こんにちは!バックエンドエンジニアのjunyaUと申します。
実は9月入社で入社してから1ヶ月も経っていない(執筆当時)のですが、テックブログを書かせていただけるのは本当にありがたい環境だな〜とヒシヒシと感じております。
最近、プライベートではもっぱら自作OSの開発をしており、時間があっという間に溶けてしまいご飯をちゃんと食べれていないのが悩みです。
今回は並行処理と並列処理の違いをコンテキストの観点から考えて、両者がどのように違うのかを考察していこうと思います〜!
はじめに
なぜ記事を書こうと思ったのか
数年前、私が学生だった頃に初めてGoを触り、そこで「並行処理」という言葉を初めて耳にしました。その言葉を初めて聞いたとき、「プログラムを同時に動かすことができるのか!」とワクワクしましたが、並行処理について調べてみると、
- 実は高速に切り替えて実行しているだけで本当に同時に実行していない
- 並列処理と並行処理があり、並列処理は本当に同時に実行している
というような内容が書かれており、当時は全く理解できずぼんやりとしたまま考えるのをやめてしまいました。
時は過ぎ、私はOSの自作やコンピューターサイエンスの勉強にハマりました。
そこで、プロセスの並行処理を調べたり自分で実装したりするうちに並行処理と並列処理への解像度が少し上がりました。
ネットで並列処理と並行処理の違いを調べてみても、この問題を考える上で重要なコンテキストやコンテキストスイッチの概念に触れている記事が少なかったので、今回はコンテキストの観点から両者の違いを考えていこうと思います。
並行処理と並列処理の違いの結論
結論から述べると、プロセスAとプロセスBの実行に際して、
- 並行処理は、特にシングルコアの場合、1つのコアがAとBのコンテキストを高速に入れ替えながらプロセスを実行する方式
- 並列処理は、複数コアを使って、AとBのプロセスを真に同時に実行する方式
となります。
この違いを理解するためには、コンテキストの概念の理解は不可欠です。
次節からコンテキストに焦点を当てて並行処理と並列処理の違いを見ていきます。
プロセスのコンテキストとは?
コンテキストの定義
コンテキストとは、プロセスの現在の実行状態を表す情報の集合を指します。
これは、プロセスが中断された後、その状態から継続して実行できるようにするための「状態のスナップショット」であると言えます。
実際には、プロセスの実行状態を保存するためのデータは様々ありますが、重要でわかりやすいデータとしては、以下のものがあります。
- プログラムカウンタ : 次に実行する命令が格納されているアドレス
- スタックポインタ : 変数や一時的な計算結果など、プログラムの実行に必要なデータが格納されているアドレス
- フラグレジスタ:条件分岐や算術命令の結果に基づくフラグの値
これらのデータの多くがCPUのレジスタに格納されています。
なので、コンテキストとはレジスタの内容 と考えることができます。
では、このレジスタについて詳しく見ていきます。
レジスタとは?
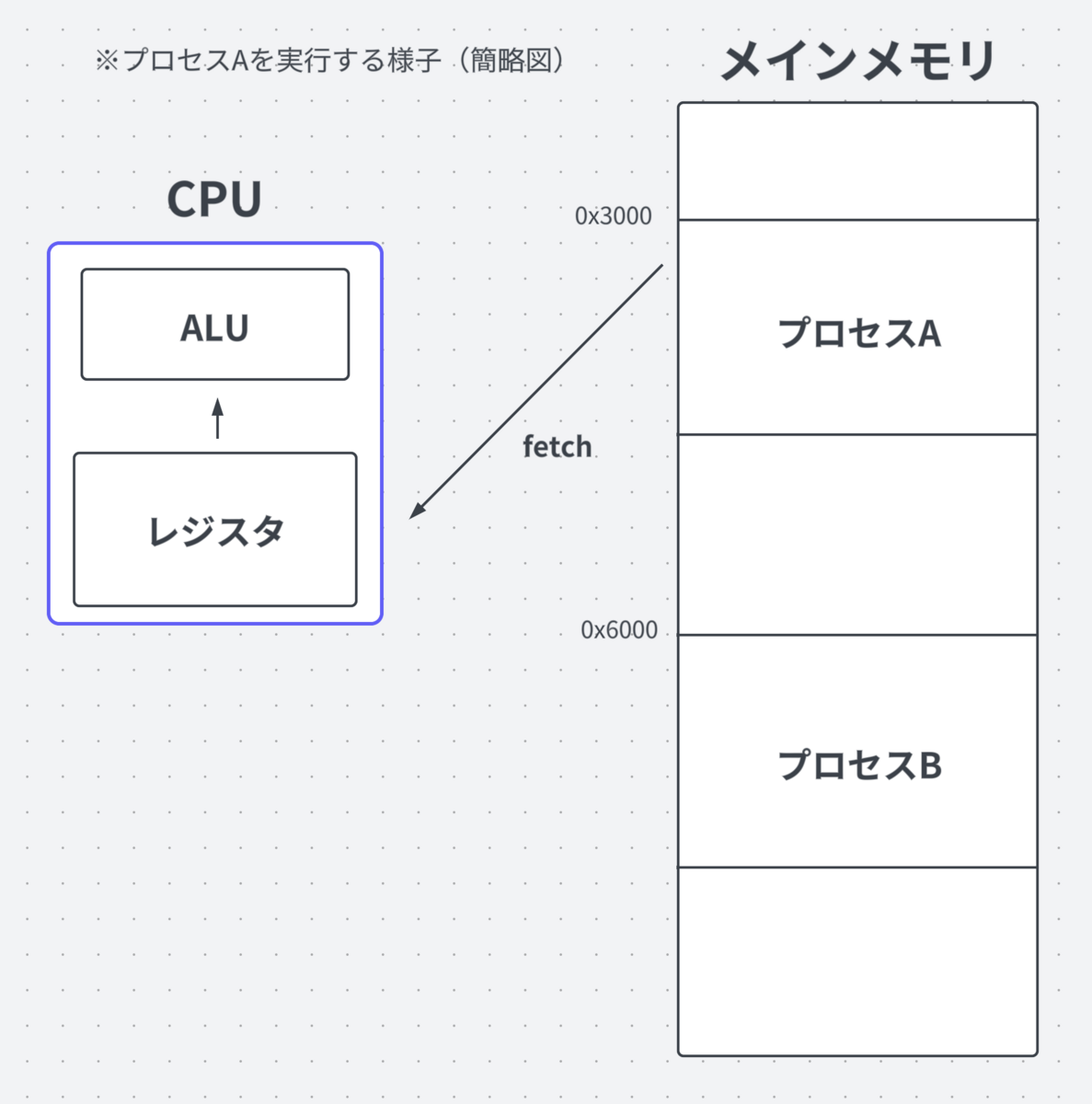
レジスタはCPUの内部に存在する、高速にアクセス可能である小さな記憶領域です。
CPUはメインメモリに直接アクセスするよりもレジスタへのアクセスの方が高速であるため、頻繁に使用されるデータや、実行中の命令の情報は一時的にレジスタに格納されます。
CPUの動作は、基本的に「命令のフェッチ」と「命令の実行」の繰り返しで、フェッチする際はメモリからデータや命令を取得し、レジスタに格納され、レジスタの値から処理が行われます。
このレジスタには先ほど述べた、プログラムカウンタやデータなどが格納されているわけですが、
もしプロセスAの実行中に、プロセスBのデータのアドレスやプログラムカウンタの情報でレジスタの内容を上書きした場合、どうなるでしょうか?
プロセスAの実行中にも関わらずいきなりプロセスBの実行に切り替わってしまいます。
これが、並行処理で行われていることの核心となる部分です。
次の節で詳しく見ていきます。
並行処理とは?
並行処理の定義
並行処理の定義は、「1つのCPUコアに対して複数のコンテキストを高速に入れ替えながらプロセスを実行する方式」と冒頭で述べました。
改めて、コンテキストにフォーカスして考えてみます。それぞれのプロセスはそれぞれのコンテキストを持っています。(メモリに格納されている場所やデータがそれぞれ違うので当たり前ですね)
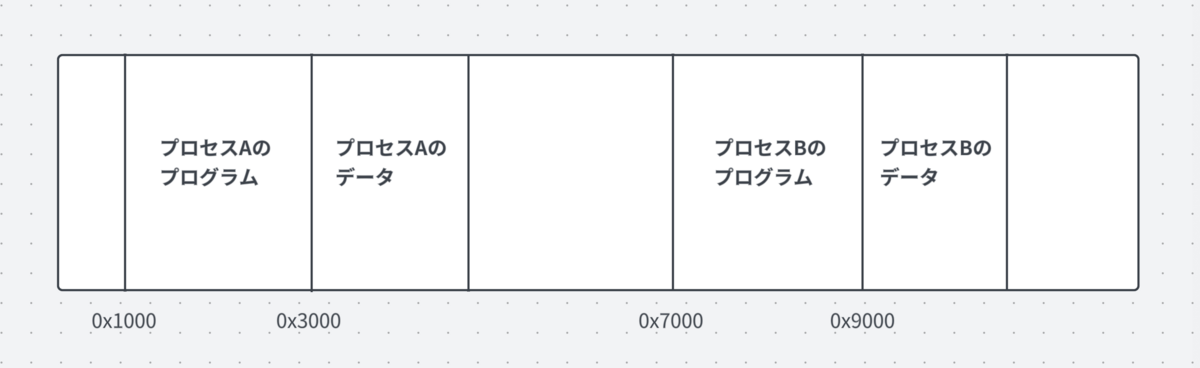
上の簡単な図をもとに考えてみます。
プロセスAのコンテキスト
- プログラムカウンタ: 0x1000
- スタックポインタ: 0x3000
プロセスBのコンテキスト
- プログラムカウンタ: 0x7000
- スタックポインタ: 0x9000
プロセスAが実行され始めた時、レジスタにはプログラムカウンタの0x1000、スタックポインタの0x3000を始めとした様々な値が保存されています。
ここで、プロセスAの実行中に現在のレジスタの値をどこかに退避させ、プロセスBのコンテキストをレジスタに格納すると、プロセスAの処理が中断され、プロセスBに処理が切り替わります。
これを連続して高速に行うとどうなるでしょうか?
CPUから見ると、複数のプロセスを高速に1つずつ処理しているだけなのですが、
人間から見ると、プロセスAとプロセスBが同時に動いているように見えると思います。
これが並行処理なのです。
コンテキストスイッチ
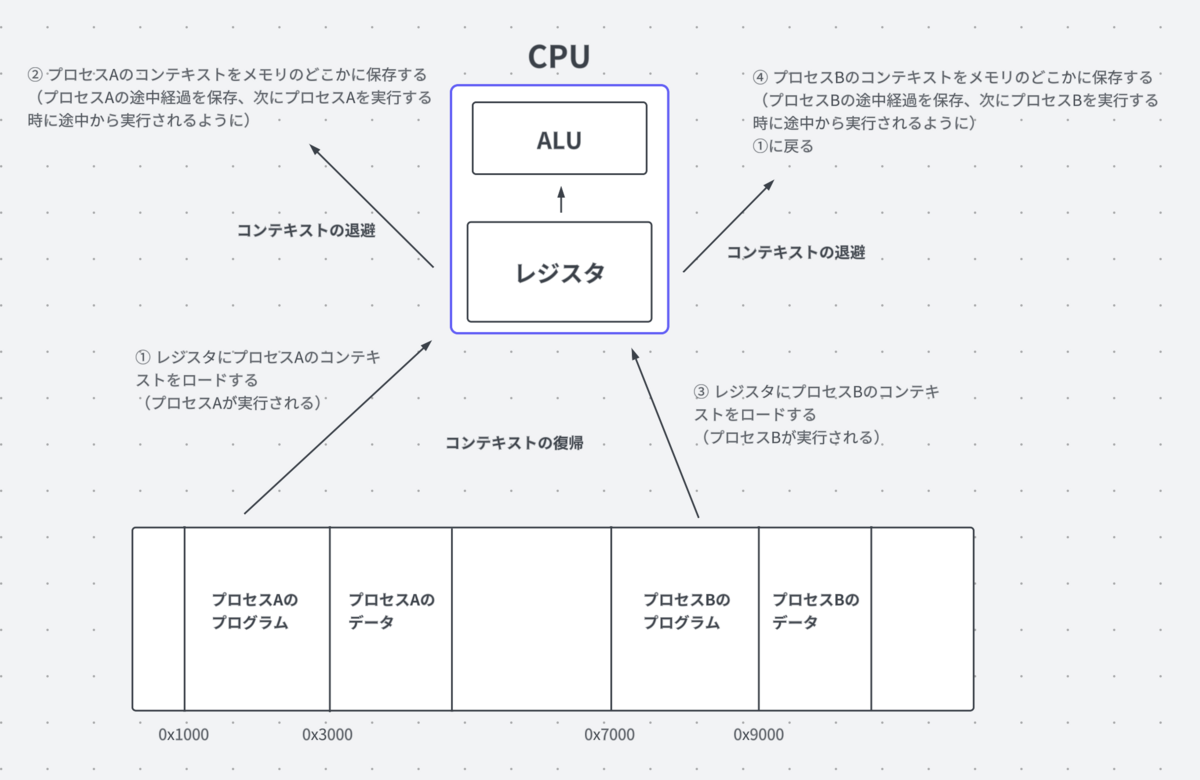
並行処理について調べていると「コンテキストスイッチ」というワードを目にすることがあると思います。当時の私にとってはこれが難しく理解できませんでした。
ですが、コンテキストスイッチの説明は既に上の節で述べられています。
プロセスAの実行中に現在のレジスタの値をどこかに退避させ、プロセスBのコンテキストをレジスタに格納すると、プロセスAの処理が中断され、プロセスBに処理が切り替わります。
この部分です。レジスタの値をプロセスAのコンテキストからプロセスBのコンテキストに切り替えるという処理がコンテキストスイッチとなります。
もう少し砕いた言い方をすると、コンテキストスイッチ = レジスタの値の入れ替え
ということがいえます。
また、高速にコンテキストスイッチを行うことが並行処理といえます。
並列処理とは?
並列処理の定義
並列処理の定義は、「並列処理は複数コアを使って、AとBのコンテキストをそれぞれ異なるコアに格納し、複数のプロセスを真に同時に実行する方式」と冒頭で述べました。
並行処理は1つのCPUコアが複数のプロセスを切り替えながら実行するものなので、実際には同時実行していませんが、並列処理は真に同時に実行しています。
なぜ並列処理は真に同時に実行することができるのでしょうか?
コンテキストとマルチコア
並列処理の真髄は、CPUが複数のコンテキストを同時に扱える能力にあります。
コンテキストの複数保持を実現してくれるのがマルチコアの存在です。
CPUコアはコアごとにそれぞれレジスタを持っており、複数のコンテキストを同時に保持、実行することができます。
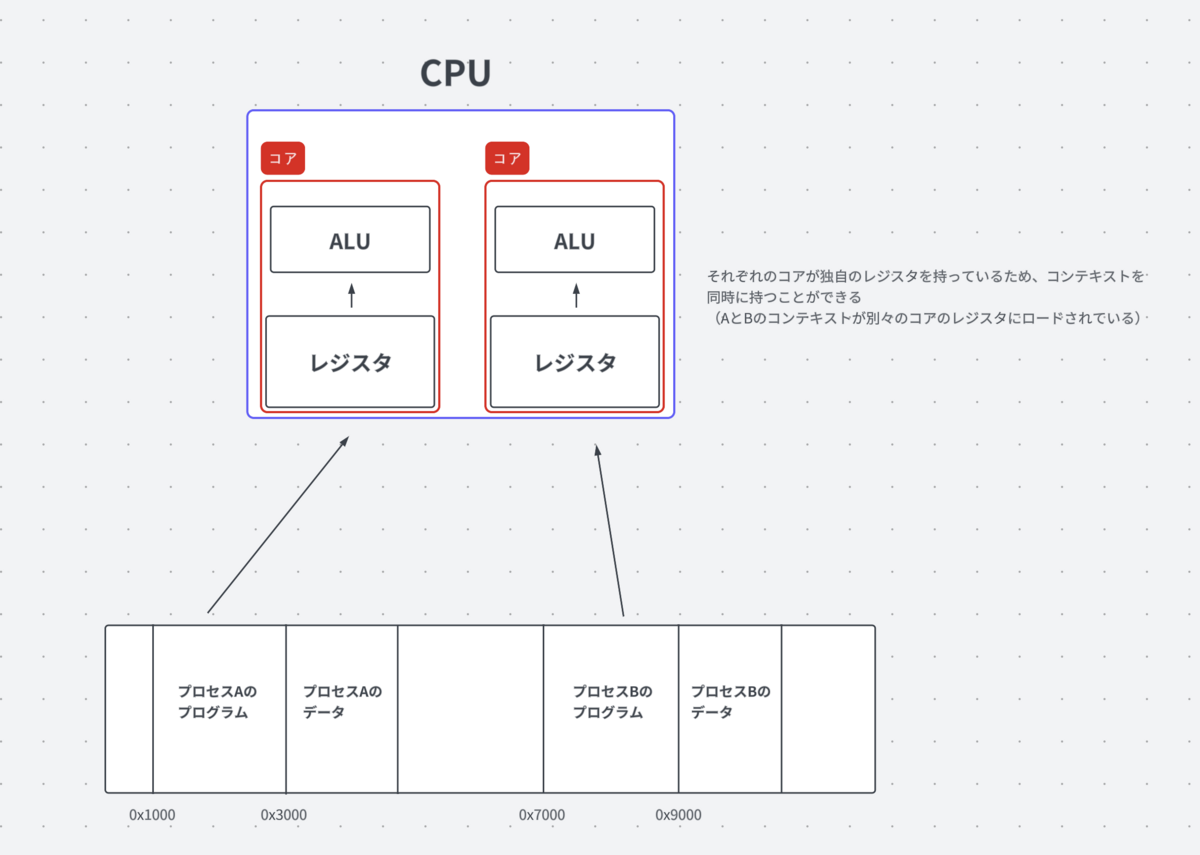
並行処理はコア1つに対してAとBを同時に実行させようとしていたので、高速にAとBをコンテキストスイッチする必要があったのに対して、並列処理は複数のコアを用いるのでコンテキストスイッチをすることなくそれぞれのコアにコンテキストを保持させて真に同時に実行することができます。
まとめ
並行処理は1つのコアに高速にコンテキストを切り替えて実行していく方式で、
並列処理は複数コアが、同時に実行したいプロセスのコンテキストをそれぞれ保持して同時に実行をしていく方式でした。コンテキストからのアプローチで見ると思っていたより理解しやすいのではないでしょうか。
実際には、どちらの処理方式も単独で使用されることは少なく、一般的にはこれらを組み合わせて利用されます。今回は、それぞれの方式の懸念点やパフォーマンス上のトレードオフ、最適な使い所には触れていませんが、これらのテーマは非常に奥が深いので、機会があればまた書きたいなと思います。
なお、今回の説明はわかりやすさを重視して簡略化している点もあるため、その点をご了承ください。