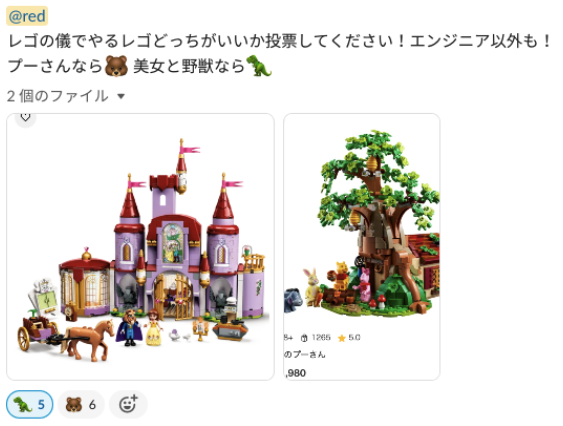
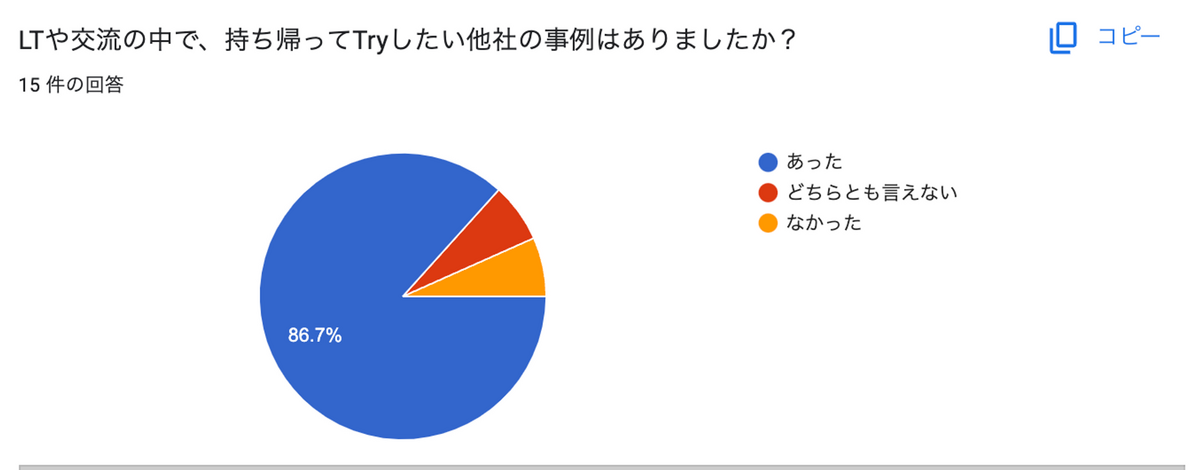
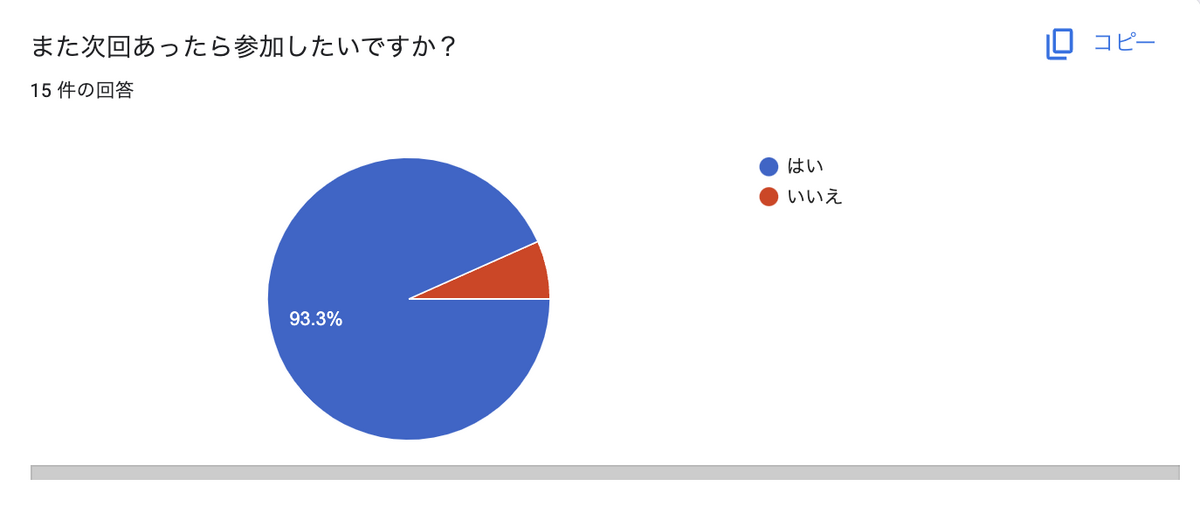
みなさんこんにちは。AI・検索チームのたかぱい(@takapy0210 )です。
最近猫を飼い始めました。名前は「きぬ」ちゃんです。名前からして可愛いのが伝わると思うのですが、とっても可愛いです。
さて、昨今大規模言語モデル(L arge L anguage M odel: LLM)の発展により業界では日々新しい話題が飛び交っています。例に漏れず弊社内でもLLMを用いた施策のPoCなどを進めていっている段階です。
今回は社内向けの施策として、Open AIのAPIを用いたSlack Botを開発した話をしようと思います。
いわゆる「ChatGPT × Slack Bot」の開発記事などは多く出回っていると思いますが、今回はLangChain と組み合わせることで、Web版のChat GPTのように過去の会話を記憶させながらSlack上でAIとコミュニケーションさせる 、という部分にフォーカスを当てながら書いていますので、興味のある方は立ち読みしていってください。
ちなみに、このような感じでslackの同一スレッド内であれば、過去の会話を考慮しながらコミュニケーションしていくことができます。[default.build] は使えないことが後に分かりました・・・😇 )
目次
LangChainとは?
LangChain はGPT-3のようなLLMを利用したサービス開発を支援してくれるライブラリです。
Python版の公式ドキュメントpython.langchain.com
提供モジュールの種類
上記ドキュメントを見るとわかるのですが、大別して以下6つのモジュールに整理できます。
Models
共通のインターフェースを通じて各 LLM API を使うためのモジュール
Prompts
Indexes
独自のテキストデータをLLMと組み合わせて使いたいときに使えるモジュール
Memory
LLMとのやり取りを保持するためなどに使用するモジュール
Chains
各モジュールを連結し実行することのできるモジュール
Agents
LangChainが提供しているさまざまなツールを使用して、より高度な回答を生成するためのモジュール。ユーザの入力に応じて、与えられたツールからどのツールをどういう順序で実行するかをLLM自身が決定していく。
今回使用したのは、Models, Prompts, Memory, Chainsです。
Slack Botを開発する際の事前準備
今回紹介するBotを作成するのに、必要な事前準備があります。ざっくり以下2点です。
Open AI APIの利用登録、API Key取得
Slack Bot周りのToken取得
Open AI APIの利用登録、API Keyの取得
OpenAI の Web サイト にアクセスし、右上の"Sign In"ボタンをクリック後、アカウント登録をします。
Slack Bot周りのトークン発行
ここが一番面倒臭い大変かもしれません。
以下のページに従って、Tokenの発行を行います。
slack.dev
今回は上記ドキュメントに書かれている以下2つのTokenが必要になります。
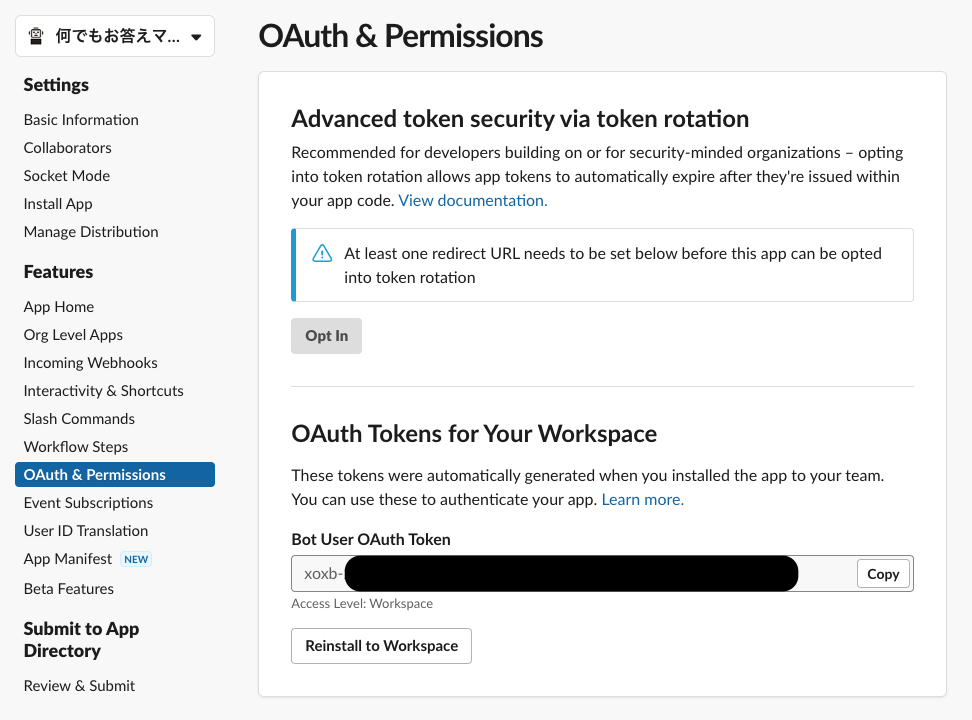
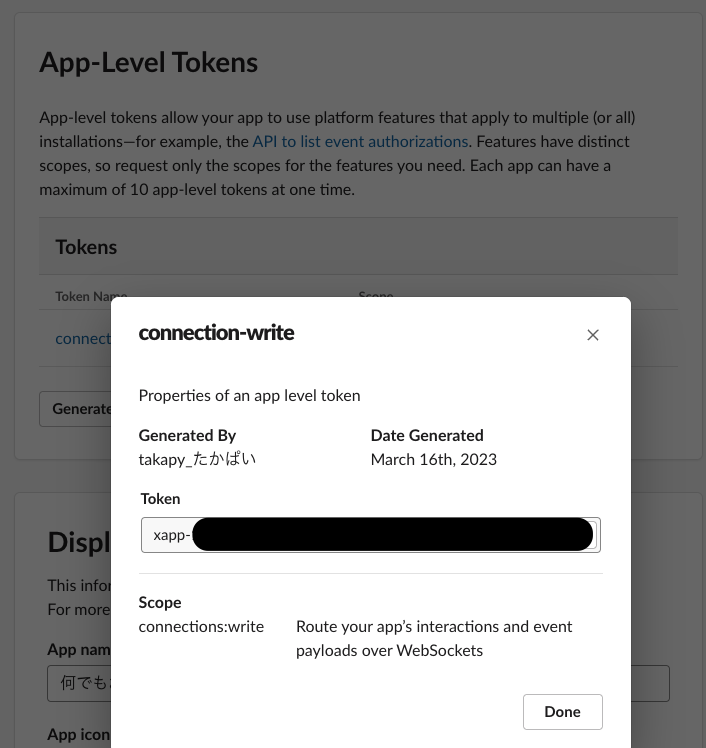
Bot tokens :ボットユーザーに関連づけられ、1 つのワークスペースでは最初に誰かがそのアプリをインストールした際に一度だけ発行されます。どのユーザーがインストールを実行しても、アプリが使用するボットトークンは同じになります。ほとんどのアプリで使用されるのは、ボットトークンです。App-level tokens :全ての組織(とその配下のワークスペースでの個々のユーザーによるインストール)を横断して、あなたのアプリを代理するものです。アプリレベルトークンは、アプリの WebSocket コネクションを確立するためによく使われます。
上記ドキュメントを参考に、もろもろの手順を踏んだあとであれば、slack appのページ に飛んで、該当のボットを選択した後、以下スクショの箇所にTokenが生成されているはずです。(このTokenも後ほど使います)
Bot tokens
App-level tokens
Slack Botの開発とサンプルコード
今回はslackのBoltフレームワーク を用いてBotの開発を行っています。
コードの全体像は以下のようなイメージです(本当はリポジトリを公開したかったのですが、弊社オリジンの処理が入る可能性もあるため、ここではあくまでサンプルとして、コメントやコードの一部を改変して共有します。が、基本的にこのままでも問題なく動作するはずです)
import concurrent.futures
import os
import openai
from dotenv import load_dotenv
from langchain import LLMChain, PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
load_dotenv()
SLACK_BOT_ID = "BotユーザーのIDを設定"
app = App(token=os.environ["SLACK_BOT_TOKEN" ])
openai.api_key = os.environ["OPENAI_API_KEY" ]
def send_chat_request (prompt: PromptTemplate, memory: ConversationBufferMemory, input_message: str ) -> str :
"""OpenAIの言語モデルにチャットメッセージを送信しレスポンスを生成する
"""
try :
llm = ChatOpenAI(model_name="gpt-3.5-turbo" )
chatgpt_chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=False ,
memory=memory,
)
return chatgpt_chain.predict(human_input=input_message)
except Exception as e:
return ""
def call_function_with_timeout (func, timeout_seconds, *args) -> dict :
"""ターゲット関数を別のスレッドで実行し、タイムアウトを適用する
"""
with concurrent.futures.ThreadPoolExecutor() as executor:
future = executor.submit(func, *args)
try :
response = future.result(timeout=timeout_seconds)
return {"result" : response}
except concurrent.futures.TimeoutError :
return {"error" : "Function execution timed out" }
def remove_slack_id_from_text (text: str , slack_id: str ) -> str :
"""textからslack_idを削除する
"""
return text.replace(f"<@{slack_id}>" , "" )
def create_prompt () -> PromptTemplate:
"""OpenAIの言語モデルに入力するプロンプトを作成する
"""
template = """Assistant is a large language model trained by OpenAI.
必要であればここにプロンプトを追加する
{history}
Human: {human_input}
Assistant:"""
prompt = PromptTemplate(input_variables=["history" , "human_input" ], template=template)
return prompt
def create_memory (user_id: str , channel: str , thread_ts: str ) -> ConversationBufferMemory:
"""会話のメモリーを作成する
"""
memory = ConversationBufferMemory(human_prefix="Human" , ai_prefix="Assistant" , memory_key="history" )
if thread_ts is not None :
thread_message = app.client.conversations_replies(channel=channel, ts=thread_ts)
for i in thread_message["messages" ]:
if i["user" ] == user_id and SLACK_BOT_ID in i["text" ]:
memory.chat_memory.add_user_message(remove_slack_id_from_text(i["text" ], SLACK_BOT_ID))
elif i["user" ] == SLACK_BOT_ID and user_id in i["text" ]:
memory.chat_memory.add_ai_message(remove_slack_id_from_text(i["text" ], user_id))
return memory
@ app.event ("message" )
def handle_message_events (body):
"""slackにメッセージが投稿されたときのイベントハンドラー
"""
return None
@ app.event ("app_mention" )
def chatgpt_reply (event, say):
"""slackでメンションされたときのイベントハンドラー
"""
input_message = event["text" ]
thread_ts = event.get("thread_ts" ) or None
channel = event["channel" ]
user_id = event["user" ]
prompt = create_prompt()
memory = create_memory(user_id, channel, thread_ts)
input_message = remove_slack_id_from_text(input_message, SLACK_BOT_ID)
timeout_seconds = 2 * 60
response = call_function_with_timeout(send_chat_request, timeout_seconds, prompt, memory, input_message)
if "error" in response or response["result" ] is None :
reply_text = f"<@{user_id}> \n ごめんなさい。現在サーバーの負荷が高いため処理できませんでした。時間をおいて再度質問してください。"
else :
reply_text = response["result" ]
reply_text = f"<@{user_id}> \n {reply_text}"
if thread_ts is not None :
parent_thread_ts = event["thread_ts" ]
say(text=reply_text, thread_ts=parent_thread_ts, channel=channel)
else :
response = app.client.conversations_replies(channel=channel, ts=event["ts" ])
thread_ts = response["messages" ][0 ]["ts" ]
say(text=reply_text, thread_ts=thread_ts, channel=channel)
if __name__ == "__main__" :
handler = SocketModeHandler(app, os.environ["SLACK_APP_TOKEN" ])
handler.start()
以降では、LangChainのModels, Prompts, Memory, Chainsがどの部分に該当するのか解説しつつ、補足していきます。
Prompts
Prompt Templates を用いて、以下のようにプロンプトのテンプレートを作成します。テンプレートの中に変数(history や human_input)を埋め込むことができるのが特徴としてあげられます。
これにより、後述する過去の会話もこのテンプレートに沿って記録させていきます。
def create_prompt () -> PromptTemplate:
"""OpenAIの言語モデルに入力するプロンプトを作成する
"""
template = """Assistant is a large language model trained by OpenAI.
必要であればここにプロンプトを追加する
{history}
Human: {human_input}
Assistant:"""
prompt = PromptTemplate(input_variables=["history" , "human_input" ], template=template)
return prompt
Memory
ConversationBufferMemory を用いて、過去の会話を記憶させていきます。
今回は同一スレッドでかつ、同一ユーザとBotの発言のみを記憶させることで、他の人がスレッド内で発言しても、それは文脈から除外するようにしています。
これにより、社内メンバーとのコミュニケーションの隙間に、違和感なくAIを介入させることができます。
このMemoryモジュールは、過去どのくらいの会話までを記憶させるか指定できる ConversationBufferWindowMemory や、過去の会話の要約を作成し、それを文脈としてプロンプトに与えることのできる ConversationSummaryBufferMemory などもあります。
def create_memory (user_id: str , channel: str , thread_ts: str ) -> ConversationBufferMemory:
"""会話のメモリーを作成する
"""
memory = ConversationBufferMemory(human_prefix="Human" , ai_prefix="Assistant" , memory_key="history" )
if thread_ts is not None :
thread_message = app.client.conversations_replies(channel=channel, ts=thread_ts)
for i in thread_message["messages" ]:
if i["user" ] == user_id and SLACK_BOT_ID in i["text" ]:
memory.chat_memory.add_user_message(remove_slack_id_from_text(i["text" ], SLACK_BOT_ID))
elif i["user" ] == SLACK_BOT_ID and user_id in i["text" ]:
memory.chat_memory.add_ai_message(remove_slack_id_from_text(i["text" ], user_id))
return memory
Models & Chains
Chat Models と LLM Chain を用いて、OpenAIの gpt-3.5-turbo モデルと、これまで作成したPromptsとMemoryを連結し実行するように設定しています。
ユーザがslack上で入力した最新のテキストをpredictさせることで一連のChainが実行され、AIの回答を得られる、といった仕組みです。
def send_chat_request (prompt: PromptTemplate, memory: ConversationBufferMemory, input_message: str ) -> str :
"""OpenAIの言語モデルにチャットメッセージを送信しレスポンスを生成する
"""
try :
llm = ChatOpenAI(model_name="gpt-3.5-turbo" )
chatgpt_chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=False ,
memory=memory,
)
return chatgpt_chain.predict(human_input=input_message)
except Exception as e:
return ""
番外編:timeout
OpenAI APIは調子が悪いタイミングも時々あります。
その時にユーザを長い間待たせるのは体験として良くないので、特定の時間が経過したらタイムアウト処理として扱うような処理も入れています。
def call_function_with_timeout (func, timeout_seconds, *args) -> dict :
"""ターゲット関数を別のスレッドで実行し、タイムアウトを適用する
"""
with concurrent.futures.ThreadPoolExecutor() as executor:
future = executor.submit(func, *args)
try :
response = future.result(timeout=timeout_seconds)
return {"result" : response}
except concurrent.futures.TimeoutError :
return {"error" : "Function execution timed out" }
まとめ・所感
今回はLangChainのキャッチアップがてら、社内で利用できるAI Chat Botを開発してみました。
フレームワークに乗っかれば、同じインターフェースでいろいろな機能(今回で言うとMemory部分など)を使うことができるので、まさに「LLMアプリケーションを作成するプロセスを簡易化」してくれるなぁと感じました。
また、弊社のように自社にそこそこ大きなテキストデータがあれば、Indexesモジュールなどを組み合わせることで、独自のAI Chat Botなどを作ることもできそうなので、そういった機能も積極的に検証していきたいと思いました。
We Are Hiring !! コネヒトでは一緒に働く仲間を募集しています!
www.wantedly.com
機械学習に関しては、過去の取り組み事例や今後の展望などを以下にまとめていますので、是非見てみてください!
tech.connehito.com
そして興味持っていただけた方はカジュアルにお話しましょう! 事前準備は不要ですのでお気軽にご連絡ください。