みなさんこんにちは。MLチームのたかぱい(@takapy0210 )です。
本日は、コネヒトの運営するママリのオンボーディング改善に機械学習を活用した事例のパート2をお話をしようと思います。
パート1については以下エントリをご覧ください(取り組んだ背景なども以下のブログに記載しています)
tech.connehito.com
(おさらい)
今回実施しているオンボーディング改善には大きく分けて以下2つのステップがあります。
ステップ1:興味選択にどのようなトピックを掲示したら良いか?(前回のブログ参照)
ステップ2:興味選択したトピックに関連するアイテムをどのように計算(推薦)するか?
本エントリでは主にステップ2の内容についてお話しできればと思います。
目次
はじめに
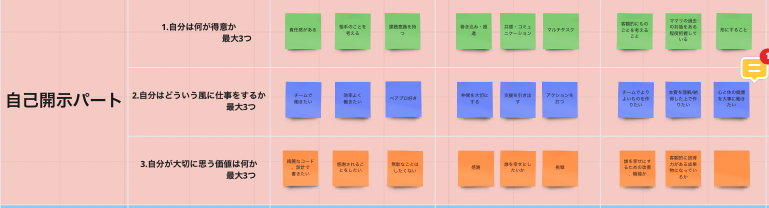
前回の記事 で触れたように、2022年09月時点では以下のようなトピックがオンボーディングで表示され、ユーザーの好みを取得しています。
オンボーディングで表示されるトピック選択画面
ここで選択されたトピックに対して、どのようにしてアイテムを推薦すれば良いでしょうか?
まず最初に考えられるのはルールベースによる推薦だと思います。
ルールベースの推薦
一般的に、機械学習をプロダクトへ導入する際、まずはシンプルなベースラインを作成してそこから徐々に改善 していく、というフローを踏むと良いと言われています。
今回も例に漏れず、まずはルールベースのアプローチでベースラインを作成しました。
このルールベースによるアプローチでは機械学習は一切使わず、オンボーディング時に選択したトピックに対して、そのトピックが付与されているアイテム(質問のこと。以降アイテム = 質問として記載します)を新着順に推薦する、というものです。
例えば、「つわり」を選択したユーザーに対しては、「つわり」タグが付与されているアイテムを新しい順に推薦します。
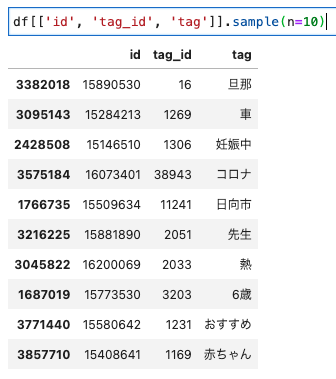
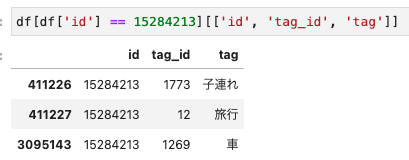
以下にあるように、ママリでは各アイテムごとに紐づくタグデータを保持しています。このタグは正規表現で付与されているため、アイテム本文に該当文字列がある場合に付与されます
ルールベースの課題
上記画像の文章を見ていただくとわかると思うのですが、このアイテムの主題は「保育園」ではなく「仕事」です。例えばこのアイテムが「保育園」に興味のあるユーザーに推薦された場合、ユーザー体験はあまり良くないと考えられます。
このように、単純なルールベースでアイテムを推薦すると、ユーザーが期待しているアイテムとは異なるアイテムが推薦される可能性があり、これが1つの課題となっていました。
これを改善すべく機械学習を用いたアプローチの検証をしていきました。
機械学習を用いたアプローチ
今回は、各タグのEmbeddingが計算できればタグ同士の類似度を計算することができ、そこからタグとアイテムとの類似性も良いものが計算できるのではないか、という仮説のもと、Graph Embedding(後述)を用いて実験していきました。
Embeddingは、レコメンデーションをはじめとして活用できる幅が広いというのも採用理由の1つです。
blog.twitter.com
Graph Embeddingとは
Graph Embeddingとはグラフをベクトル空間に落とし込む手法のことで、大きく以下の2つに分けられます
詳しく知りたい方は以下の記事が参考になると思います。
towardsdatascience.com
今回はnode2vecというアプローチを用いて、前述した「タグ」の埋め込み表現を計算していきます。
arxiv.org
node2vecの概略
今回の手法では、大きく分けて以下のステップでノードのベクトルを計算します。
グラフ上をランダムウォークし、シークエンスデータを生成する
生成したシークエンスデータを学習データとして、教師なし学習を行う
学習した結果からノードのベクトルを取得する
ざっくり以下のようなイメージです。
https://towardsdatascience.com/graph-embeddings-the-summary-cc6075aba007 より
本論文のオリジナルな部分はステップ1の部分で、「どのようにランダムウォークしてデータをサンプリングするか」という部分にあります。
詳細はGMOさんの記事が分かりやすいので、是非こちらをご覧いただければと思います。
recruit.gmo.jp
node2vecの実装
実際にPythonを用いて実装していきます。
使用データ
今回使用したデータは以下のような形式になっています
id:アイテムID
tag_id:タグID
tag:タグの名称
1つのアイテムIDに複数のタグが紐づいているイメージです
1. グラフ上をランダムウォークし、シークエンスデータを生成する
まずはNetworkX を用いてグラフを生成します。
今回は前述した「タグ」をノードとしてグラフを生成していきます。同じアイテムに紐づくタグがある場合は、それらのノードをエッジで接続してグラフを生成していきます。
ただ、関連性の薄い(自己相互情報量が少ない)タグ同士についてはグラフに追加しないように調整しています。
def create_tag_graph (input_df: pd.DataFrame) -> Any:
"""タググラフの構築
エッジの重みは、2つのタグ間の点ごとの相互情報に基づいており、次のように計算されます
log(xy) - log(x) - log(y) + log(D)
xy は、タグ x とタグ y の両方が付与されているアイテムの数
x は、タグ x が付与されているアイテムの数
y は、タグ y が付与されているアイテムの数
D は、タグの総数
"""
pair_frequency = defaultdict(int )
item_frequency = defaultdict(int )
tags_grouped_by_qid = list (input_df.groupby("id" ))
for group in tqdm(tags_grouped_by_qid, position=0 , leave=True , dynamic_ncols=True , desc="Compute tag frequencies" ):
current_tags = list (group[1 ]["tag" ])
for i in range (len (current_tags)):
item_frequency[current_tags[i]] += 1
for j in range (i + 1 , len (current_tags)):
x = min (current_tags[i], current_tags[j])
y = max (current_tags[i], current_tags[j])
pair_frequency[(x, y)] += 1
D = math.log(sum (item_frequency.values()))
tags_graph = nx.Graph()
for pair in tqdm(pair_frequency, position=0 , leave=True , dynamic_ncols=True , desc="Creating the tag graph" ):
x, y = pair
xy_frequency = pair_frequency[pair]
x_frequency = item_frequency[x]
y_frequency = item_frequency[y]
pmi = math.log(xy_frequency) - math.log(x_frequency) - math.log(y_frequency) + D
weight = pmi * xy_frequency
if weight >= 10 :
tags_graph.add_edge(x, y, weight=weight)
return tags_graph
tag_graph = create_tag_graph(input_df=df[['id' , 'tag' ]])
print (f"Total number of graph nodes: {tag_graph.number_of_nodes()}" )
print (f"Total number of graph edges: {tag_graph.number_of_edges()}" )
>> Total number of graph nodes: 7276
>> Total number of graph edges: 312634
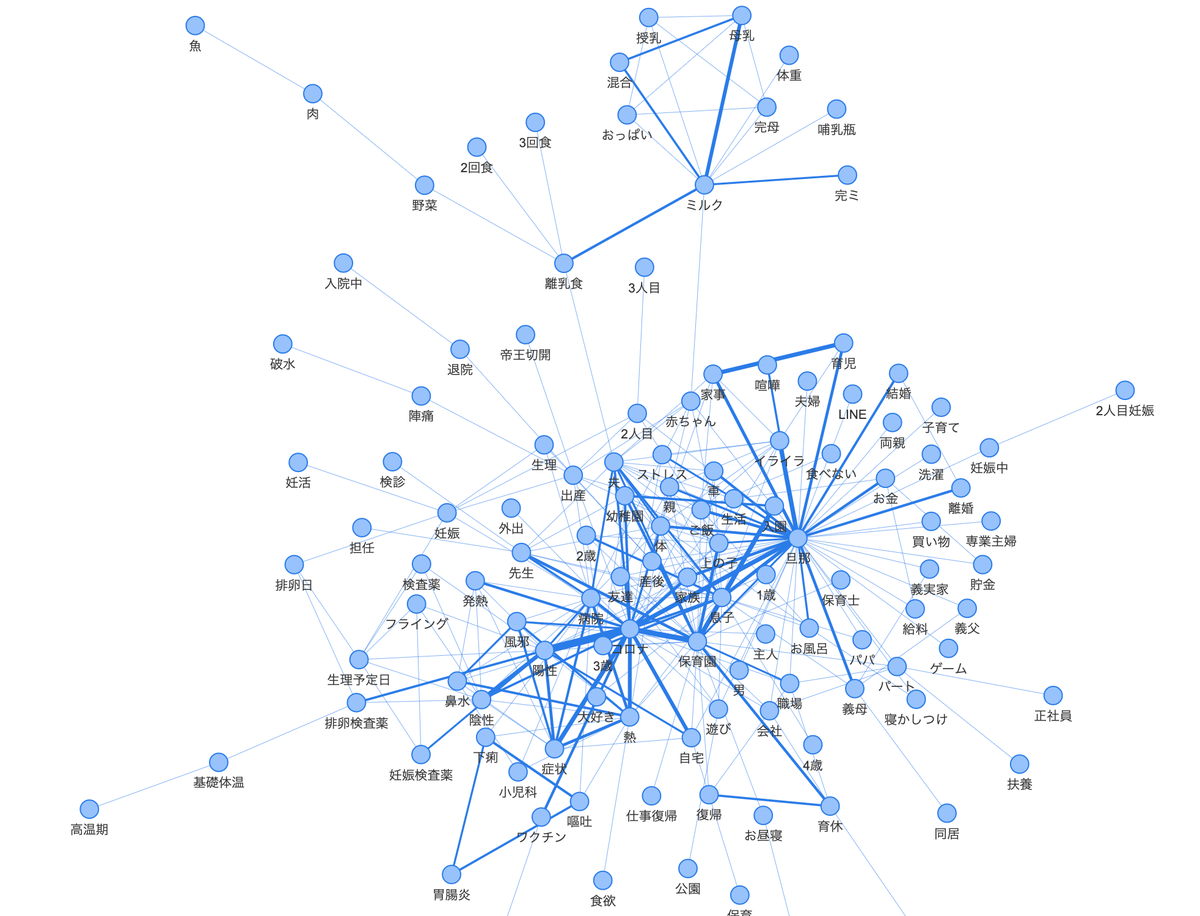
生成されるグラフは以下のようなイメージです
生成されるタググラフイメージ
次にこのグラフを、前述したnode2vecで提案された手法でランダムウォークし、シークエンスデータを生成します。
def next_step (graph: Any, previous: str , current: str , p: int , q: int ) -> str :
"""ランダムウォークで次に進むノードを選択する
"""
neighbors = list (graph.neighbors(current))
weights = []
for neighbor in neighbors:
if neighbor == previous:
weights.append(graph[current][neighbor]["weight" ] / p)
elif graph.has_edge(neighbor, previous):
weights.append(graph[current][neighbor]["weight" ])
else :
weights.append(graph[current][neighbor]["weight" ] / q)
weight_sum = sum (weights)
probabilities = [weight / weight_sum for weight in weights]
next = np.random.choice(neighbors, size=1 , p=probabilities)[0 ]
return next
def random_walk (graph: Any, num_walks: int , num_steps: int , p: int , q: int ) -> list :
"""グラフをランダムウォークし時系列データを取得する
"""
walks = []
nodes = list (graph.nodes())
for walk_iteration in range (num_walks):
random.shuffle(nodes)
for node in tqdm(nodes, position=0 , leave=True , dynamic_ncols=True ,
desc=f"Random walks iteration {walk_iteration + 1} of {num_walks}" ):
walk = [node]
while len (walk) < num_steps:
current = walk[-1 ]
previous = walk[-2 ] if len (walk) > 1 else None
next = next_step(graph, previous, current, p, q)
walk.append(next )
walks.append(walk)
return walks
tag_series = random_walk(graph=tag_graph, num_walks=10 , num_steps=10 , p=2 , q=3 )
ここで生成されるデータは以下のようなリストとなっています。
node2vecで生成されるデータイメージ
ニュアンスの似ているタグが近傍に存在していることが定性的に見て分かると思います。
2. 教師なし学習でノードの情報をベクトル化する
今回はgensimを用いて、自然言語処理ではおなじみのskip-gramという手法でベクトル化していきます。
tag_embedding_model = Word2Vec(
tag_series,
vector_size=100 ,
window=3 ,
hs=1 ,
min_count=1 ,
sg=1 ,
workers=multiprocessing.cpu_count(),
seed=42
)
定性的にチェックしてみる
ここまででタグのベクトルが計算できたので、類似タグを見ながらモデルの良し悪しを定性的にチェックしてみます。
つわり
ベビーグッズ
練馬区
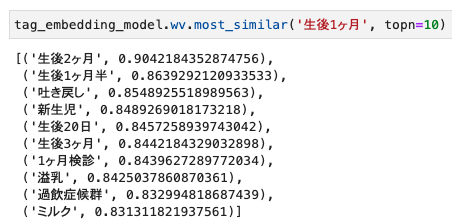
生後1ヶ月
定性的には良さそうなベクトルが計算できていそうです。
ランダムシークエンスとnode2vecの比較
ランダムにシークエンスデータを生成した場合と、node2vecの手法でシークエンスデータを生成した場合にできるモデルにどのくらい違いがあるのか?という部分についても簡単に触れておこうと思います。
同じデータを使用し、アイテムに紐づくタグをそのままリストに変換します。(これでランダムシークエンスデータが生成できる)
sequence_df = pd.DataFrame(df.groupby(['id' ])['tag' ].apply(list )).reset_index()
sequence_df['tag_length' ] = sequence_df['tag' ].apply(lambda x: len (x))
sequence_df = sequence_df[sequence_df['tag_length' ] > 3 ].reset_index(drop=True )
tag_series = sequence_df['tag' ].tolist()
先ほど同様、リスト形式のデータを生成しました。
ここで生成されたデータは以下のようになっています。
ランダムに作成したシークエンスデータ例
このデータを同じようにskip-gramモデルで学習させて、モデルの定性チェックをしてみます。
tag_embedding_model = Word2Vec(
tag_series,
vector_size=100 ,
window=3 ,
hs=1 ,
min_count=1 ,
sg=1 ,
workers=multiprocessing.cpu_count(),
seed=42
)
左がnode2vecのシークエンスデータで学習させたもの、右がランダムシークエンスデータで学習させたものになります。
つわり
ベビーグッズ
練馬区
生後1ヶ月
「つわり」や「ベビーグッズ」に関してはそこまで差分がないですが、「練馬区」や「生後1ヶ月」といったタグに関しては、大きな差分が見られます。
今回はskip-gramというアルゴリズムを利用している性質上、シークエンスデータで見た時に周辺にくる単語が似ているものであれば、類似度が高くなる傾向にあります。
例えば、ランダムシークエンスデータで生成した「練馬区」ベクトルに関しては、東京都内の市や区が類似タグとして計算されていますが、ここで計算されてほしいのは「練馬区に関連するタグ」なので、node2vecの方が良いベクトルを計算できていることが分かります。(桜台マタニティクリニック / 久保田産婦人科病院 / 練馬病院 はどれも練馬区にあるクリニックであり、大塚産婦人科は練馬区からちょっとだけ離れた場所にあるクリニックです)
ママリで投稿されるデータには以下のようなものも多く、そのままアイテムに紐づくタグを用いてデータを生成すると、どうしても地理的に近くの区や市が類似タグとして計算される傾向にあります。
タグとアイテムの類似度算出
最後に、タグとアイテムの類似度を計算し、オンボーディングで選択した興味トピックに対して、どのアイテムを推薦するかを算出します。
アイテムのベクトル計算にはSWEM を利用し、アイテムに紐づくタグベクトルから、アイテムのベクトルを算出しました。
これらを用いて、タグベクトルとアイテムベクトルのコサイン類似度を計算し、オンボーディングで選択した興味トピックと類似しているであろうタグが付与されているアイテムを推薦するようにしました。
例えば、2022年09月現在「つわり」を選択したユーザーに対しては以下のようなアイテムが推薦されます。
「つわり」を興味選択したユーザーに推薦するアイテム例
ここではサラッと「タグとアイテムの類似度を計算して推薦しています」と書いていますが、実際はPdMとデータを泥臭く見ながらパラメータの調整などをしていきました。
最終的には以下のようなスプレッドシートが数枚できあがり、どのパラメータで生成されたアイテムが良いのだろうか、というのを定性的にチェックしていきました。
どのトピックを選ぶとどんなアイテムが推薦されるのか?を泥臭くチェックしている様子
結果はどうだった?
抽象的な数値になってしまいますが、アプリインストール初日ユーザーのアイテムクリック系の指標が、ルールベースと比較して1.5倍ほど向上 しました 🎉
現在は機械学習のロジックを全ユーザーに適用し運用しています。
最後に
オンボーディング改善の内容は、PyCon 2022でも詳細をお話する予定なので、興味がある方は是非観にきてください! (登壇日時は10月14日(金)の17時10分〜17時40分に決まりました!)
2022.pycon.jp
We Are Hiring !!
コネヒトでは一緒に働く仲間を募集しています!
www.wantedly.com
機械学習に関しては、過去の取り組み事例などを以下にまとめていますので、是非見てみてください!
tech.connehito.com
そして興味持っていただけた方はカジュアルにお話しましょう! (TwitterのDMでもMeety経由でも、気軽にご連絡ください)