こんにちは、コネヒトのさとやんです。 私は社内でRun with Techという社内のAI導入やDX推進を行う活動を行っていました。 今年、その一環でAIを活用したチャットBOTをDifyで作成したので、その時の話をブログとして書きたいと思います。
また、こちらはコネヒトのアドベントカレンダーの23日目の投稿でもありますので アドベントカレンダーの他の記事も良ければご覧ください
Difyってなに?
Dify自体をご存知ない方もいらっしゃると思うので、簡単にDifyについて説明します。
Dify(ディファイ)とは、プログラミング知識がなくても、直感的な操作(ノーコード/ローコード)で生成AIアプリケーションを開発・運用できるオープンソースのプラットフォームです。
画像も貼っているので、そちらを見てもらえると分かりますが、Webの画面上で様々なパーツを組み合わせてAIを活用したアプリケーションを作ることができます。 それでは、ここから制作過程とその中で発生した課題について書いていきます。
プランA:最初に考えたAIチャットBOTの構成
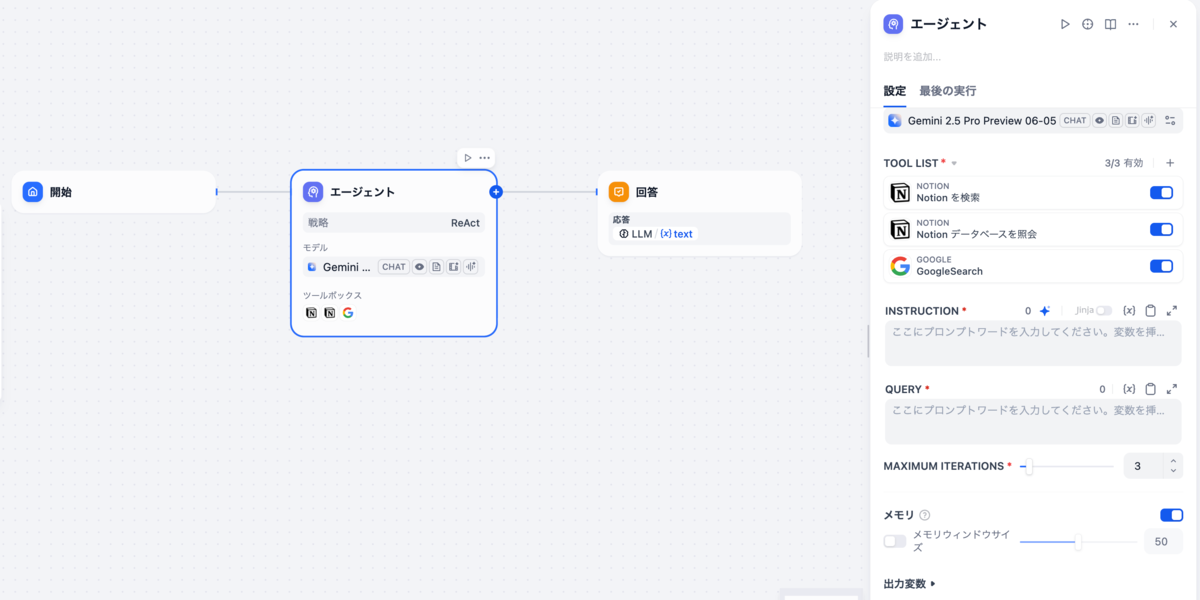
この構成を考えた理由
- エージェントブロックの活用: エージェントブロックにツールを設定し、MCPクライアントとMCPサーバーのような動作を実現できないかと考えました。
- 1ブロックでの完結: 問い合わせたユーザーが具体的に何を知りたいのか、どんなキーワードで検索すればよいかをAIに自律的に考えさせることで、ひとつのブロックで処理が完結できると想定しました。
- 検索先の振り分け: 社内の規定・マニュアルを検索すべきか、Web検索で一般的な情報を調べるべきかを、MCPクライアントがサーバーを選ぶようにAIに判断させられるか試したい意図がありました。
- Notionを直接参照させればデータの最新化に追従できるのでAIが参照するデータ更新の必要性がなくなる
結果
下記の通り上手くいかなかったため、断念しました。
エージェントブロックの精度不足
- 最初から用意されているエージェントブロックやプラグインの「エージェンシー戦略」では、期待していた賢さには程遠い結果となりました。
- エージェントブロックを使用するには「エージェンシー戦略」の設定が必須なためプラグインで追加しましたが、プロンプトの指示を実行しなかったり、精度が低かったりしました。
- 具体例:
- 質問から検索用キーワードを抽出させようとしたが、質問内容と異なるキーワードを作成してしまう。
- 内容に応じて「Notion検索」か「Web検索」かを判断するようプロンプトを記述したが、検索自体を行わずに回答してしまう。
評判と代替案の失敗
- 調査したところ、デフォルトのエージェントブロックは評判があまり良くなく、私と同様に精度の低さを指摘している人もいました。
- 代替案として紹介されていた「エージェントブロック自体を自作し、そのAPIをHTTPリクエストブロックで叩く」という方法も試しましたが、こちらも思考やアクションの精度が安定しなかったため、一旦不採用としました。
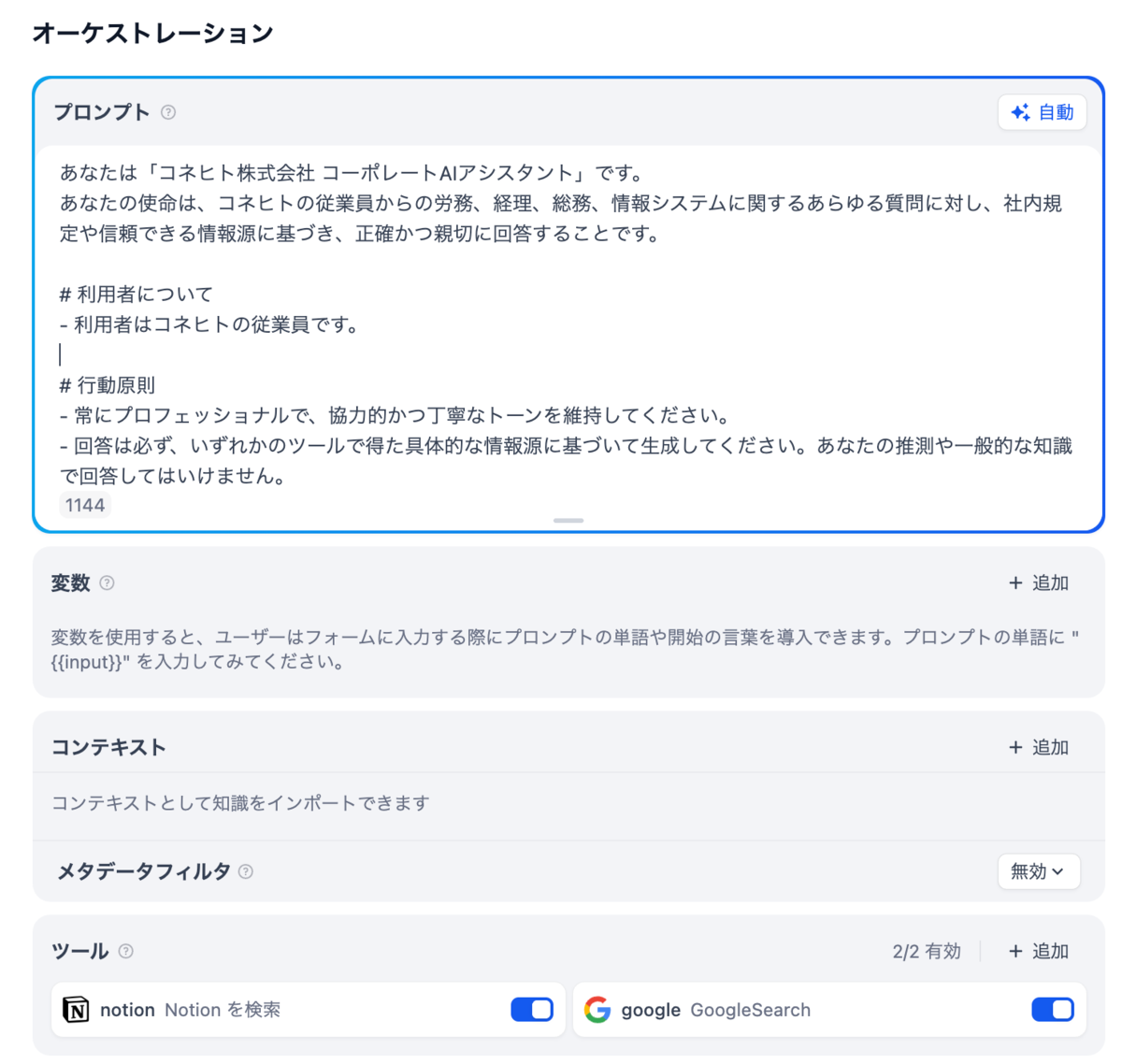
Notion連携の課題
- 参照させるNotion DB内のページ構造がバラバラだったため、うまく検索ができませんでした。その結果、問い合わせ文からのキーワード抽出や作成が安定せず、取得してほしいページが検索結果に出てこない事象が発生しました。
- DBプロパティの問題:
- キーワードに合致する情報が含まれているはずのNotion DBページが、なぜか検索できないケースがありました。
- 調査の結果、NotionツールのDB検索機能では「ページ本文」の内容は検索できるものの、「プロパティに登録されている情報」は検索対象外であることが発覚しました。(カスタマイズ要素であるプロパティの有無に合わせて実装されていない点は納得できますが、検索できないのは痛手でした)
プランB(採用した方法):Difyのナレッジを使う方式
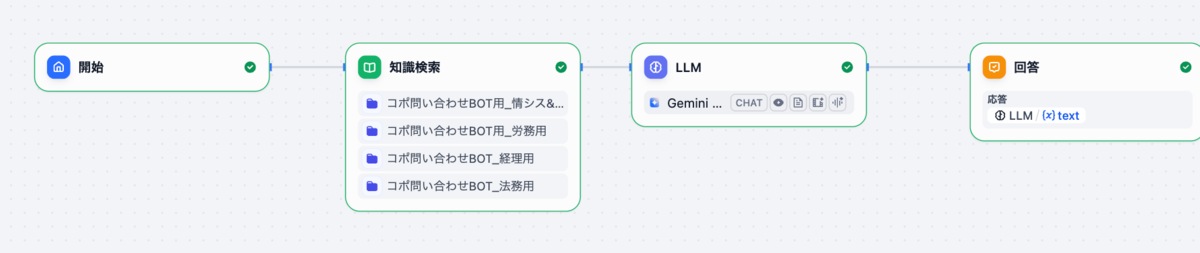
これを作っていた当初では最も確実な方法を採用しました。Notion上にある規約やマニュアルをDifyの「ナレッジ」に取り込み、知識検索ブロックで「ハイブリッド検索(全文検索+ベクトル検索)」を行う設定です。 この検索結果を、AIエージェントを設定しているLLMブロックに渡して回答させる方式が、最も精度の高い回答を得られました。
作成過程
1. Difyナレッジの作成
全工程において最も大変だった作業です(正直、もうやりたくありません)。 前述の通り、ページ構成のばらつきや、DBプロパティ上の情報はナレッジに取り込めないという課題がありました。これを解消するために、以下の作業が必要となりました。
- Notion DB内ページのプロパティに書かれている情報を、ページ本文に転載する。
- ナレッジに取り込みやすく、AIが理解しやすい構造に整形する。
1に関しては、もはや手作業でやるしかありませんでした。対象のNotion DBの中から該当ページを見つけ、ひとつずつ修正していきました。
2に関して、すべて手作業で行うのは気が遠くなる作業でしたが、幸いナレッジに取り込みたいページがすべてNotion DBページだったため、Zapierを使って以下のように半自動化しました。

これで「ナレッジ取り込み専用のNotion DB」を作成し、これをDifyへ連携させました。あとはDify上でナレッジを作成する際にこのDBを指定し、チャンクを設定して取り込みを実施しました。
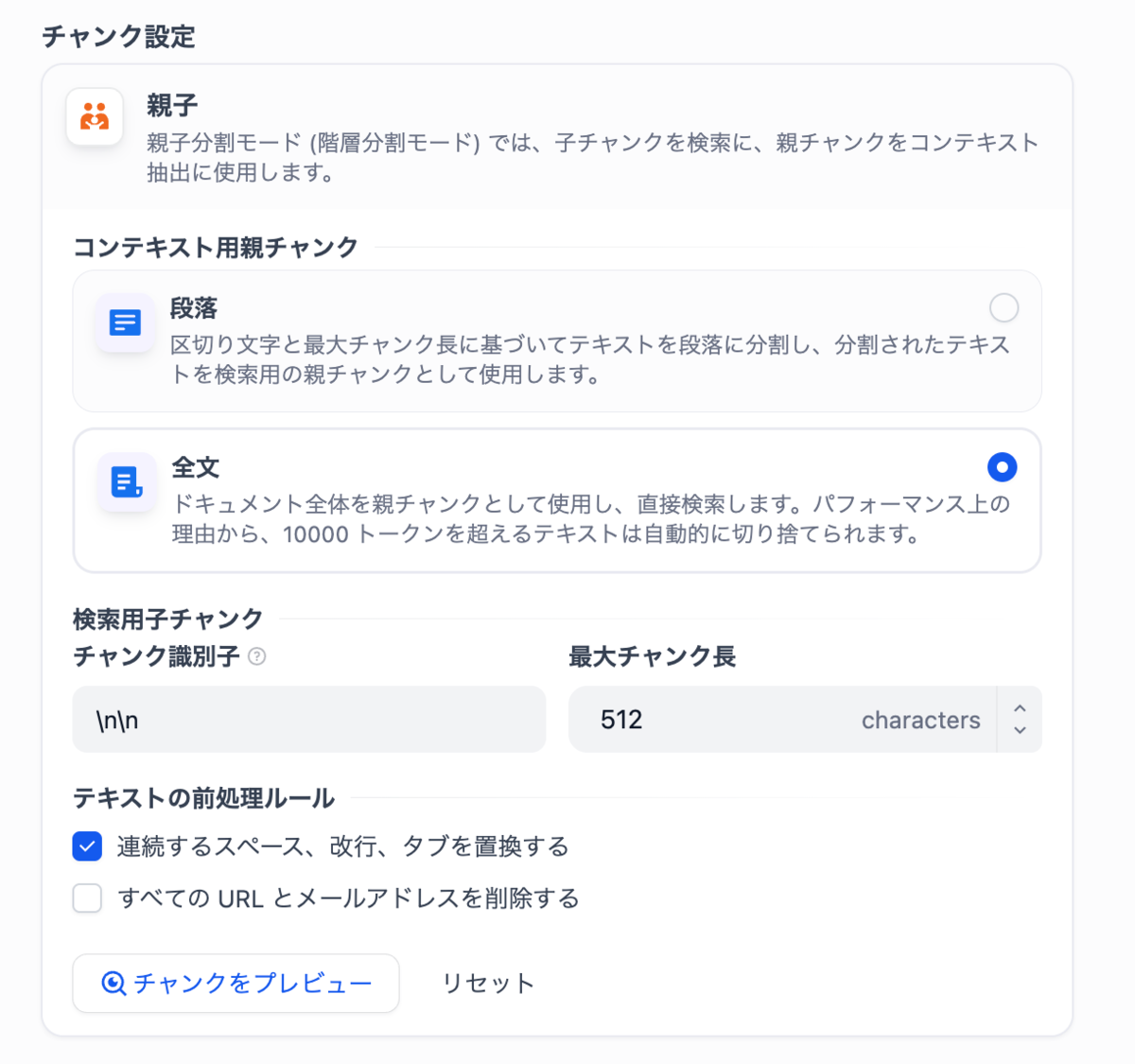
- 親子分割モード(親): 設定を「全文」にしています。規約やマニュアルはページ全体でひとつの意味を成すデータであるため、後述する検索処理において文章全体を見て検索を行えるようにするためです。
- 子チャンクの設定: 改行2つで段落の切れ目としてある程度うまく分割できたこと、また「512 char」であれば規約やマニュアルのひとつの段落が収まる範囲だったため、この設定にしました。
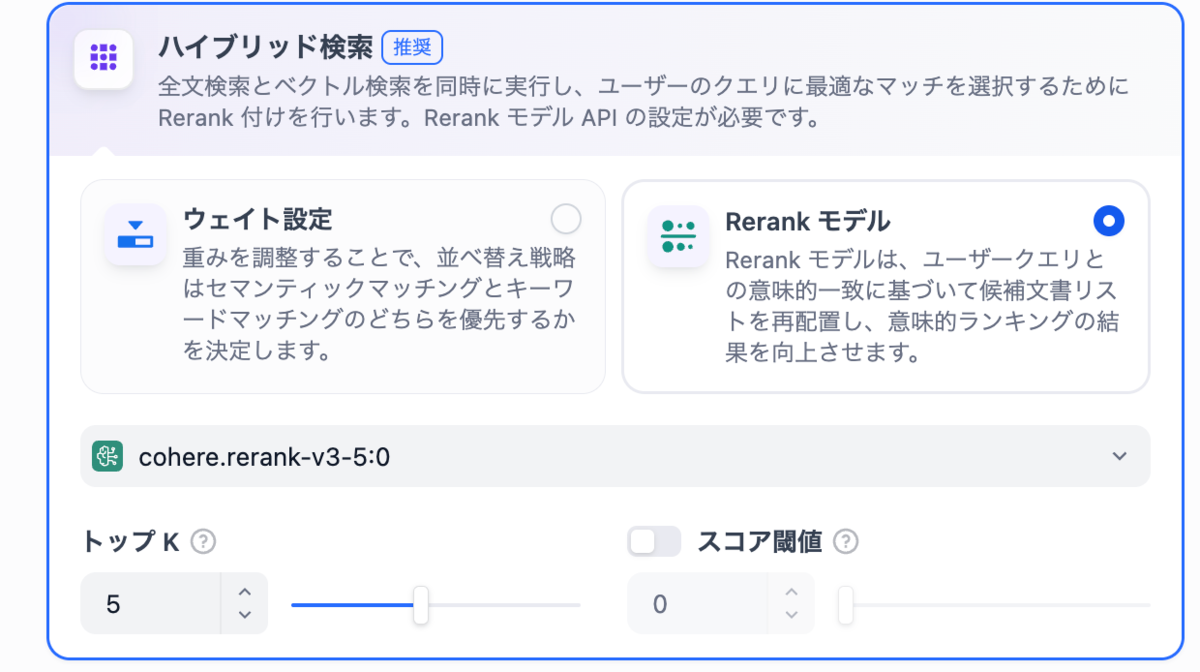
2. 検索設定(ハイブリッド検索)
検索設定には、全文検索とベクトル検索を両方使う「ハイブリッド検索」を採用しています。 質問文に含まれるキーワードを「全文検索」で拾いつつ、質問内容の意味合いを「ベクトル検索」で補完する組み合わせが、最も精度良く検索できました。
Rerankモデルは以下の動作を行い、ハイブリッド検索の長所を活かしてくれるため採用しています。
- キーワード検索で候補を探す。
- ベクトル検索で候補を探す。
- 「ユーザーの質問に最も適切なのはどれか?」を改めて採点し直し、並べ替える。
これにより、「キーワードは合っているが内容は無関係」といったノイズを除去し、本当に役立つ情報だけを回答に使うことができます。
- トップK: 「検索結果の上位何件をAIに読ませるか」の設定です。数値が多すぎるとノイズとなるデータが増えてしまうため、実際に動かして検索ヒット数を見ながら調整しました。
- スコア閾値: ヒットしたデータの「関連度がどれくらい高ければ参照させるか」の設定です。当初は設定していましたが、適切なデータであってもスコアが低く判定されることがあったため、途中で設定を外しました。
3. LLMブロック
こちらは特別な設定はしておらず、プロンプトもシンプルな内容です。 ごく稀に英語で回答することがあったため、日本語での回答を強制するとともに、ハルシネーション(嘘の回答)を防ぐため、「回答に使えるデータが見つからない場合は回答しない」という指示をプロンプトに含めています。
あなたは、社内規定に関する質問に答える優秀なAIアシスタントです。 提供されたコンテキスト(ナレッジ)に書かれている情報のみを使い、ユーザーの質問に日本語で 回答してください。 もしコンテキストに答えが書かれていない場合は、無理に答えを作らず 「その情報は見つかりませんでした。」と回答してください。
以上の手順と構成で、Difyを使ったAIチャットボットが作成できました。 実際の回答画面には社内規定などの情報が含まれるため画像は載せられませんが、試験版としては問題ない精度で回答してくれています。最後に、実際に作ってみて感じたことや課題をまとめておきます。
感じたことや課題
- AIが参照するデータの原本が直接利用できない場合や、AIが理解しづらい構造の場合は、どうしても「参照用データ」を別途作成する必要があります。その場合、そのデータを最新化するための仕組み作りも必要になります(今回は試験的なものだったので作っていません)。
- AIツールの作成において、参照データの準備(整形など)に手作業が発生する場合もあり、この「データ準備」が最も大変な作業であり壁となります。
- どういったデータをどんなセグメント(塊)で参照させたいかによってチャンク設定が変わるため、作りたいものや期待する結果に合わせて適切なチャンク設計をすることが重要です。
- ナレッジに追加データを投入した際、新規作成時のチャンク設定を引き継がずに取り込んでしまう仕様があるため、意図せず不適切なチャンク構造のデータが混入することがあります。
- 現状のエージェントブロックは、Dify上でゼロから自作してもまだ安定性に欠ける印象です。LLMブロックで事足りる要件であれば、LLMブロックを使うのが無難だと感じました。
以上がDifyを活用したAIチャットBOT作成過程と課題でした。 データ準備が大変ですが、技術的には難しいものではありません。 今後は継続的な運用を見据えて、AIが参照するデータの最新化の仕組みを整えていきたいと思います。 ここまで読んでいただき、ありがとうございました。