みなさんこんにちは。たかぱい(@takapy0210)です。
気づけばもう6月ですね。2021年の半分が過ぎようとしています。もう半分.....もう...。
はじめに
みなさんデータ分析環境はどのように構築していますか?
Gunosyさんのブログ*1にもあるように、環境構築方法は様々あると思います。
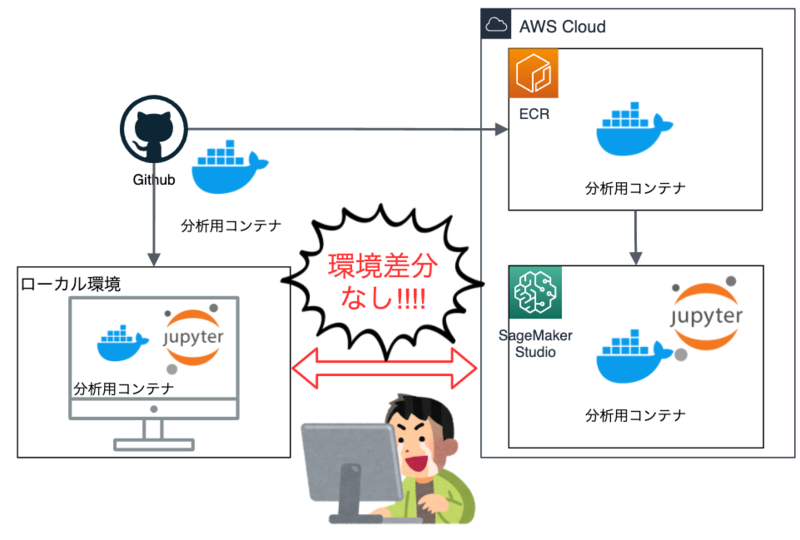
本エントリでは、ローカルとクラウド(AWS SageMaker Studio)のデータ分析環境をコンテナで構築し、環境差分の無い快適なデータ分析ライフを過ごすTipsについてご紹介しようと思います。
これにより軽量な分析はローカル環境でサクッと、重めの分析はクラウド環境(AWS SageMaker Studio)で強いコンピューティングリソースを用いてじっくりとやる、といったことを環境差分を気にせず行うことができます。
ちなみに、ローカルで起動する際はdocker compose up -d jupyterlabコマンドを叩くだけ、SageMakerで起動する際はGUI上でポチポチっと数回クリックすると同じ環境が起動できたりします。
dockerなどの詳細には触れませんのでdockerドキュメントやgoogleなどで調べてみてください。
目次
AWS SageMaker Studioとは
まずAWS SageMaker Studioについて簡単にご紹介します。(以降の記載はSageMakerに省略します)
SageMakerは、機械学習のための統合開発環境 (IDE) と謳われており、慣れ親しんだnotebookを起動してデータ分析・モデル構築ができるのはもちろん、ホストされたエンドポイントにモデルのデプロイするといったことも可能なマネージドサービスです。(公式ドキュメント)
デフォルトではAWSが用意してくれているコンテナイメージをベースにnotebookを起動できます。
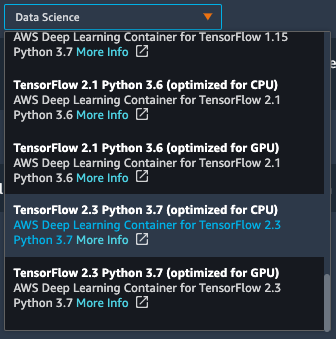
コンピューティングリソースに関しても様々な種類のインスタンスが用意されており、使いたいインスタンスをGUI上で選択し、数分待つとnotebookが起動できたりと、手軽に環境構築することができます。
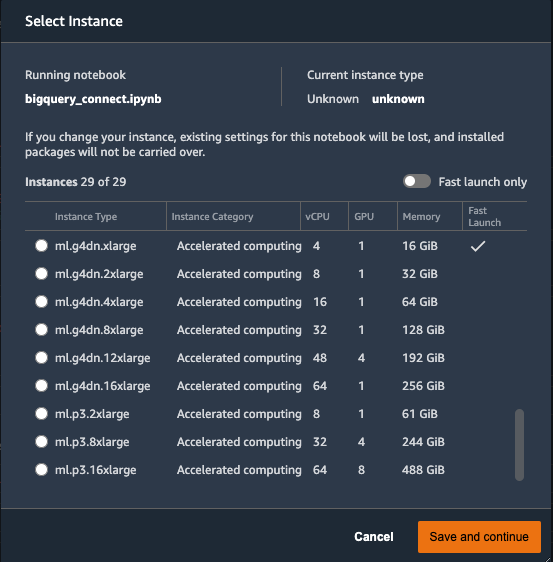
しかし、用意されているコンテナイメージでは使いたいライブラリがインストールされていなかったり、違うpythonのバージョンを使いたい、といった要望もあると思います。
(SageMakerを起動する時に毎回pip installしても良いのですが、なかなか煩雑ですよね...)
そこで、カスタムコンテナイメージを用いることで上記のような課題を解決できます。
カスタムコンテナイメージを用いるメリット
上記でも述べましたが、AWSが用意しているコンテナイメージに存在しないライブラリだったり、使いたいpythonのバージョンをSageMaker上で使用することができます。
また、複数人のMLエンジニアやデータサイエンティストがいる場合においては、dockerfile群を共有しdocker compose buildするだけで手間なく同じ分析環境が構築でき、「Aさんの環境とBさんの環境で分析結果や挙動が異なる・・・」みたいなことを防ぐこともできます。
使用するDockerfile群について
まずはローカル環境を構築するために、以下3つのファイルを用意します。
- Dockerfile
- docker-compose.yml
- jupyter_notebook_config.py
以降でそれぞれのファイルの詳細についてご紹介します。
(掲載しているコードはサンプルとして適宜省略しています)
Dockerfile
ポイントは以下2点です。
jupyter_notebook_config.pyファイルを用いることでシンプルなコマンドでjupyterが起動できるようにする(jupyter notebook --port 8888 --ip="0.0.0.0" --allow-rootみたいな長ったらしいコマンド叩くの嫌ですよね...)
python3 -m ipykernel install --sys-prefixコマンドでSageMakerから認識できるようにする。
FROM python:3.8
LABEL hoge <hoge@fuga.com>
RUN apt-get -y update && apt-get install -y --no-install-recommends \
mecab \
libmecab-dev \
mecab-ipadic \
mecab-ipadic-utf8 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# jupyter lab
RUN pip3 install -U pip && \
pip3 install jupyterlab && \
pip3 install jupyterlab-git && \
mkdir ~/.jupyter
COPY ./jupyter_notebook_config.py /root/.jupyter/jupyter_notebook_config.py
# requirements.lockにインストールしたいライブラリを記載する
# python3 -m ipykernel install --sys-prefix がないと、SageMakerがpython3.8を認識してくれないので注意
COPY requirements.lock /tmp/requirements.lock
RUN python3 -m pip install -r /tmp/requirements.lock && \
python3 -m ipykernel install --sys-prefix && \
rm /tmp/requirements.lock && \
rm -rf /root/.cache
COPY working /opt/program/working
WORKDIR /opt/program/working
docker-compose.yml
下記のようなイメージです。
version: '3.4'
x-template: &template
build:
context: .
volumes:
- ./working:/opt/program/working:cached
services:
jupyterlab:
container_name: 'jupyterlab'
image: jupyterlab:latest
user: root
ports:
- "8999:8999"
command: jupyter lab --allow-root
<<: *template
jupyter_notebook_config.py
下記のようなイメージです。
c.NotebookApp.passwordにはjupyterlab起動時に入力するパスワードを設定できます。(本サンプルでは「password」となっています)
c = get_config()
c.NotebookApp.ip = '0.0.0.0'
c.NotebookApp.open_browser = False
c.NotebookApp.port = 8999
c.NotebookApp.notebook_dir = '/opt/program/working/'
c.LabApp.user_settings_dir = '/opt/program/working/jupyterlab/user-settings'
c.LabApp.workspaces_dir = '/opt/program/jupyterlab/workspaces'
c.NotebookApp.password = u'sha1:63cae364b3cd:c4319cba1eeb1bcf011a7d3fabd6448f95ae18c5'
ここまで準備ができたら、あとはdocker compose up -d jupyterlabコマンドを実行した後、ローカルのブラウザでhttp://127.0.0.1:8999/labにアクセスすればjupyterLabが使えます。
次に、このコンテナイメージをSageMaker上で使う方法についてご紹介します。
SageMaker でカスタムコンテナイメージを起動する方法
SageMakerで使用するためには、追加で以下2つのファイルが必要になります。
- app-image-config-input.json
- update-domain-input.json
それぞれの役割について簡単にご紹介します。
このconfigファイルには、SageMakerで使用する際のカーネル名やマウントディレクトリを定義します。
KernelSpecsのNameに設定する値は、コンテナイメージをローカルで起動した後jupyter-kernelspec listを実行した際に表示されるカーネルの中から選択する必要があります。(詳しい手順はこちらをご参照ください)
{
"AppImageConfigName": "ml-image-name",
"KernelGatewayImageConfig": {
"KernelSpecs": [
{
"Name": "python3",
"DisplayName": "Python 3"
}
],
"FileSystemConfig": {
"MountPath": "/root/data",
"DefaultUid": 0,
"DefaultGid": 0
}
}
}
update-domain-input.json
これはコンテナイメージをドメイン(≒ Sagamaker Studio)にアタッチするために必要なファイルです。
DomainIdには、AWSコンソール上で表示されるStudio IDを設定してください。
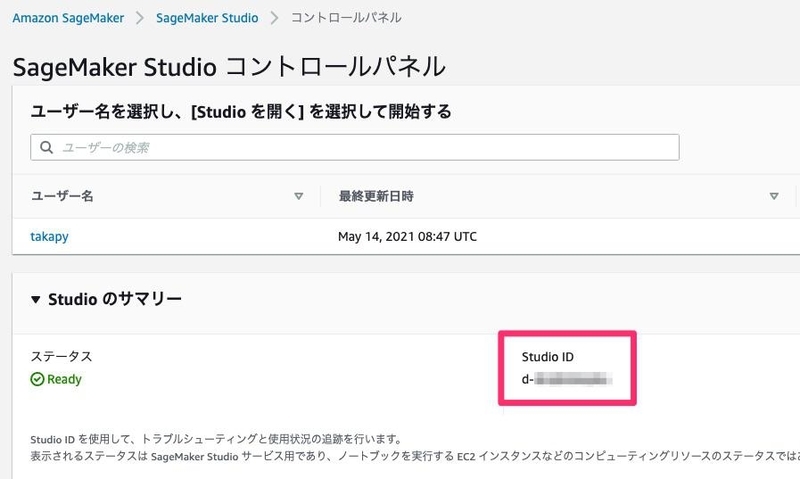
また、AppImageConfigName には、app-image-config-input.jsonで定義したものと同値を設定する必要があります。
{
"DomainId": "d-hogehoge",
"DefaultUserSettings": {
"KernelGatewayAppSettings": {
"CustomImages": [
{
"ImageName": "ml-analysis",
"AppImageConfigName": "ml-image-name"
}
]
}
}
}
SageMakerへ登録
上記2つのファイルを作成できたら、あとは以下のようなスクリプトを実行して、コンテナのビルド→ECR push→SageMakerへのアタッチを行います。
REGION="AWSのリージョン"
ACCOUNT_ID="AWSのアカウントID"
REPOSITORY_NAME="ml-analysis"
TAG_NAME="ml-analysis"
ROLE_ARN="arn:aws:iam::${ACCOUNT_ID}:role/service-role/hoge"
docker build -t ${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com/${REPOSITORY_NAME}:${TAG_NAME} .
aws ecr get-login-password --region ${REGION} | docker login --username AWS --password-stdin ${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com
docker push ${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com/${REPOSITORY_NAME}:${TAG_NAME}
aws --region ${REGION} sagemaker create-image \
--image-name ${TAG_NAME} \
--role-arn ${ROLE_ARN}
aws --region ${REGION} sagemaker create-image-version \
--image-name ${TAG_NAME} \
--base-image "${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com/${REPOSITORY_NAME}:${TAG_NAME}"
aws --region ${REGION} sagemaker create-app-image-config --cli-input-json file://sagemaker/app-image-config-input.json
aws --region ${REGION} sagemaker update-domain --cli-input-json file://sagemaker/update-domain-input.json
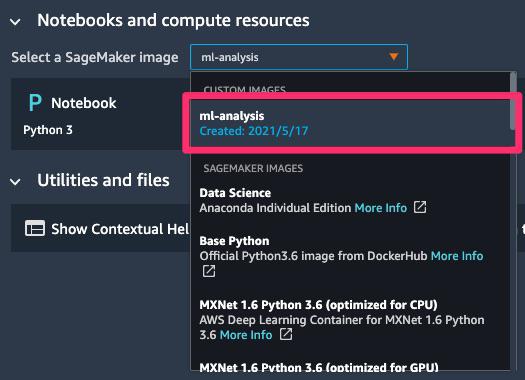
ここまでで、下記のようにSageMakerコンソール上からイメージがアタッチされていることを確認できます。

あとはSageMaker Studioを起動して、アタッチされたイメージを選択してnotebookを起動するだけで、ローカルと同一環境がSageMaker上で実現できます 🎉🎉🎉
SageMakerを使う際に気をつけたいこと
前述してきたように、SageMakerを使う際のメリットはいくつかあります。
- 豊富なコンピューティングリソースを用いて分析・モデリングできる
- notebookが動く環境が既に用意されているので環境構築が比較的容易
- 付随するマネージドサービスが豊富にある(本記事では触れませんが、FeatureStore, Experiments, Pipelineなどがあります)
しかし、注意点もあるので最後にまとめておこうと思います。
油断すると結構お金がかかる
はい。油断すると結構お金がかかります(汗)
SageMakerは従量課金のマネージドサービスで、主に以下2点で課金されます。
- notebookなどのインスタンス起動時間
- マウントされているEFSの容量
notebookなどのインスタンス起動時間
使用していないインスタンスは停止させたり、業務終了時にインスタンスを落とすなどの対策すれば大丈夫だと思います。
例えば、ml.t3.2xlarge(8vCUP/メモリ32GiB)のインスタンスは0.522USD/hなので、1ヶ月(約720h)起動させたままにすると375USD(約4万円)コストがかかります。
「深夜に終わる想定の学習回しちゃったら朝までお金かかっちゃうのか...」と思われる方もいると思いますが、SageMakerには ProcessingJobやTrainingJobといった機能もあり、これらはJobが終了すると自動的にインスタンスが落ちてくれるので、併せて使ってみると良いと思います。(この辺りのことも後日記事にできればと思っています)
(詳細な料金は公式ドキュメントを参照してください)
マウントされているEFSの容量
こちらは容量単位で課金されます。
ここで注意したいのが、SageMaker notebook上からファイルを削除すると、notebook上からは削除されているように見えるのですがTrashに残っていたりします。
特に機械学習やデータ分析においては容量の大きいファイルを多用することになると思うので、これを放置しておくと無駄に課金されてしまうリスクがあります。
SageMaker上でターミナルを起動しdf -hコマンドを実行すると現在どのくらいの容量を使っているかが把握できるので、定期的にチェックすることをオススメします。
(下記例だと、936MBのEFSボリュームを使っていることになります)
$ df -h
Filesystem Size Used Avail Use% Mounted on
overlay 17G 52K 17G 1% /
tmpfs 64M 0 64M 0% /dev
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
shm 64M 0 64M 0% /dev/shm
127.0.0.1:/200005 8.0E 936M 8.0E 1% /home/sagemaker-user
/dev/nvme0n1p1 83G 8.8G 75G 11% /etc/hosts
devtmpfs 1.9G 0 1.9G 0% /dev/tty
tmpfs 1.9G 0 1.9G 0% /proc/acpi
tmpfs 1.9G 0 1.9G 0% /sys/firmware
上記で表示される容量にはTrash(ゴミ箱)にあるファイルも含まれているので、notebook上から削除したファイルはrmコマンドで完全に削除する必要があります。
なので、不要なファイルをSageMaker notebook上から削除した際にはrmコマンドも実行するように意識しておくと良いです。
$ ls -al -h ~/.local/share/Trash/files
rm -rf ~/.local/share/Trash/files/*
(EFSの詳細な料金については公式ドキュメントを参照してください)
最後に
最近はAWSからも機械学習系のサービスが頻繁にローンチ・アップデートされており、SageMakerもここ数年でかなり機能強化されています。
とはいえ、まだまだ公開されている事例が少ないとも感じているので、業務で得た知見などは積極的にアウトプットしていければと思っています。
みなさんも良い分析ライフをお楽しみください!