みなさんこんにちは。MLチームのたかぱい(@takapy0210 )です。
ここ1年くらいPokémon UNITE というゲームにハマっていまして、何回か大会にも出場しているのですが、先日出場した大会の「おじさんの部 26歳以上の部」で準優勝することができました🎉
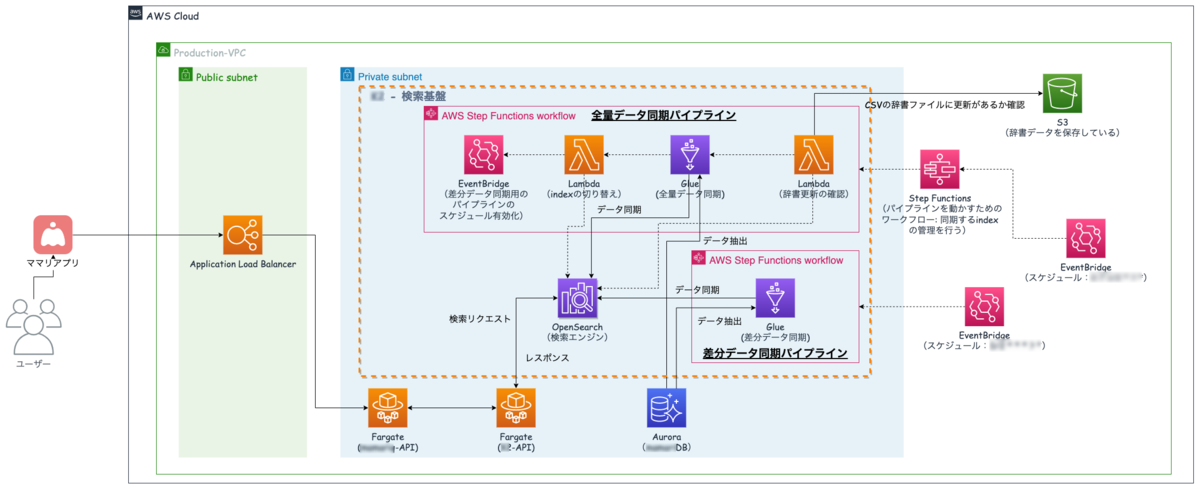
さて本日は、コネヒトの運営するママリのオンボーディング改善に機械学習を活用した事例をお話をしようと思います。
今回実施したオンボーディング改善には大きく分けて以下2つのステップがあります。
ステップ1:興味選択にどのようなトピックを掲示したら良いか?
ステップ2:選択したトピックに関連するアイテムをどのように計算(推薦)するか?
本エントリでは主にステップ1の内容についてお話しできればと思います。(ステップ2に関しては別エントリでお届けする予定です!)
目次
はじめに
世の中にリリースされているサービスの多くは、登録時に何かしらのオンボーディングがあると思います。
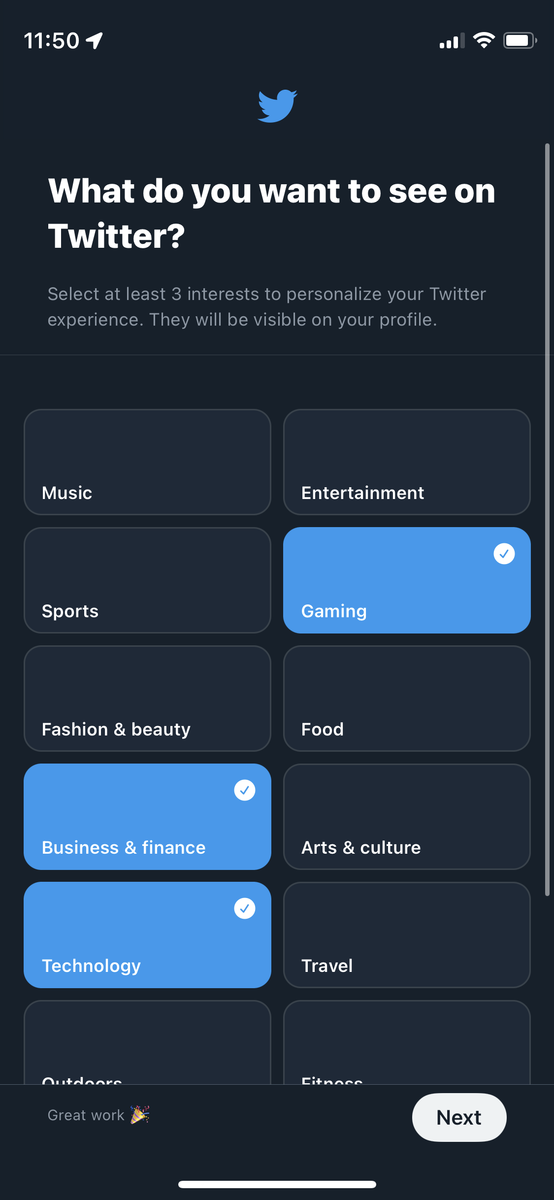
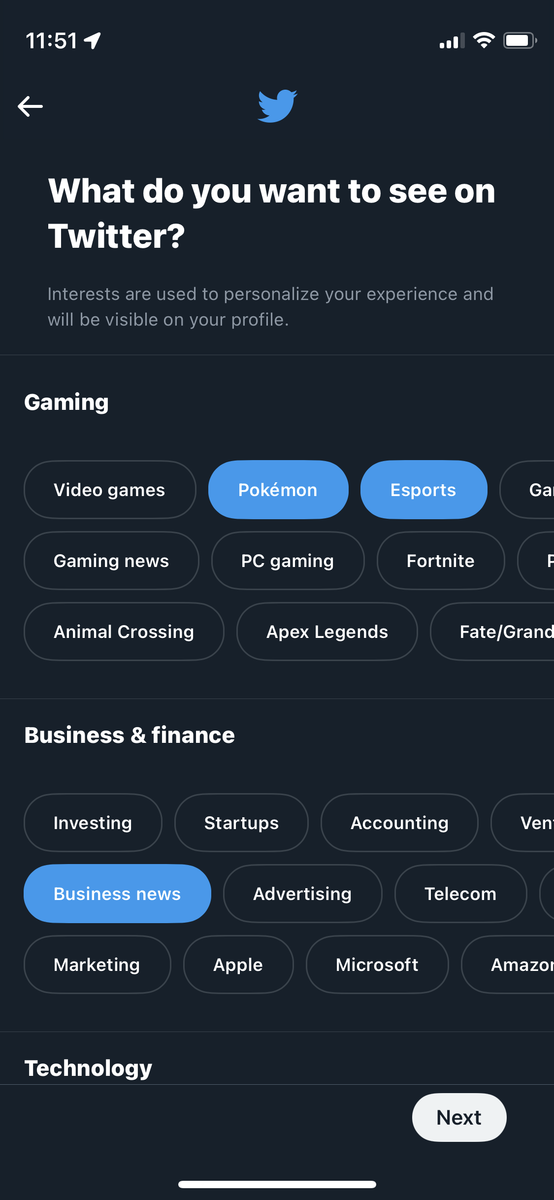
例えばTwitterのオンボーディングでは、以下のように「Twitterで見たいものは何か?」を選ぶフローがあり、ここでユーザーごとに興味関心のあるトピックを選択することで、パーソナライズを実現しようとしています。
このように、サービスを使い始めたばかりのユーザーに対しては、順当にユーザーの興味関心に適合したアイテムを推薦することで、サービスへの信頼性を高める戦略をとることは非常に重要だと考えています。
そこでママリにおいても、オンボーディング時にユーザーの興味関心を教えてもらうことで、新規ユーザーのUX向上に貢献できるのではないか、という仮説のもと、今回のプロジェクトが始まりました。(以降、このプロジェクトのことを”興味選択”と呼びます)
オンボーディング改善に取り組んだ背景
これまでのママリでは、新規ユーザーに対してはお子さんの年齢や妊娠週数別にルールベースでアイテムの推薦を行っていました。
これにはいくつか課題がありますが、中でもユーザーの興味関心を拾えていない部分が大きいと考えていました。
例えば、妊娠初期のユーザーでも、以下のように興味関心は1人1人異なります。
妊娠中、母体に訪れる症状(例:つわりなど)に関心のあるユーザー
仕事関連(例:産休など)に関心のあるユーザー
お金関連(例:出産にかかる費用や保険など)に関心のあるユーザー etc …
上記のような興味関心は今までのルールベースの推薦では考慮できておらず、同じ属性(妊娠初期など)の新規ユーザーには一様なアイテムが推薦されている状態でした。
このような課題を解消するために、オンボーディングに興味選択を組み込むことになりました。
なぜ機械学習を使う必要があったのか
例えば、妊娠初期のユーザーがどのようなアイテムに興味関心があるのか?を知る方法はいくつかあると思います。
一番手軽に知る方法、検索のログを分析することでしょうか。
しかし、検索のログで拾えるものは一般的に、顕在化されている関心であることが多く、潜在的な関心を拾うのは難しいと考えられます。
そこで、検索だけでなくアイテムのクリックログから、それぞれのクラスタごとによく見られているアイテムを抽出し、潜在的なニーズを探るためにトピックモデルを活用しました。
顕在的なニーズは検索ログベースで抽出し、潜在的なニーズは機械学習を使って抽出することで、興味選択で表示するトピックに網羅性を持たせ、さまざまな悩みを持つユーザーに寄り添ったオンボーディングを目指しました。
分析手順
今回はユーザーを複数のクラスタ(妊娠初期や妊娠中期、生後Nヶ月、など)に分割し、それぞれのクラスタが閲覧しているアイテム(=質問)毎にトピックモデルを活用し、各クラスタでどのようなトピックが現れるのかを分析しました。
トピックモデルとは
文書が複数の潜在的なトピックから確率的に生成されると仮定したモデルです。
ここでいう「トピック」とは話の主題のことで、同じ話題について話していても、人によって解釈が変わることもあります。
例えば、トピックの数を3と指定してモデリングした場合、そのモデルに何かしらの文書を渡すと、出力として3つのトピックそれぞれの確率分布が得られます。
こうした「トピックへの意味づけ」や「最適なトピックの数」に関しても、併せて紹介していこうと思います。
トピックモデルのイメージ図
今回はトピックモデルの代表とも言えるLDAを、gensim というライブラリを用いて実装しました。
トピックモデルの概要についてはAlbertさんの記事を見ていただくとよりイメージがしやすいと思います。
www.albert2005.co.jp
gensimを用いたトピックモデリング
モデリングする際は日本語であればトークナイズ済みのデータが必要になります。(以下のようなイメージです)
LDAの学習に使用するデータイメージ
データが用意できれば、LDAの学習は以下のように実装できます
import gensim
import multiprocessing
texts = df['content_token' ]
dic = gensim.corpora.Dictionary(texts)
bow_corpus = [dic.doc2bow(doc) for doc in texts]
lda_model = gensim.models.LdaMulticore(
bow_corpus,
num_topics=18 ,
id2word=dic,
workers=multiprocessing.cpu_count(),
passes=10 ,
random_state=0
)
前述したように学習後のトピックに対する意味(ラベル)づけは人間が行う必要があります。
num_words = 30
topic_list = []
word_list = []
weight_list = []
for n, values in lda_model.show_topics(num_topics=18 , num_words=num_words, formatted=False ):
for word, weight in values:
topic_list.append(n)
word_list.append(word)
weight_list.append(round (float (weight) * 100 , 2 ))
topic_df = pd.DataFrame()
topic_df['topic' ] = topic_list
topic_df['word' ] = word_list
topic_df['weight' ] = weight_list
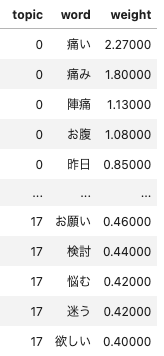
このようなDataFrameを取得することができ、トピックの理解に役立ちます。
取得できるDataFrame
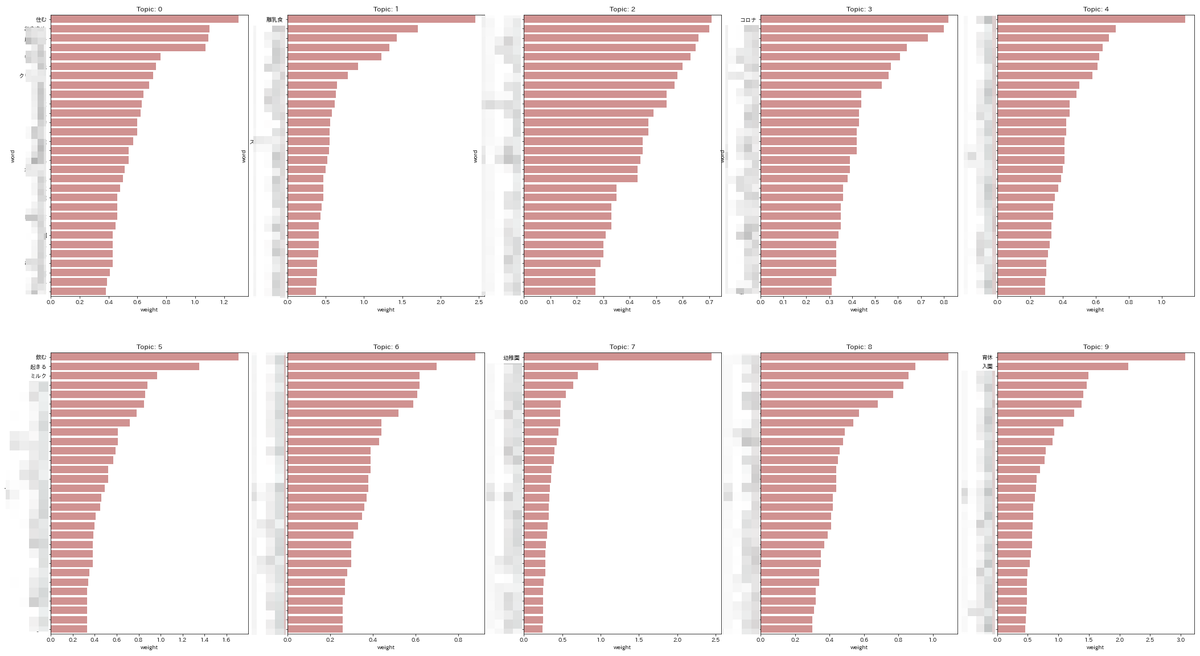
可視化してみると、より分かりやすくなると思います。
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
fig, axes = plt.subplots(2 , 5 , figsize=(36 , 20 ))
topic = 0
for ax in axes.ravel()[0 :]:
sns.barplot(x="weight" , y="word" , data=topic_df.query('topic==@topic' ), color='#da8886' , ax=ax)
ax.set_title(f'Topic: {topic}' )
topic += 1
plt.show()
トピックに紐づく単語(一部)
最適なトピック数を探索する
前述したように、トピックの数は人間が指定しなければなりません。
トピックモデルのトピック数は、一般的にCoherenceとPerplexityの値から最適なトピック数に当たりをつけることができます。
Coherence :トピックが人間にとって分かりやすいかといった品質を表す指標。高い方が良いとされている。
Perplexity:モデルの予測性能を表す指標。低い方が良いとされている。
上の2つの値は、以下のようにして探索することができます。
start = 10
limit = 50
step = 1
coherence_vals = []
perplexity_vals = []
for n_topic in tqdm(range (start, limit, step)):
lda_model = gensim.models.LdaMulticore(bow_corpus,
num_topics=n_topic,
id2word=dic,
workers=multiprocessing.cpu_count(),
passes=10 ,
random_state=0 )
perplexity_vals.append(np.exp2(-lda_model.log_perplexity(bow_corpus)))
coherence_model_lda = gensim.models.CoherenceModel(model=lda_model, texts=texts, dictionary=dic, coherence='c_v' )
coherence_vals.append(coherence_model_lda.get_coherence())
fig, ax1 = plt.subplots(figsize=(15 ,8 ))
x = range (start, limit, step)
ax1.plot(x, coherence_vals, 'o-' , color=c1)
ax1.set_xlabel('Num Topics' )
ax1.set_ylabel('Coherence' , color='darkturquoise' ); ax1.tick_params('y' , colors='darkturquoise' )
ax2 = ax1.twinx()
ax2.plot(x, perplexity_vals, 'o-' , color=c2)
ax2.set_ylabel('Perplexity' , color='slategray' ); ax2.tick_params('y' , colors='slategray' )
ax1.set_xticks(x)
fig.tight_layout()
plt.show()
coherenceとperplexityのプロット
上記の例だと26あたりのトピック数が良さそうだ、という判断をすることができます。
プロダクトへの活用
上記で分析した結果などを参考に、PdMと議論しながら最終的にユーザーに表示するトピックを選定していきました。
2022年09月時点では以下のようなトピックがオンボーディングで表示されています(※ユーザーの属性情報によって表示されるトピックは異なります)
オンボーディング時のスクリーンショット
最後に
今回はユーザーをクラスタ別で分析したときに、どのようなコンテンツの興味があるのか?を分析することで、オンボーディングを改善した事例をご紹介しました。
冒頭で述べた通り、続編として「選択したトピックに関連するアイテムをどのように計算(推薦)するか?」の内容についても、後日紹介できればと思います。
オンボーディング改善の内容は、PyCon 2022でも詳細をお話する予定なので、興味がある方は是非観にきてください! (登壇日時は10月14日(金)の17時10分〜17時40分に決まりました!)
2022.pycon.jp
We Are Hiring !! コネヒトでは一緒に働く仲間を募集しています!
www.wantedly.com
機械学習に関しては、過去の取り組み事例などを以下にまとめていますので、是非見てみてください!
tech.connehito.com
そして興味持っていただけた方はカジュアルにお話しましょう! (TwitterのDMでもMeety経由でも、気軽にご連絡ください)
参考文献