こんにちは!
フロントエンドエンジニアのもりやです。
先日エンジニアチーム内で AWS SES のバウンスレートについて話題になったのですが、その時に「バウンスって何?」という声がちらほら聞こえてきました。
Webサービスではユーザー登録や問い合わせなどメールが必要になる場面が多いです。
バウンスなどはメールを安定して送信するために必要な知識なのですが、なかなか担当する人以外は知られていないのかな、と思いました。
そこで今回は、バウンスメールなどのメール運用で知っておきたいエンジニア向けの知識を紹介しようと思います。
(執筆時に調べた資料などは最後に記載しておりますので、より詳しく知りたい方はそちらもあわせて読んでみてください)
また、コネヒトでも使用している AWS SES の場合、バウンスをどう扱っていく必要があるかについても紹介します。
(※なお SMTP などのメールの仕組みや仕様などは本記事では解説しません)
Webサービスとメール
LINE や Slack など様々なコミュニケーションサービスが普及している今でも、メールは欠かせないツールです。
理由としては、メールアドレスを知るだけで送信でき、安価に使えることだと思います。
そのため、アカウント登録やお知らせなど様々な場所で使われています。
(SMS も電話番号だけで送信できますが、送信単価がメールに比べると高いですね)
ところが、その便利さ故に困った事が出てきます。
ご存知スパムメールですね。
メールアドレスが知られてしまうだけで、スパムメールも送信されてしまいます。
日常的に大量のスパムメールが送信されてくれば、メールは使い物にならなくなってしまうでしょう。
しかしながら様々な対策が取られているおかげで、私達は日頃ちゃんとメールを使うことができています。
ところがこの「様々な対策」が時に我々サービス提供者にとってネックになってしまう場合があります。
ここからが本題です。
メールは送信元が評価されている
今回お伝えしたいことの本題はこれです。
メールは送信元が正しくメールを送信しているかを評価されています。
(ちなみに本ブログでは「評価」で記載を統一しますが「レピュテーション」とも呼ぶ場合も多いです)
評価しているのは特定の組織というわけではなく、メールサービスを提供しているISPなどが個別に評価しています。
なので、統一された評価基準が存在するわけではありませんが、評価を下げてしまうよく知られた要因はあります。
それを説明していきます。
評価が下がる主な要因
送信元の評価が下がる主な要因を紹介します。
SPF/DKIM が設定されていない
SPF/DKIM とは、メールの送信ドメインを認証するための仕組みです。
なりすましメールを防ぐことができます。
自分で「私は〇〇の者です」というだけ言う人と、身分証明書を合わせて提示してくれる人のどちらが信用できるか、といったイメージですかね。
SPFはIPアドレスを使って、認証をしています。
メールの送信元のIPアドレスと、DNS に設定されている SPF レコードが一致するかを検証します。
DKIM は電子署名を使って認証をしています。
秘密鍵で署名した情報をメッセージと共に送信し、DNS に設定されている公開鍵の情報を元に正当性を判断します。
どちらも DNS が絡んできます。
バウンスメールが多い
冒頭にも出てきたバウンスメールです。
バウンスメールとは、何らかの原因でメールが相手まで到達できなかったメールのことです。
バウンスメールには以下の2種類があります。
- 一時的なエラーによるソフトバウンス(例:メールボックスの容量がいっぱいだったなど)
- 恒久的なエラーによるハードバウンス(例:メールアドレスが存在しないなど)
本ブログに出てくるバウンスとは、後者のハードバウンスを指します。
なぜハードバウンスが多いと評価が下がるのかと言うと、適当なリストやランダムに生成したメールアドレスに送信している疑いがあるためです。
要はスパムを送る業者などに出る特徴ということなのでしょうね。
バウンスを検知した場合は、再送しない対策が必要になります。
AWS SES では、バウンス率を2%未満に保つことを推奨しています。
また、5%を超えると対応を求められ、最悪送信できなくなる場合があるようです。
最良の結果を得るには、バウンス率を 2% 未満に維持する必要があります。
バウンス率が 5% 以上になると、アカウントはレビュー対象になります。バウンス率が 10% 以上の場合は、高いバウンス率の原因となった問題が解決するまで、以後の E メール送信を一時停止することがあります。
Amazon SES Sending review process FAQs - Amazon Simple Email Service
苦情が多い
苦情とは、受信ユーザーが「このメールはスパムだ」と報告するやつです。
例えば Gmail には「迷惑メール」というボタンが設置されていますね。
AWS SES では、苦情率を0.1%未満に保つことを推奨しています。
また、0.1%を超えると対応を求められ、最悪送信できなくなる場合があるようです。
最良の結果を得るには、苦情率を 0.1% 未満に維持する必要があります。
苦情率が 0.1% 以上になると、アカウントはレビュー対象になります。苦情率が 0.5% 以上の場合は、高い苦情率の原因となった問題が解決するまで、以後の E メール送信を一時停止することがあります。
Amazon SES Sending review process FAQs - Amazon Simple Email Service
受信ユーザーが明示的に送るものなので、スパム判定の重要な指標になっていそうですね。
メールに「unsubscribe」リンクが設置されて、ワンクリックで購読解除できるようになっているサービスも多いですね。(特に海外のサービスに多い印象です)
これはユーザビリティ以外に、購読解除を素早く行わせることで「迷惑メール」ボタンを押されないようにする、という理由もあるのではないかと思います。
AWS SES を使う場合の注意点
AWS SES は上記のようなバウンスや苦情を自動で管理・対応してくれません。
これらを監視・対応するのはAWS利用者の責任となっています。
そのため AWS SES を使う際には、最低でもバウンスや苦情を検知しておく必要があります。
(2020/09/20 追記)
アカウントレベルのサプレッションリストを使用すると対応もできるようです。
詳しくは「アカウントレベルのサプレッションリストを使用する」の章をご覧ください。
バウンスや苦情の検知方法
AWS SES でバウンスが起きた場合は、SNS Topic に送信することができるようになっています。
とりあえずバウンスと苦情に SNS Topic を登録し、メールでサブスクリプションを作成すればバウンスや苦情が発生した際に気づくことができます。
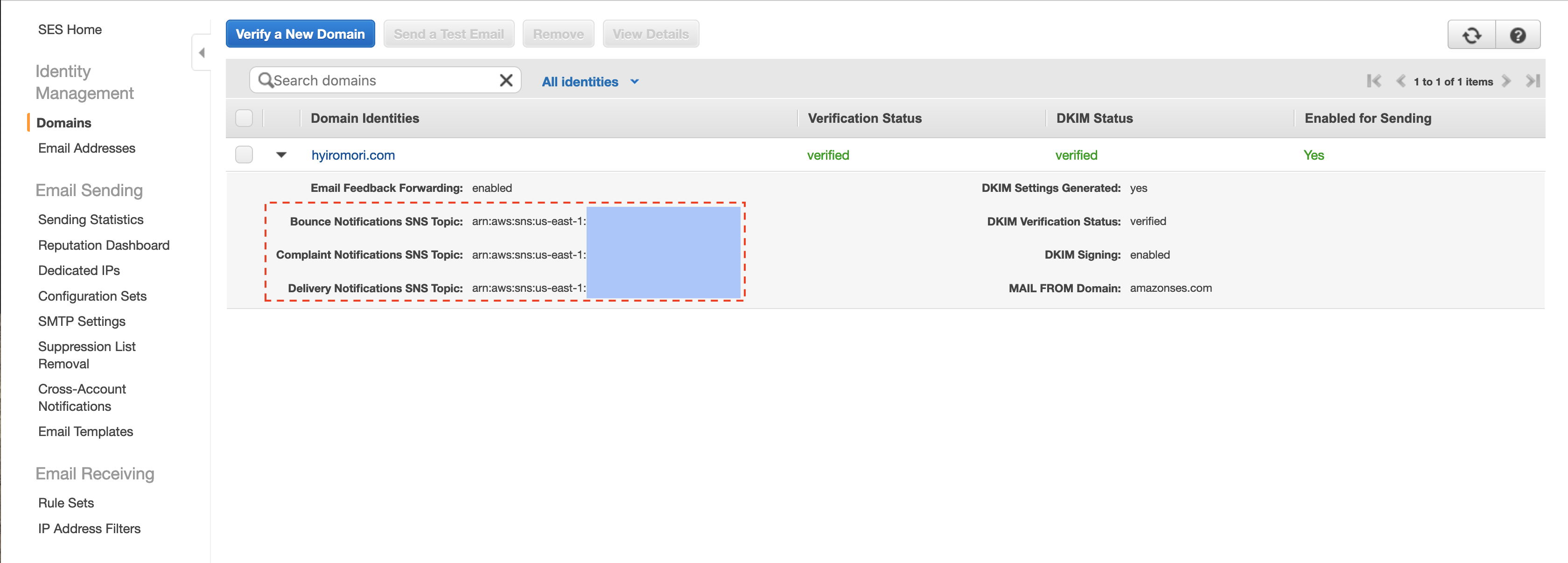
メールの場合はこのように配信されます。

配信件数が多くない場合は、メールで通知して対応するだけでも十分かもしれません。
ただし内容が JSON で送られてくるので読みにくくはありますが・・・。
たくさんのメールを配信するようになると、利用者のメールアドレスの打ち間違いなど、一定数のバウンスも発生してくるようになると思います。
そういった場合はシステム的に対応できるようにしておくほうが良さそうです。
なお CloudTrail では SendEmail などの API コールは記録されないようです。残念。

Logging Amazon SES API calls with AWS CloudTrail - Amazon Simple Email Service
また AWS SES 以外のメールサービスにはバウンスに対応してくれるものもあるので、そちらも検討しても良いかも知れません。
例えば SendGrid にはバウンスに対応できる機能があるようです。
(私は使ったことがないので、具体的にどのようなものかは分かりません)
SendGridでは、ハードバウンスが発生した場合は、そのアドレスをサプレッションリストに登録します。サプレッションリストに登録されている宛先への送信リクエストがあった場合、SendGridはそのメッセージを破棄(Drop)し、受信者のサーバーへの送信処理を行いません。無効なアドレスに対し送信し続けることはレピュテーションを下げる原因となってしまうからです。
バウンスメールとその対策 | SendGridブログ
Tips: バウンスや苦情をテストする場合
バウンスなどのテストをする場合は、AWS から提示されているテスト用のアドレスを使いましょう。
これらのアドレスはバウンス率や苦情率にカウントされません。
Testing email sending in Amazon SES - Amazon Simple Email Service
AWS SES でバウンスなどをシステム的に対応する場合
基本的にやり方はAWS利用者に委ねられています。
バウンスや苦情は SNS Topic に対して通知することしか設定できないようなので、SNS から HTTP や Lambda のスブスクリプションを作ってその先で何らかの対応をする、という感じになるでしょう。
私自身、ここまで対応したことはなかったので、バウンスメールを捕捉してメール送信を制御するサンプル実装を作ってみました。
GitHub: hyiromori/example-ses-bounce
構成はこんな感じです。
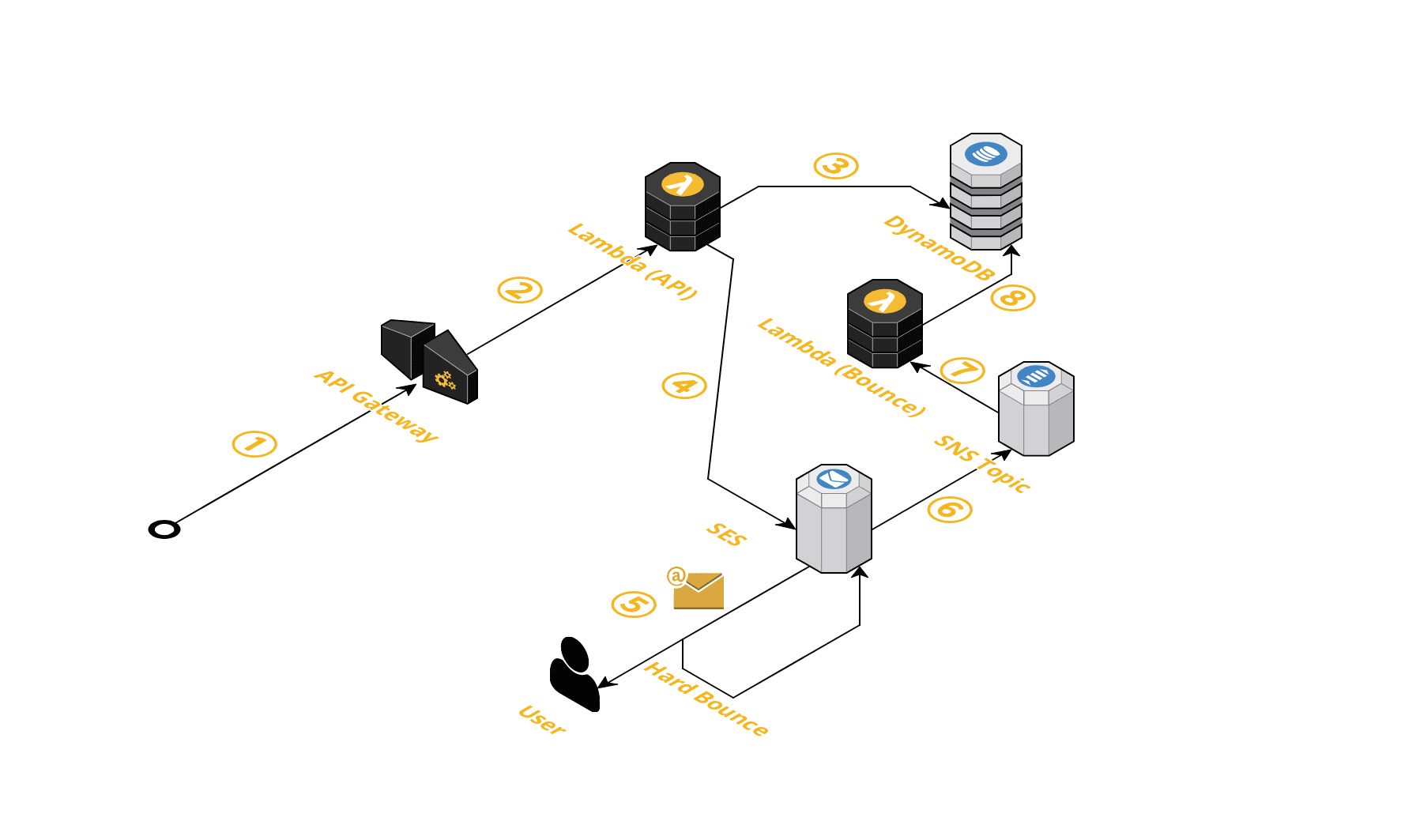
バウンスメールを検知した場合に DynamoDB に保存して、送信前にバウンスの履歴がないかをチェックするような仕組みになっています。
詳しく見たい方は README をご覧ください。
アカウントレベルのサプレッションリストを使用する(2020/09/20 追記)
ブコメで「アカウントレベルのサプレッションリストを使えばもっとシンプルになる」というコメントがありました。
情報ありがとうございます。
この機能は2019年11月にリリースされたようですね。
Amazon SES がアカウントレベルの抑制リストを発表
試してみましたが、上記のサンプル実装ような仕組みを構築しなくてもこれを使えば良さそうでした。
以下、調査や試した結果などを記載します。
アカウントレベルのサプレッションリストの有効化
2019年以前から使用している場合は、明示的に有効にしないといけないようです。
2019 年 11 月 25 日以降に Amazon SES の使用を開始した場合、アカウントはバウンスと苦情の両方に対してアカウントレベルのサプレッションリストをデフォルトで使用します。この日付より前に Amazon SES の使用を開始した場合は、Amazon SES API の PutAccountSuppressionAttributes オペレーションを使用してこの機能を有効にする必要があります。
アカウントレベルのサプレッションリストの使用 - Amazon Simple Email Service
バウンスと苦情の両方を有効にする場合は、以下のコマンドで有効にできるようです。
$ aws sesv2 put-account-suppression-attributes \
--suppressed-reasons "BOUNCE" "COMPLAINT"
アカウントレベルのサプレッションリストの動作検証
挙動を試したかったので、適当なアドレスにメールを送信して確かめました。
※注意:今回は検証のためにやりましたが、適当なメールアドレスに送信すると当然バウンスレートが上がってしまうので、可能な限りやらないでください。ちなみに、私が個人で使っているAWSアカウントでやっています。
上記の有効化以外は、特に設定をしなくてもサプレッションリストに自動的に追加されました。
$ aws sesv2 list-suppressed-destinations
{
"SuppressedDestinationSummaries": [
{
"EmailAddress": "b33a624b-e250-4976-80f7-4fb6eec55165@gmail.com",
"Reason": "BOUNCE",
"LastUpdateTime": "2020-09-20T08:02:05.934000+00:00"
}
]
}
この後同じメールアドレスに再送信してみましたが、実際に送信されませんでした。
またバウンスにもカウントされませんでした。
上記のサンプル実装のように自前で色々やらなくても、これだけで大体のケースをカバーできそうです!
なおテスト用の bounce@simulator.amazonses.com に送信してもサプレッションリストには追加はされないようです。
Gmail の苦情データについて
ドキュメントを読んでいると気になる記述がありました。
Gmail では、Amazon SES に苦情データが提供されません。受取人が Gmail ウェブクライアントの [迷惑メール] ボタンを使用して、受信したメールを迷惑メールとして報告した場合、アカウントレベルのサプレッションリストには追加されません。
アカウントレベルのサプレッションリストの使用 - Amazon Simple Email Service
Gmail の苦情(「迷惑メール」ボタン)に関しては自動で追加されないようです。
恐る恐る Gmail で「迷惑メール」ボタンをクリックしてみると・・・、苦情率も上がらず、設定している SNS での通知も来ませんでした。
どうしてなのか気になって調べてみると、苦情のデータはフィードバックループという仕組みで提供されているようです。
しかしながら Gmail はこのフィードバックループに対応していないようでした。
Gmailはいまや世界で最も有名なメールサービスとなりました。その中身はGoogle独自の技術でブラックボックス化されており、ホワイトリストやフィードバックループなど多くのISPで利用されている技術は利用されていません。
Gmail宛にメールを届けるための5つのポイント | SendGridブログ
正確には対応しているけれども、条件を満たした場合のみしか利用できないようです。
(※) Gmailもフィードバックループに対応していますが、利用可能なのは以下の条件を満たしているESPのみです。
・MAAWG(Messaging Anti-Abuse Working Group)のメンバーである
・Googleに「良い送信者」であると認められている
フィードバックループ【入門】 | SendGridブログ
Google は Postmaster Tools というツールを提供しているようです。
Gmail に関しては、こちらで迷惑メールを確認する必要があるようですね。
Postmaster Tools を使ってみる - Gmail ヘルプ
Gmail で「迷惑メール」ボタンを押されても、苦情率が上がるわけではないので AWS SES から送信できなくなることはなさそうです。
しかし多くのユーザーをもつ Gmail に迷惑メールと判定されるようになると、送信しても迷惑メールに振り分けられてしまうためこちらも注意する必要がありそうです。
おわりに
メールは歴史が長く、いろいろな場面で使われているため様々な対策が講じられています。
「うちのサービスはあんまりメールを送信していないから大丈夫」と思っていても、認証情報がスパム業者に漏れたりして大量のスパムメールを送られてしまい、サービスで必要なメールが送れなくなることもありえます。
(もちろん認証情報が漏れないようにすることが一番重要ですが)
バウンスや苦情が発生しないように、また発生しても素早く検知して対応し、安定してメールを使っていきたいですね。
PR
コネヒトではエンジニアを募集しています!
執筆時に参照した資料など
SendGrid さんのブログは、メールに関する様々な情報がまとまっていて、とても参考になります。



















