みなさんこんにちは。機械学習チームのたかぱい(@takapy0210)です。
最近はワールドトリガーというアニメにハマっておりまして、2022年から第3期の放映が始まっております。
内容はよくあるバトルアニメですが、チームで戦略を練って戦うところがユニークでとても面白いです。(個々の力だけだと到底叶わない相手に対して戦略で勝つ、という展開もあり、戦略の大事さを改めて痛感しました)
さて本日は、コネヒトの機械学習プロジェクトがどのように推進され、開発・実装フェーズに移行していくのかについて、1つの事例を交えながらご紹介できればと思います。(※あくまで1つの事例なので、全てがこのように進むわけではありません)
目次
- 今回のプロジェクト概要
- 機械学習プロジェクト全体の流れ
- 構想フェーズ:ビジネス要件を明確にし、共通認識をつくる
- PoCフェーズ:定量チェックと定性チェックの両方を実施する
- で、今回の施策の効果はどうだったの?
- We are hiring!!
今回のプロジェクト概要
コネヒトではママリというコミュニティアプリを運営しており、1ヶ月で約130万件のQAが投稿されています。
この投稿を全て目視チェックするのは現実的に不可能なため、目視チェックする前段で機械学習モデルによるチェックを挟むことで、荒らしのような投稿やガイドラインに違反するような投稿のみを、人間がチェックする運用となっております。
(詳細は以前のブログでも紹介しているので、興味のある方はこちらもご覧ください)
今回のプロジェクトは、この検閲モデルを特定のユーザークラスタに適応し運用させることで、CS(カスタマーサクセス)チームの抱える課題を解決できるのではないか、ということでスタートしています。
機械学習プロジェクト全体の流れ
機械学習プロジェクトには、大きく分けて以下4つのフェーズがあると考えています。
- 構想フェーズ
- PoCフェーズ
- 実装フェーズ
- 運用フェーズ
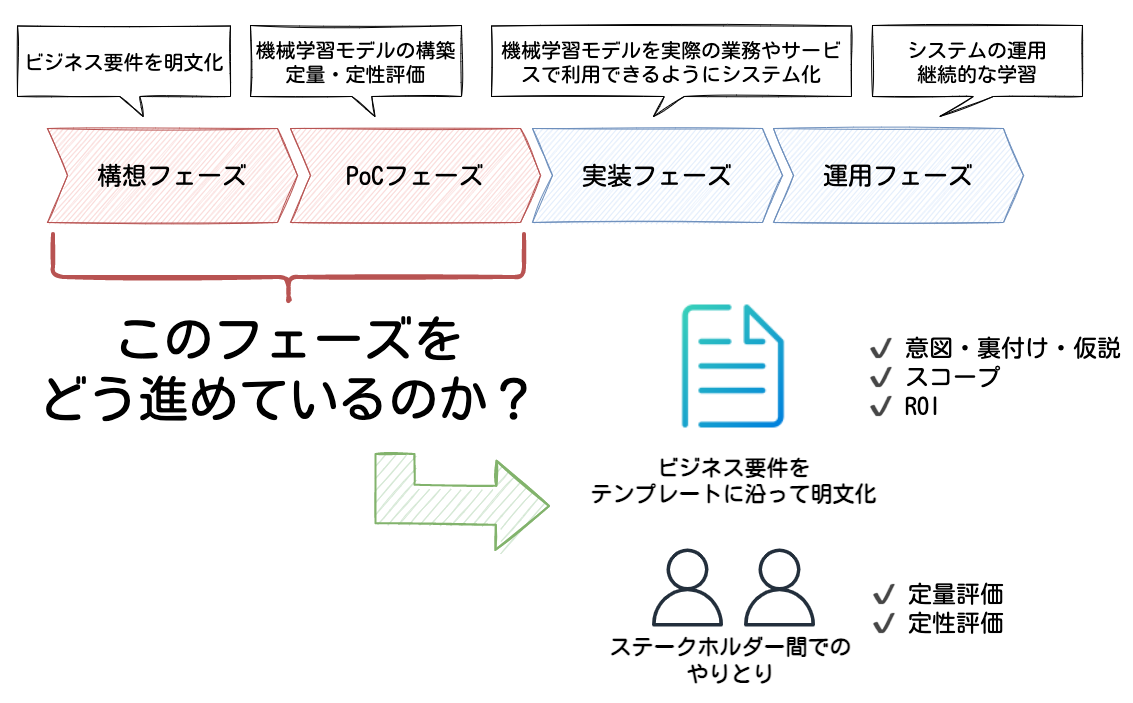
本エントリでは、構想フェーズとPoCフェーズに焦点を当てながらお話ししていこうと思います。
それぞれのフェーズを簡単に説明すると、構想フェーズではプロジェクトによって解くべき課題を特定し、ビジネス要件を明文化していきます。ここでは、十分に投資対効果が見込まれるテーマを見極めることが重要だと思います。
PoCフェーズでは、構想フェーズで立てたテーマが技術的に実現可能かどうかを、機械学習モデルのモックアップを構築して検証していきます。
上記のフェーズで特に大切だと感じている点について、プロジェクトの事例を交えながら深ぼってお話ししていこうと思います。
- 構想フェーズ:ビジネス要件を明確にし、共通認識をつくる
- PoCフェーズ:定性チェックと定量チェックの両方を実施する
構想フェーズ:ビジネス要件を明確にし、共通認識をつくる
今回は以下のようなテンプレートに沿って、CSチームと共に要件を明文化していきました。
※ 冒頭でもお話した通り「既に本番で運用している検閲モデルを特定のユーザークラスタでも扱えるよう適応させる」というプロジェクトなので、本来であれば議論すべきである「機械学習で扱えるテーマかどうか」について、今回は議論していません。
# 提案施策の概要(3行くらいで)
- hoge
- fuga
- piyo
## 関連する部門や人
- hoge
## 要求分解
- As is:今何が起きているか(今(まで)、こうだ(った)よね、みたいな話)
- hoge
- Issue:その状況をどう捉えているか、何が課題か(これって問題だよね、みたいな話)
- hoge
- To be:あるべき姿・なりたい姿 / どんなアプローチで解決するのか(なので〜というアプローチをして〜のような状態になりたい、みたいな話)
- hoge
# アプローチの具体(As is → To beになるための具体的な行動)
## (To beに対して)なぜそのアプローチ・解決策なのか?(意図・裏付け・仮説)
- hoge
## 今回は具体的に何をしようとしているのか?(今回のスコープ)
- hoge
## どんな効果を期待しているのか?(ROI的な話)
- hoge
上記の項目を全て埋めることができれば、自然と全体像が見えてくるようになると思います。
中でも個人的には「どんな効果を期待しているのか?(ROI的な話)」の部分が重要だと思っているので、次項でもう少し詳しくお話しします。
どんな効果を期待しているのか?(ROI的な話)
ここで考えることは、ざっくり言うと「今までは〇〇だったものが、この施策をやることで×××になる」といったことになります。
今回のプロジェクトでは具体的に以下のようなことについて議論し明文化しました。
- コスト削減
- 定量評価:検閲件数が半分削減できたときにxx万円/月カット
- サービス品質向上
- 定量評価:人間が目視検査しなくて良いものはすぐに投稿されるので、回答率の向上や回答がつくまでの時間が短縮できる
- サービス品質維持
- 定性評価:検閲モデルを導入したあとでもコミュニティの品質は担保したい
- etc...
このように、定量的な数値に関しても関係者間で共有認識をとっておくことで、この後のPoCフェーズがスムーズにいくと思います。
今回の例では「検閲件数が半分に削減できれば月のオペレーション時間がxx時間ほど削減できる」ということが試算できているので、「コミュニティの品質を維持しながら、検閲件数が従来の半分に削減できる機械学習モデル」を開発すれば良いことになり、PoCフェーズのゴールもある程度明確にすることができます。
(最高のモデルを開発すべく奮闘し、気がついたらずっとPoCやっている・・・みたいなことも防げます😇 )
ビジネス要件が明文化され、ビジネスインパクトが大きいと判断できれば、次のPoCフェーズへ移行します。
PoCフェーズ:定量チェックと定性チェックの両方を実施する
今回の機械学習モデルは「ガイドラインに違反しているか否か」を判別するシンプルな2値分類タスクです。
このようなタスクで用いられる評価指標としてはAccuracyやRecall、Precisionなどが挙げられ、これらの指標を用いて構築した機械学習モデルの性能を定量的に評価していきます。
ある程度形になってきたら、実際の運用を想定すべく、ある一定期間のデータをモデルで推論したものを、CSチームに定性的に評価してもらいます。
ここでチェックしてもらう目的は以下の2点です。
- コミュニティ運営の視点から、ガイドラインに著しく違反しているものが正しく推論できているか
- モデルの閾値*1をどの程度にすれば、期待する成果( = コミュニティの品質を維持しつつ、検閲件数を従来の半分にする)を実現できそうか
定性チェックの必要性
定量的な評価のタイミングでは、例えば「Recallが80%(今回だと、違反と推論したデータの中に真の違反データがどれくれい含まれているか)」という値は計算することができますが、この数値だけで本来の要件であった「コミュニティの品質を維持しつつ、検閲件数を従来の半分にする」が満たせるかどうか判断するのは難しいです。
「取りこぼしている20%にはどのようなデータが含まれているのか?」「20%のうち漏らしたくないデータを漏れなく検閲するには、どのような方法が考えられるか?」といった部分を議論できるように、CSチームにチェックしてもらいつつビジネス要件との差分を徐々に詰めていきます。
この議論により、「機械学習モデルをアップデートして精度を上げれば解消できそうな問題」なのか、それとも「モデルのアップデートでは解消できない問題なので、後処理などを工夫する必要がある」のか、といった勘所を掴むこともできます。
上記のようなモデル構築→定量チェック→定性チェックを繰り返しながら、当初の要件を満たせるところまで、検証を続けていきます。
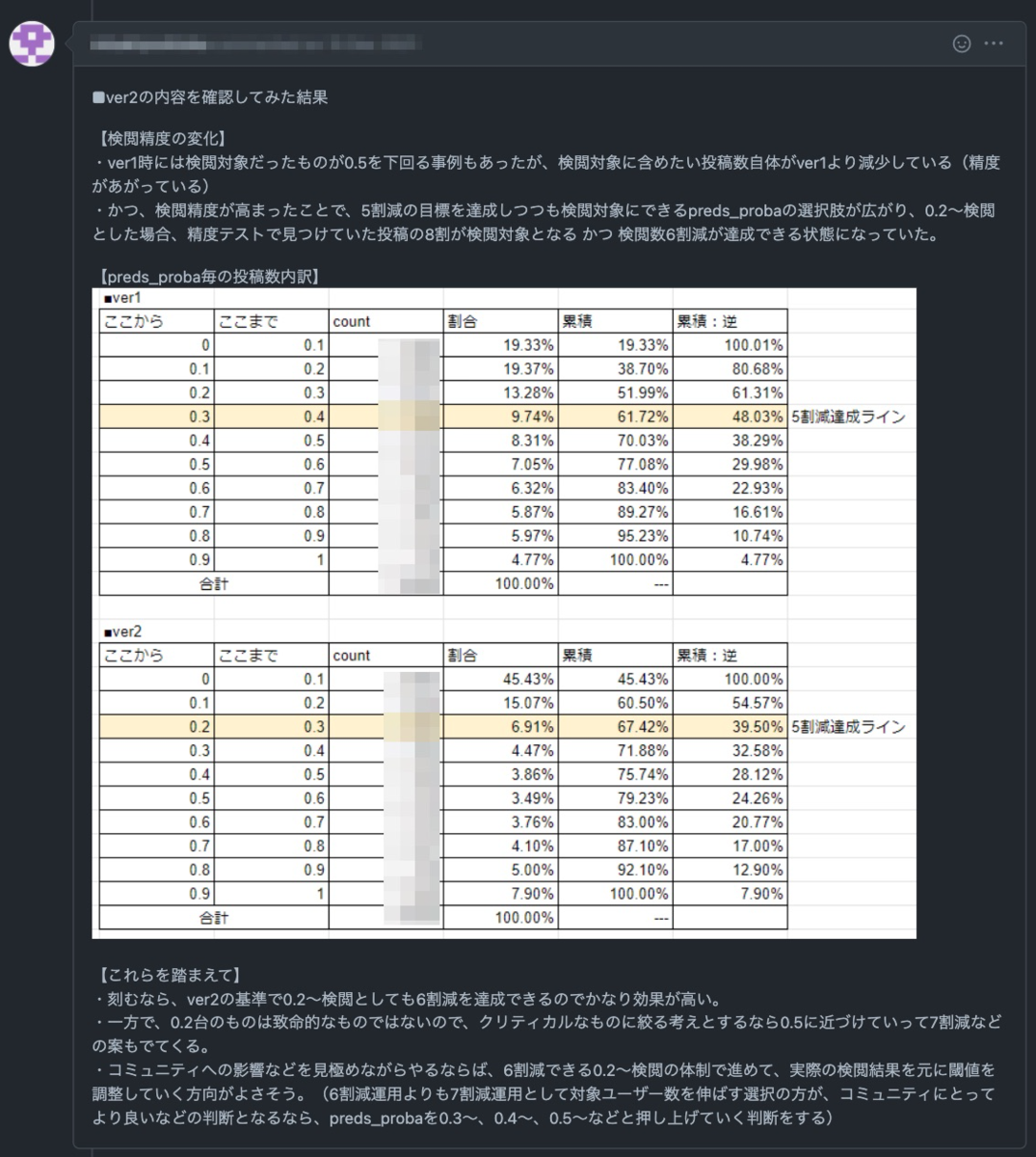
今回はベースラインモデル(ver1)を作成してCSチームに定性チェックをお願いしたところ、検閲漏れの投稿(人間の目視チェックを行いたいが、モデルでは"問題なし"と推論されたデータ)がいくつかあったため、そこを解消できるようにモデルをアップデート(ver2)しました。
ver2のモデルでは定性チェックも問題なかったため、実装フェーズに移行し、2022/03/23現在では無事に運用できています。
で、今回の施策の効果はどうだったの?
運用を開始してまもなく1ヶ月ほど経ちますが、当初の期待通り、xx万円/月のコスト削減に寄与できています。
また、1つの質問に対する平均回答数も0.3ほど向上しており、コミュニティにとっても良い影響を及ぼすことができました。
We are hiring!!
コネヒトでは、プロダクトを成長させたいMLエンジニアを募集しています!!(切実に募集しています!)
- ライフイベント、ライフスタイルの課題解決をするサービスに興味がある方
- 機械学習の社会実装、プロダクト開発に興味のある方
是非お話できれば嬉しいです!
カジュアル面談では答えられる範囲でなんでも答えます!(特に準備はいりません!)
自分のTwitter宛てにDM送っていただいてもOKですし、下記リンクからお気軽にご連絡お待ちしています!
www.wantedly.com 大規模データを活用してサービスの成長にコミットする機械学習エンジニア募集! by コネヒト株式会社
*1:今回のモデルは違反確率を出力するものになっているので、閾値を決める必要があります