皆さん,こんにちは!最近は検索エンジニアとしての仕事がメインの柏木(@asteriam)です.
はじめに
今回はTips的な記事になります.背景としては,アプリの検索ログをBigQueryに溜めているのですが,それを検索エンジンのサジェスト機能で使用するために,BigQueryからAmazon OpenSearch Serviceへデータ連携を実施しました.その際にBigQueryのシャーディングされたテーブルをどのようにして連携したかというお話になります.
検索システムのデータ基盤構築に関する過去のブログでも紹介していますが,我々はGlueを用いて検索エンジン(OpenSearch)へのデータ連携を行っています.今回はGlueを用いる点は同じですが,データソースはBigQuery,ターゲットソースをOpenSearchとしてデータ連携しました.
今回は以下の内容を紹介していこうと思います.
- BigQuery→OpenSearch連携の概要
- BigQueryのシャーディングされたテーブルを連携する方法
目次
BigQuery→OpenSearch連携の概要
今回紹介するデータ連携は至ってシンプルです.
下図にあるように,BigQueryにある検索ログをGlueでExtractし,検索エンジンであるOpenSearchへLoadする流れになります.
- データソース:BigQuery
- ターゲットソース:OpenSearch

Glueには,BigQueryに接続するためのコネクターが用意されており,簡単に連携ができるようになっています.接続方法の手順はクラスメソッドさんのブログが参考になるので,そちらに譲ろうと思います.(コネクターをSubscribeする画面にも英語ですが,説明が記載されています)
参考:AWS Glue Connector for Google BigQueryを使ってBigQueryからS3にデータを転送する
データソース(BigQuery)の設定では,BigQueryのプロジェクトIDや連携したいテーブルIDなどの情報が必要になります.一方で,ターゲットソース(OpenSearch)の設定では,インデックス名やエンドポイント名などが必要になります.
ここで,連携したいBigQueryのテーブルは日付でシャーディングされており,そういったテーブルをどうやって連携するかが問題になります.
BigQueryのシャーディングされたテーブルを連携する方法
日付でシャーディングされたテーブルとは,下図のようにtable suffixが日付になっていて,日ごとにインクリメントされた形式のテーブルのことを言います.
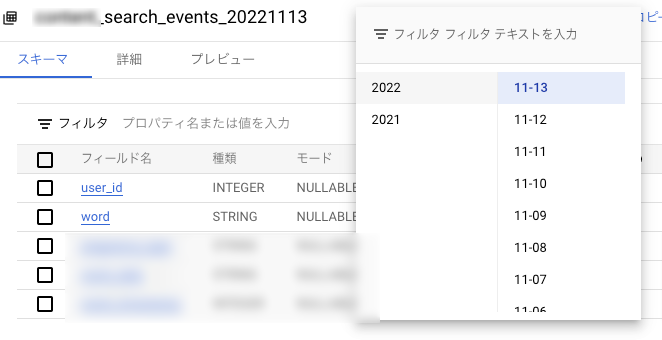
このようなテーブルを連携したい場合にどうすればいいか?
Connection optionsのKeyにqueryを使う
BigQueryコネクターのConnection optionsに幾つかの設定が必要になりますが,そのうちの一つとして,queryというkeyを使うことでシャーディングされたテーブルの連携に対応することができます!
参考:Push down queries when using the Google BigQuery Connector for AWS Glue
下図はGlue StudioでのBigQueryコネクターの設定画面になります.
BigQueryコネクターで設定する内容は4つになります.
materializationDataset: <BigQuery側で連携用に一時的に作成するデータセット名>parentProject: <プロジェクトID>viewsEnabled: <ビューの許可>query: <データ抽出するためのクエリ>

queryには実行したいクエリをそのまま入力します.例えば,現在から30日前までの検索ワードとそのカウント数を集計したデータを抽出したい場合は,以下のような感じになります.
SELECT word, count(word) AS word_count FROM `hogefuga.search_events_*` # 検索ログが入ったテーブル WHERE 0 = 0 AND _TABLE_SUFFIX >= FORMAT_DATE('%E4Y%m%d', CURRENT_DATE('Asia/Tokyo') - 30 ) GROUP BY word
ただし,注意点があります.
materializationDatasetに設定するデータセットは予めBigQueryに作成- 試行錯誤の結果,データセットがない場合にGlueは勝手に作ってくれず,エラーになってしまうので,予め作成しておく必要があります
- 加えて,このデータセット配下に一時的に作られるテーブルに対するwrite権限が必要で,それがないとエラーになります
最後に,OpenSearch側の設定も載せておきます.
path: <インデックス名>es.node: <エンドポイント名>

おわりに
単一のテーブルは簡単に連携できたのですが,シャーディングされたテーブルを連携する時にハマってしまったので,今回のTipsが誰かの役に立てば幸いです!GCP側の権限などはハマりポイントかなと思うので,試しながら試行してみて下さい.
検索ログが連携できたことで,サジェスト機能も前進しているので,これからも検索エンジンの改良を進めて行こうと思っています!
最後に,コネヒトではプロダクトを成長させたいMLエンジニアを募集しています!!(切実に募集しています!)
もっと話を聞いてみたい方や,少しでも興味を持たれた方は,ぜひ一度カジュアルにお話させてもらえると嬉しいです.(僕宛@asteriamにTwitterDM経由でご連絡いただいてもOKです!)
また,コネヒトにおける機械学習関連業務の紹介資料も公開していますので,こちらも是非見て下さい!!