こんにちは!コネヒトでiOSエンジニアをやっていますyanamuraです。
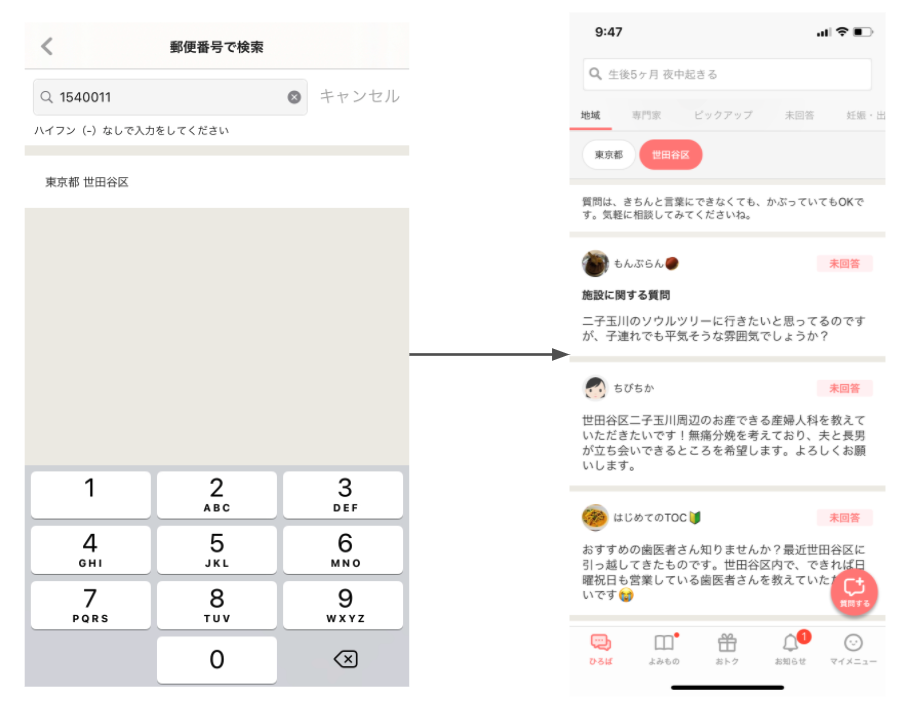
コネヒトで開発しているママリのiOSアプリでもSwiftUIを使い始めました。 なるべく新しい部分はSwiftUIでつくっていくぞ!ということで、こちらのハーフモーダルの部分をSwiftUIで実装しました。
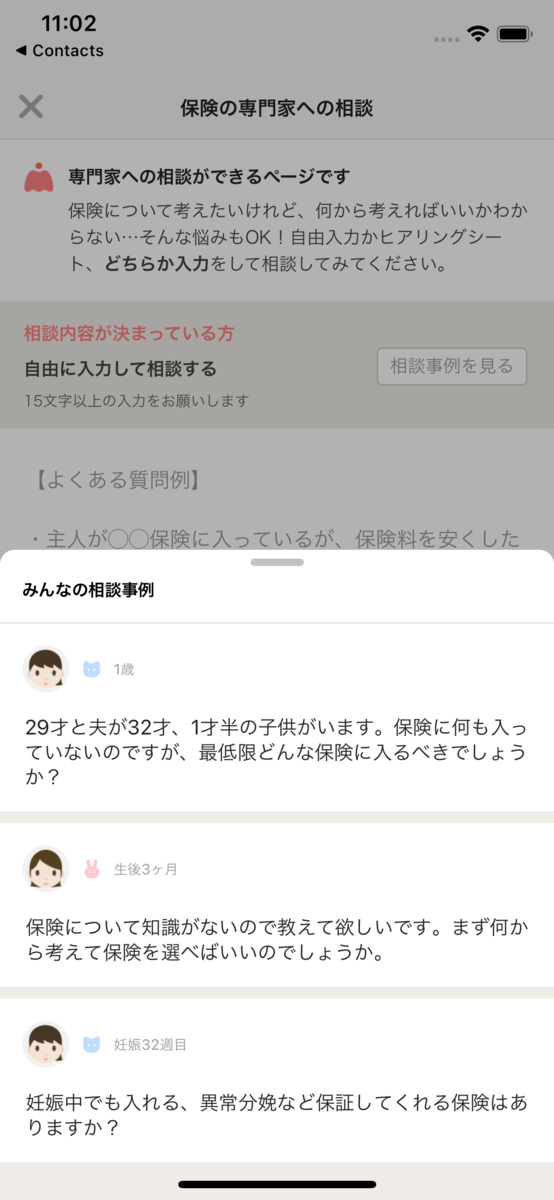
ハーフモーダルといえばiOS15からはUISheetPresentationControllerで実装できますが、まだiOS13をサポートしているのでFloatingPanelを利用しました。
導入自体はとても簡単でFloatingPanelControllerに表示したいSwiftUIのViewをUIHostingControllerでラップしたものをset(contentViewController: )して表示するだけです。 しかし、ただ一点、FloatingPanelControllerにSwiftUIのscrollViewをどうやって渡すかという問題が発生します。
import SwiftUI import FloatingPanel final class ViewController: UIViewController { @IBAction func buttonTap(_ sender: Any) { let fpc = FloatingPanelController() let contentView = ContentView() // ContentViewはSwiftUI let contentViewController = UIHostingController(rootView: contentView) fpc.set(contentViewController: contentViewController) // fpc.track(scrollView: scrollView) // SwiftUIからscrollViewをどうやって取得する?! present(fpc, animated: true) } }
解決方法は色々あると思います。 FloatingPanelのExampleにもあったり、手段を問わずにscrollViewを取得するのであればintrospectを使うという手もあります。
ここでは、シンプルに自前でScrollViewをつくるやり方でやってみます。
まず、このように自前でUIScrollViewを使ってSwiftUI版のScrollViewを自作します。 ポイントとしては引数のcallbackでscrollViewを呼び出し元に渡せるようになっています。
struct CustomScrollView<Content: View>: UIViewRepresentable { private let scrollView = UIScrollView() private let content: UIView init(callback: (UIScrollView) -> Void, @ViewBuilder content: () -> Content) { self.content = UIHostingController(rootView: content()).view self.content.backgroundColor = .clear callback(scrollView) } func makeUIView(context: Context) -> UIView { content.translatesAutoresizingMaskIntoConstraints = false scrollView.addSubview(content) let constraints = [ content.leadingAnchor.constraint(equalTo: scrollView.leadingAnchor), content.trailingAnchor.constraint(equalTo: scrollView.trailingAnchor), content.topAnchor.constraint(equalTo: scrollView.contentLayoutGuide.topAnchor), content.bottomAnchor.constraint(equalTo: scrollView.contentLayoutGuide.bottomAnchor), ] scrollView.addConstraints(constraints) return scrollView } func updateUIView(_ uiView: UIView, context: Context) {} }
FloatingPanelに表示するViewをつくる場合はこのようにScrollViewの代わりに自作のCustomScrollViewを使うようにします。
struct ContentView: View { let scrollViewCallback: (UIScrollView) -> Void private let animalList = ["dog", "cat", "lion", "snake", "wolf", "bird", "gorilla", "zebra", "koala"] var body: some View { CustomScrollView(callback: scrollViewCallback) { VStack { ForEach(animalList, id: \.self) { animal in Text(animal) .font(.system(size: 18)) .padding(20) } } } } }
あとはContentViewを生成するときに渡すcallback内でtrack(scrollView:)を呼ぶようにすれば完了です。
final class ViewController: UIViewController { @IBAction func buttonTap(_ sender: Any) { let fpc = FloatingPanelController() let contentView = ContentView { scrollView in fpc.track(scrollView: scrollView) // ここでscrollViewをセットする } let contentViewController = UIHostingController(rootView: contentView) fpc.set(contentViewController: contentViewController) present(fpc, animated: true) } }
SwiftUIを部分的にとりいれるときは、UIKit,SwiftUIのそれぞれのView間での相互の依存が発生しないようなところでやるとハマりどころが少ないかもですね!