これにより、最新のスキーマ定義でテストを実行できるようになり、テストコードとデータベース構造の整合性を維持できるようになりました。また、スキーマ定義の変更に柔軟に対応できるため、開発のスピードアップにもつながっていくことが期待できます。
他のリポジトリでも同じDBを参照しているため、横展開していくことで開発効率・開発者体験の向上が見込めそうです!
コネヒトでは一緒に働く仲間を募集しています!
そして興味持っていただけた方は気軽にご連絡ください!
https://www.wantedly.com/companies/connehito/projects