この記事はコネヒトアドベントカレンダー2022の6日目の記事です。
こんにちは。2017年11月にAndroidエンジニアとしてjoinした@katsutomuです。
前回のエントリーで、髪の毛のアップデート予定について触れましたが、今は黒髪7割金髪3割りといったところです。
さて今回は、コネヒトの開発組織で行われている定例的*1なMTGについて紹介させていただきます。
目次
- 目次
- コネヒト開発組織の定例的MTGはどんなものか?
- 対象読者
- MTGの変遷
- 一歩MTG時代 2018年 ~ 2019年
- 戦略MTG時代 2019年 ~ 2021年
- ボックスMTG時代 2021年 ~ 現在
- コネヒトの強いカルチャー
- 最後に
コネヒト開発組織の定例的MTGはどんなものか?
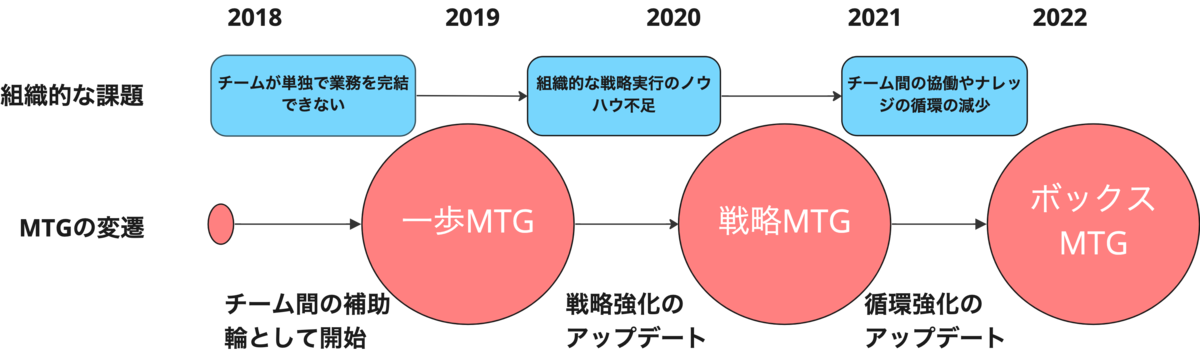
コネヒトでは2018年ごろから、エンジニア全員が参加する定例的なMTGを実施しています。定例的なMTGは、ともすれば形骸化しがちですが、コネヒトではその時々で注力する課題から目的を定め、定期的なアップデートを行っていきました。今回はその変遷を紹介しようと思います。
ぜひ皆さんに読んでいただきたいですが、以下の方に特に届けられたらと思います。
対象読者
- チームや部署間の情報同期の進め方にお悩みの方
- 定例に課題はないが、他社の事例を知りたいという方
- これから定例することが、決まっているが、やり方がわからない方
MTGの変遷
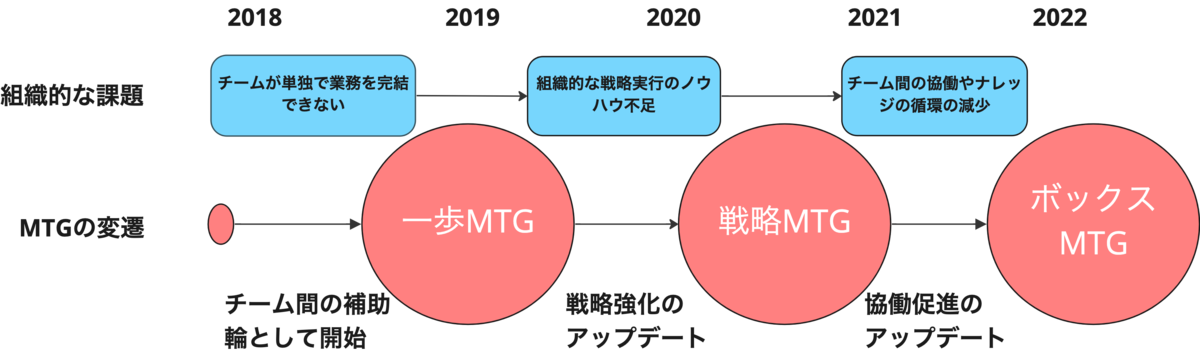
さて、まずはこれまでの定例の変遷を以下の図と表にまとめました。
| 名前 | 目的 | 時期 | 規模 | 内容 |
|---|---|---|---|---|
| 一歩MTG | •部署/チーム間の相談&課題解決 | 2018年 ~ 2019年 | スクラムチームが3。部署が1つ。 | • 各チームのやったことや、アピールしたいことを話す• みんなに質問・共有・相談• 周知事項共有 |
| 戦略MTG | • 戦略を実行精度を向上のための、課題の早期発見/早期対処 | 2019年 ~ 2021年 | チーム3~4。部署が2つ。 | • OKR進捗確認• 開発チームトピック共有• みんなに話したい!タイム |
| ボックスMTG | ・「なぜつくるか」「どうつくるか」のノウハウ展開・部署/チーム間のコラボのきっかけの場 | 2021年 ~ 2022年 | チーム4~6。部署が2つ。 | ・10分の共有・相談タイム*4枠・連絡共有事項 |
日々アップデートしながら、大体1~2年が経つころに、大幅なアップデートをしています。次のセクションでそれぞれの課題と背景をふまえて、MTGの内容を具体的に紹介していきますが、MTGに正解の形はなく、今回紹介するもベストなものばかりでは無いものの、少しでも思考の刺激になればと思います。
一歩MTG時代 2018年 ~ 2019年
課題と背景
スキルを網羅したチーム編成から、ミッションを元にしたチーム編成するように変更した時期です。同時に会社の規模が大きくなり、従来のスクラムの枠では収まらない仕事やプロジェクトが増え、単独のチームで業務を完結出来ないケースが増えてきました。その状況を踏まえ、部門全体の目標達成を円滑にするべく、横串で情報や課題を共有して、解像度を上げる場が必要でした。 ちなみに名前はママの一歩を支えるという弊社プロダクトのママリのミッションからつけています。
各チームでやったこと・これからやることシェア
名前の通り各チームが取り組んだ施策や結果を共有し、次に何をするかを同期していました。スクラムチームで、取り組んだワークショップを紹介することもありました。当初は各チームの代表者が読み上げていましたが、質問・相談の時間を増やすために、読み上げなしとしました。
みんなに質問・共有・相談したいことタイム
チームの連携周りやシステム全般に関わることを相談する時間です。
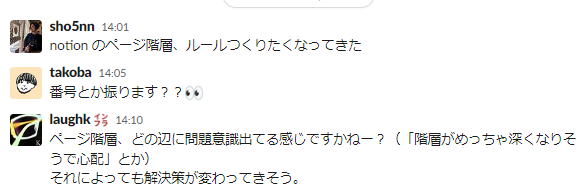
例えば、画像にあるように特定ブランチのライブラリアップデートの進め方どうする?ということを話していました。

戦略MTG時代 2019年 ~ 2021年
課題と背景
中期ビジョン策定がなされ、ビジョン実現のために戦略の重要度が高くなった時期でした。ビジョン実現を念頭に各部門戦略を策定し、実行の精度を上げることを組織的に力をかけ始めました。そのため部門の全体像を可視化し、課題の早期発見/早期対処を進める場が必要でした。
OKR進捗確認
半期毎のOKRの進捗状況を共有し、打ち手の検討をおこなっていました。事前に課題を書き、状況をみんなで点検し、対策を打ちやすくしていました。

テックビジョン小噺
テックビジョンが策定されたので、全員が理解度を深めコミットする状態を目指すために、CTOに質問をぶつけて、どのようにテックビジョンを実現するかの議論をするコーナです。以下のフォーマットで、CTOとメンバー全員で議論をしていました。
テックビジョンはIntroduction · Connehito Tech Visionを是非お読みください!

みんなに話したい!タイム
相談したいことや、共有したいことを話せる時間です。例えば、画像にあるようにアプリケーションエンジニアと、インフラエンジニアコミュニケーションの課題や、既存プロセスの改善などの相談が行われていました。

ボックスMTG時代 2021年 ~ 現在
課題と背景
単独チームで戦略を実行できるが増え、チームの独自性が高まったこ反面、OKR進捗共有が共有のための共有になる、ナレッジのサイロ化とチーム間の協働がゆるくなり始めました。ノウハウの循環が止まり、チーム内に閉ざされたことで、本来上げられたはずの成功確率が上がらない状態となっていました。この課題に対し、戦略MTGのみんなに話したい!タイムを強めた、話したいことを話したい人が話せる場としてアップデートを行いました。
コンセプト
💡 レンタルボックスを借りて、そのボックスの中で自分のお店を開くように色んな人が、 期間限定で臨時開設されるポップアップストアのように柔軟に、関わっていける場
目的
- 部門を跨いで情報を同期的にブロードキャストする場
- 「なぜつくるか(Why)」や「どうつくるか(How)」をノウハウとして展開する場
このやり方で、2021年前半からMTGを実施しています。具体的な進め方は以下の通りです。
かためな内容〜ゆるめな内容まで話される課題に向き合ったMTG
- 会場:Zoom
- 頻度:隔週
- 議事録:notion
- 進め方
- ボックス①~④を共有&議論(40分)
- ライトな共有周知事項&WinSession(10分)

ボックスと呼ばれる枠を10分×4つの自由枠を用意したことで、議題のバリエーションが増え、結果的に以前よりも部署・チームを跨いだコラボレーションの場として機能するようになったと感じています。なおボックスは、以下のガイドラインに従って事前に抑えます。せっかくなので議題のいくつか例示します。
このように組織全体の目標の話から、技術的、チーム的な運用面の課題提起・改善議論をできる場となっています。開発部オンボーディングのテンプレを作りたいというテーマでは以下の画像のように話し合いがされました。

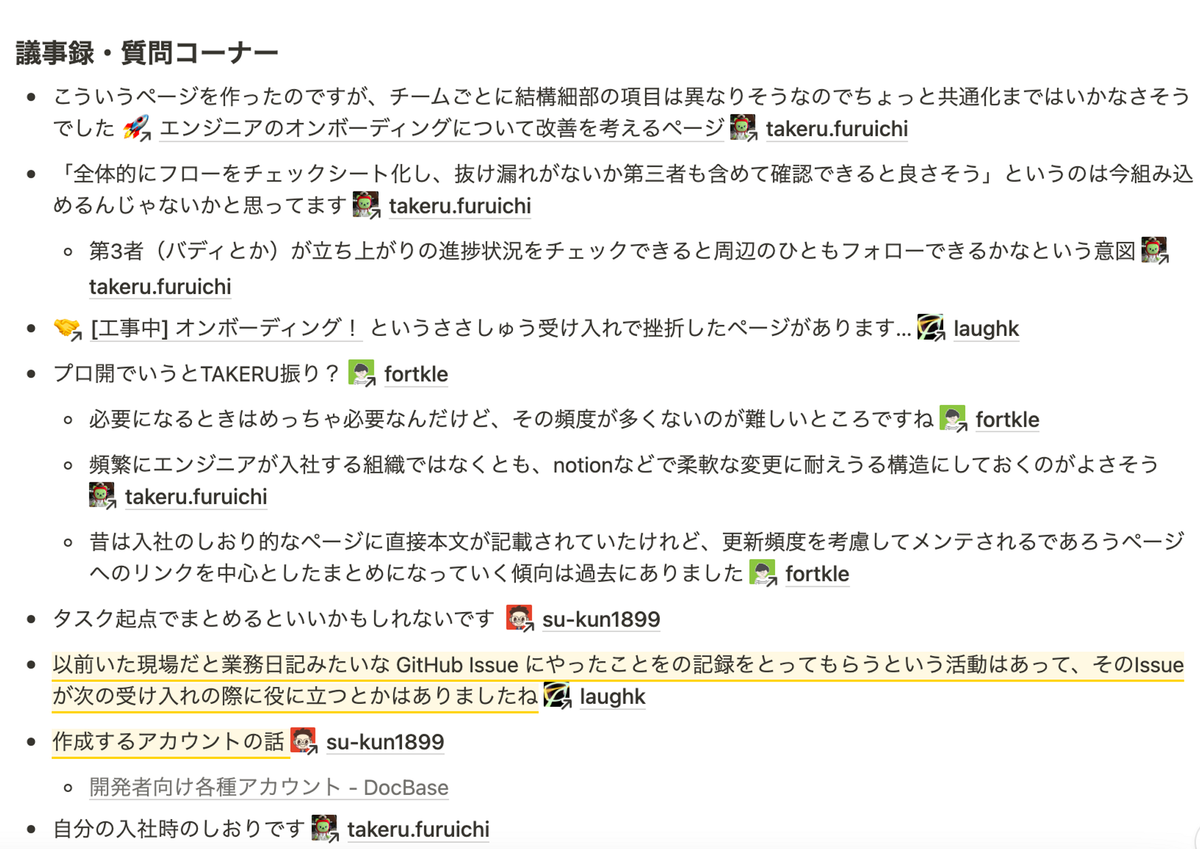 例示したように、チームや部署を跨いで相談し(少しでも)課題を解決するための場として機能していて、以前までの決まった方式でなく、ボックス方式にしたことで議題に柔軟性がでて、メンバーやチームが、それぞれの課題やアイディアをシェアし、コラボレーションを行う場になったと思います。細かい部分では、
例示したように、チームや部署を跨いで相談し(少しでも)課題を解決するための場として機能していて、以前までの決まった方式でなく、ボックス方式にしたことで議題に柔軟性がでて、メンバーやチームが、それぞれの課題やアイディアをシェアし、コラボレーションを行う場になったと思います。細かい部分では、議事録担当を持ち周りにする、不在メンバーのために録画を残しておくという工夫をしています。最近はボックスMTGの中で、各メンバーのGood Acitionを自薦・他薦で紹介するWin Sessionも実施しています。
コネヒトの強いカルチャー
改めて振り返ってみると、コネヒトの肯定から始めよう~Affirm&Follow~というカルチャーを強く感じられました。まずは肯定から初めて乗っかりやフィードバックをしていくことで、コトを進めていくカルチャーです。そのカルチャーとの相乗効果を高めるためにも、どのMTGでも全員が参加し議論するオープンさに拘り続けていました。いわゆる定例的なMTGは形骸化しがちで、参加する側が必要性を感じない環境も多いと思いますが、コネヒトの場合、定期的にMTGの役割をアップデートし、課題を放置せずにフォローし合う仲間がいることで、長い期間意義のあるMTGを作れていると思います。
最後に
今回は、エンジニア組織の定例MTGの変遷とフォーカスポイントを紹介させていただきました。同じような課題に悩んでいる方の参考になればと幸いです。
私自身も改めて振り返ってみたことで、組織の成長を実感できこれからのアップデートが、より楽しみになってきました。
最後までお読みいただき、ありがとうございました! 7日目はインフラエンジニアの @laugh_k の記事です。
日曜日には、Webエンジニアの@TOCが、チームで実施している別のボックスMTGの事例を紹介してくれます。どちらもお楽しみに〜〜〜!
*1:定例呼ぶのが好きでなく的をつけてます