こんにちは。サーバーサイドエンジニアの TOC です。
本日はコネヒト株式会社で取り組んでいる Super X という活動の一環である「デプロイフロー改善」の取り組みを紹介しようと思います。
本記事で紹介した改善以外にも、デプロイフロー改善チームで取り組んだことは別エントリでお届けする予定です✨
目次
はじめに
そもそも Super X って何?と思われるかと思うので、取り組みのご紹介をしようと思います!
Super X はエンジニア組織として追っている目標のプロジェクト名で、開発組織の中で課題となってる負債の解消などに取り組んでいく活動です!
今回私は 「デプロイフロー改善」を上期のテーマとして選び、活動を行ってまいりました。
抱えていたデプロイフローでの課題
※以下、「開発環境」は一般的に言うステージング環境を指しています。
弊社では過去に ecs-deploy を用いたデプロイを ecspresso に変更する取り組みがありました。(ref. GitHub Actions & ecspressoによるデプロイフロー構築)
上記取り組みで ecspresso 導入がされたものの、以下の課題が残っていました。
- 開発環境と本番環境で別々の Docker イメージが利用されている
- ロールバックの方法が確立してない
1.については開発環境で検証した Docker イメージを本番環境でも利用した方が安心であるのと、本番環境デプロイ時に再ビルドが発生するので余計な時間がかかっているのを解消したいと思っていました。
2.については、ecspresso を使えば簡単にロールバックできるものの、その運用方法が社内で確立していなかったので、この際に他リポジトリに展開できるまで運用方法を確立しようという話になりました。
各課題の解決方法
開発環境で検証した Docker イメージを本番環境のデプロイで利用する
前提として、ecspresso を用いたデプロイフローはざっくり下記のようになっております。
1. 最新コードのチェックアウト 2. イメージをビルドし、ECR へプッシュ 3. ecspresso を利用して ECS タスク定義の更新・デプロイ
今回の改善では開発環境で上記のデプロイフローを行い、本番環境では下記のデプロイフローを行うことを目指します。
1. 最新コードのチェックアウト 2. ecspresso を利用して、開発環境で作成したイメージを参照するように ECS タスク定義の更新・デプロイ
このとき Docker イメージにつけるタグ名としては以下を満たす必要があると考えました。
- 開発環境デプロイ時に利用できるものであること
- タグ名が
:latestなどに固定されないこと(ecspresso のロールバックを考慮する)
上記2点を考慮すると、コミットハッシュをタグにするのがいいのではないか、という話になりました。
コミットハッシュならば、Github Actions 内で github.sha で取得ができます。
取得したコミットハッシュをイメージのタグ名として、イメージのビルド・ECR へのプッシュを行い、ecspresso でそのイメージを利用する形にすれば、開発環境で検証したイメージを本番環境デプロイ時に流用できる設計となりました。
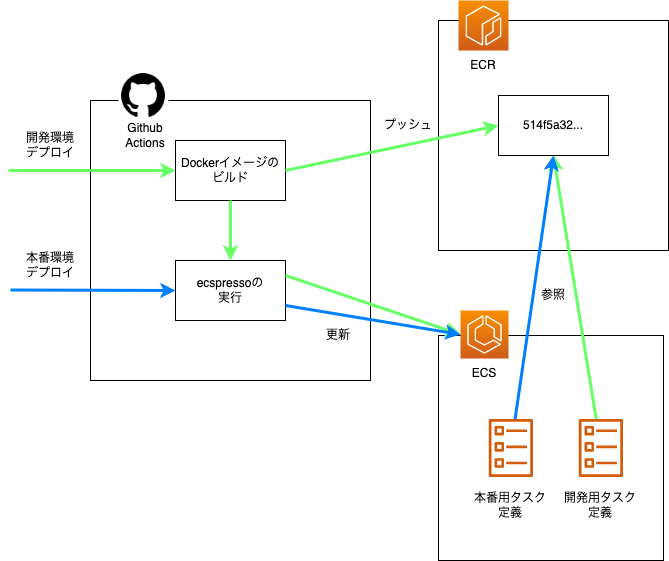
これにより、本番デプロイの actions は以下のようになり、だいぶシンプルになりました(一部抜粋)。
on: push: tags: - '*' env: AWS_ROLE_ARN: hogehoge permissions: id-token: write contents: read actions: read jobs: deploy: runs-on: ubuntu-latest steps: # 通知など前処理 - name: Checkout uses: actions/checkout@v2 - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v1 with: role-to-assume: ${{ env.AWS_ROLE_ARN }} aws-region: aws-region - name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - uses: kayac/ecspresso@v1 with: version: latest - name: Deploy to Amazon ECS env: IMAGE_TAG: ${{ github.sha }} run: | ecspresso deploy --config .ecspresso/production/config.yaml # 後続処理
ロールバック方法の確立
デプロイが完了し、タスクは正常に起動したもののアプリケーションの動作に問題が発生したので戻したい場合には、ecspresso rollback コマンドを使用します。
ドキュメントによると、ロールバックをすると下記動作が走ります。
- 現在サービスに設定されているタスク定義の「ひとつ前」のリビジョンを見つける
- ひとつ前のリビジョンのタスク定義をサービスに設定する
ref. ecspresso advent calendar 2020 day 6 - rollback
なので理論上、有効なリビジョンのタスク定義がある場合は無限にロールバック可能です。
このとき、--deregister-task-definition オプションをつけるとロールバックを行ったタスク定義を登録解除 します。
つまり、1回異常が起きたタスク定義はもう使わない、という思想のようで、ecspresso 作者の方も特別な事情がない場合はこのオプションをつけることをおすすめしています。
このオプションをつけることで、無限に戻れはするが、戻った際に過去ロールバックをした定義は使われない状態が作れます。 なのでロールバック時はオプションを指定したコマンドを実行するように修正しました。
ecspresso rollback --deregister-task-definition --config .ecspresso/production/config.yaml
ちなみに ecspresso Roadmap to v2 を見ると、このオプションがデフォルトで true になるようなので、いずれオプション指定しなくても良くなりそうですね🙌
その他工夫した点
デプロイジョブの並列化
場合によっては複数の ECS 環境にデプロイを行いたい場合があるかもしれません。その際にジョブを直列で書くと、1つの環境でデプロイが終わらないと次のデプロイが始まりません。
そんな時はジョブを並列化するとデプロイ時間が短縮されます。
deploy_1: needs: build runs-on: ubuntu-latest steps: # デプロイ deploy_2: needs: build runs-on: ubuntu-latest steps: # デプロイ deploy_3: needs: build runs-on: ubuntu-latest steps: # デプロイ
上記のように needs: build でビルド作業が終わったら各ジョブが走るようにします。
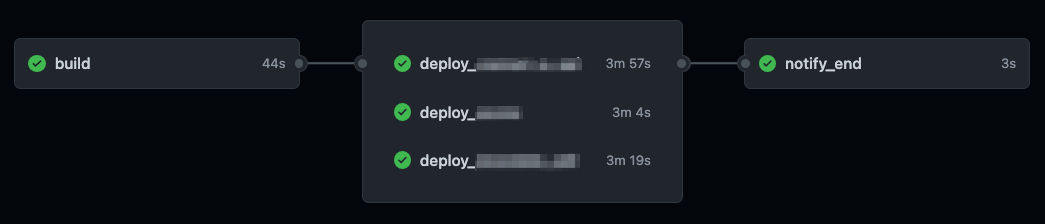
actions の詳細を見ても上図のように並列実行できていることがわかります。
並列化したジョブの結果を取得する workflow-conclusion-action の利用
デプロイをする actions では最後にデプロイ結果を通知するジョブを用意しています。デプロイのジョブを並列化した場合、どれか1つでもジョブが失敗したら通知としては失敗と通知してほしい気持ちになります。
通常ジョブの成功/失敗は job.status で取得できますが、これは1つのジョブの成否になるので、ジョブが分かれた場合、前段のジョブが成功したのか、失敗したのかはわかりません。
そんな時は workflow-conclusion-action が便利です。
notify_end: needs: [ deploy_1, deploy_2, deploy_3 ] runs-on: ubuntu-latest if: always() steps: - uses: technote-space/workflow-conclusion-action@v2 - name: Notify slack of deployment result uses: 8398a7/action-slack@v3 with: status: ${{ env.WORKFLOW_CONCLUSION }} fields: repo,commit,ref,workflow,message author_name: ${{ github.actor }} text: | Deployment has ${{ (env.WORKFLOW_CONCLUSION == 'success' && 'succeeded') || (env.WORKFLOW_CONCLUSION == 'failure' && 'failed') || 'cancelled' }} to hogehoge. env: SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
このように各デプロイ全て終わった後に実行し、結果を env.WORKFLOW_CONCLUSION で取得すると、どれか一つでもデプロイが失敗した場合は失敗の通知をしてくれます。
まとめ
今回は ecspresso を用いたデプロイの更なる改善方法をご紹介しました。
仕組みが整っていると、普段あまり意識しなくても流れに乗ってしまえばできてしまうデプロイですが、これを機に CI 周りの理解だけでなく、ECR、ECS などインフラ側の理解も進んだので、非常に良い機会でした。
今回ご紹介した方法が、日頃の開発の何か参考になれば幸いです。
PR
コネヒト株式会社では絶賛エンジニア募集しております!
今回のような活動に興味を持った方、ぜひ一度お話させてもらえるとうれしいです。