こんにちは。インフラエンジニアの永井(shnagai)です。
今回は、ターゲット追跡ServiceAutoScallingを使い、ECS×fargateで運用しているサービスのスパイク対策と費用削減に取り組んだのでその内容をまとめています。
内容はざっくり下記4項目について書いています。
- 抱えていた課題
- キャパシティプランニングに対する考え方
- ECS ターゲット追跡ServiceAutoScallingとは何か?
- どんな結果になったか?
抱えていた課題
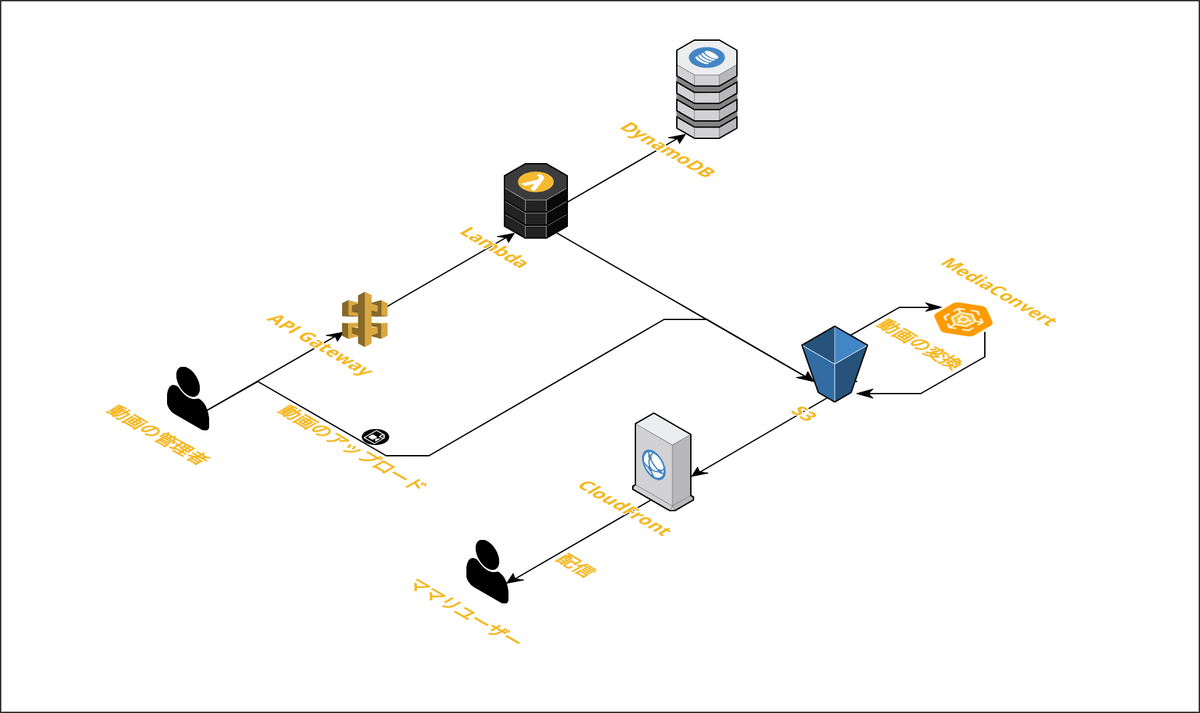
コネヒトでのWebのアーキテクチャはほとんどがECS×Fargateの基盤で動かしています。 ECSのバックエンドをEC2からFargateに移行したタイミングで、大きく下記2点のメリットは享受していました。
- EC2を意識しないことでの運用コスト削減
- オートスケールの容易さ
ですが、サービス運用にあたりまだ下記のような課題がありました。
- ①FargateのコストがEC2リザーブドインスタンスに比べて費用が高い
- ②オートスケールは容易になったが、平均50sくらい起動にバッファが必要なので、瞬間的なスパイクに対する瞬発力が弱い
今回この2つの課題に対して、ターゲット追跡ServiceAutoScallingを本格導入することで解決することに成功したのでどのようなアプローチをしていったかについて紹介します。
キャパシティプランニングに対する考え方の変化
アプリケーションの実行環境としてクラウド利用やコンテナ化が進んできたことで、スケールアウトやスケールアップが容易になったことを背景として、昔のようなピークトラフィックに耐えうるキャパシティを事前に用意しておくようなアーキテクチャは、私達のような小・中規模のウェブサービスでは選択しなくてもよい時代になりました。
もちろんサービスの可用性を高く保つのはインフラエンジニアとしての本分なのでそこは保ちつつ、クラウドは従量課金なので、ユーザが多いときには多くのリソースを構え少なくなったらリソースを最小化するというより動的なキャパシティコントロールをすることがそのまま費用削減につながります。同じ品質のサービスを提供するのであれば費用は少ない方がいいに決まっており、費用削減もサービス運用に大きな意味を持つと思っています。
コネヒトの最近の話を少し振り返ると、下記のような流れをたどっています。
| アーキテクチャ | ポイント | 費用 |
|---|---|---|
| ECS×EC2時代 | EC2バックエンド時はオートスケールが複雑だったので採用せずにピークトラフィックに*数倍に耐えうるEC2を用意 | ReservedInstanceを利用し費用は圧縮 |
| ECS×Fargate時代 | EC2(RI)と比べると費用が高いので、ピークトラフィックに耐えうるタスク数までFargateの必要数をチューニングして減らす+想定外のスパイクはオートスケール利用(ちょっと遅いという課題感あり) | SavingsPlansを利用し30%弱の費用を圧縮するが、タスク数減らしてEC2時代と同じくらいの費用感 |
| ECS×Fargate(ターゲット追跡ServiceAutoScalling)時代 | 負荷に応じてタスク数を動的にコントロール。最小数を小さくして夜間とピーク時で3倍程のタスク数の差が出る。平均的なタスク数の削減に成功 | 従量課金を生かして2のパターンと比べて25%程の費用削減に成功 |
ECS ターゲット追跡ServiceAutoScallingとは何か?
ここからは、今回活用したターゲット追跡ServiceAutoScallingについて紹介します。
簡単に説明すると、CPU使用率/メモリ使用率/リクエスト数の3つから追跡するメトリクスと値を選択することで、ECS側でタスク必要数 (起動するコンテナ数)を動的にコントロールしてくれる機能です。
実はこれまでもスパイク時のオートスケール用には使っていたのですが、今回スケールインもこの機能に任せる設定を入れて、負荷が低い状態の時に費用削減するようなアプローチを取りました。
具体的にどのような動きをするか
現在は、ECSサービスの平均CPU使用率 を使っているのですがこの挙動が少し理解出来なかったので検証時に調べてみました。
端的に言うと、指定した値に収束するようにタスク数をコントロールするような挙動になります。 例えば、CPU 40%という値を設定したとすると具体的に下記のような挙動になります。(これが中々わかりにくかった)
- 平常時に10タスク起動で、CPU40%
- リクエスト数が増え負荷が上がり、CPU55%に
- タスク数が10→13にスケールアウトしCPU40%に収束
- 深夜になり、リクエスト数が減りCPU20%に
- タスク数が13→5にスケールインしCPU40%に収束
裏側では、CloudWatchAlarmがセットされて下記のような設定がされていました。(このアラームの設定は変更負荷)
- 【スケールアウト判定】 3分間連続しきい値違反
- 【スケールイン判定】15分間連続しきい値-3%に収束
設定のポイント
ここから設定のポイントを書いていきます。
スケールの数を設定
サービス内のタスクのスケールイン/アウトの幅をまず設定します。
| 項目 | 内容 |
|---|---|
| Minimum number of tasks (タスクの最小数) | スケールインの最小値なのでこの数以下にはタスク数は減らない |
| タスクの必要数 | サービスで設定しているタスクの必要数が入ります |
| Maximum number of tasks (タスクの最大数) | スケールアウトの最大値なのでこの数以上にはタスク数は増えない |
ターゲット追跡するメトリクスを指定
スケーリングポリシーには、「ターゲット追跡」と「ステップスケーリング(任意のCWAを指定)」があり、今回は「ターゲット追跡」を使う場合の設定について書きます。
ターゲット追跡の対象と出来るのは下記3つです。
ECSサービスの平均CPU使用率
ECSサービスの平均メモリ使用率
ECSサービスに紐づくALBのリクエスト数
また、スケーリングの設定として
| 項目 | 内容 | ポイント |
|---|---|---|
| ターゲット値 | 追跡したメトリクスでのしきい値 | サービスの性質により検証しながら適切な閾値を入れる |
| スケールアウトクールダウン期間 | スケールアウトした後の待機時間(この間は連続でスケールアウトは発動しない) | コネヒトでは60sにしています |
| スケールインクールダウン期間 | スケールインした後の待機時間(この間は連続でスケールインは発動しない) | コネヒトでは900sにしています(ゆっくり縮退してほしいので) |
| スケールインの無効化 | On/Offでスケールインを行うかどうか | 今回の目的だとOff |
どんな結果になったか?
最後にこのターゲット追跡ServiceAutoScallingを導入してどのような結果が出たかを紹介します。
①FargateのコストがEC2リザーブドインスタンスに比べて費用が高いという課題に対しては、1日平均のタスク起動数が25%程削減出来ました!!
従量課金なので、Fargateの利用料金が25%削減しています。

②オートスケールは容易になったが、平均50sくらい起動にバッファが必要なので、瞬間的なスパイクに対する瞬発力が弱いという課題に対しても解決策を見つけることが出来ました。
どうゆうことかというと、ターゲット追跡のしきい値を緩めたことでリソースに余裕のある状態でスケールアウトが走るので、例えばpush通知で急激にリクエストスパイクする際もレイテンシ悪化なくスケールアウト出来るようになりました。
これまでは、CPU60%超えで発動というような強めの設定をしていたので、スケールアウトする際にはすでにリソースがかつかつで既存のタスクが死んでいくというような状況だったので、スケールアウトで収束するまでに時間が少しかかっていたということに改めて気づきました。
実は、スケールアウト時に間に合わずレスポンスタイム悪化すると使えないなと思っていたのですが、レイテンシに全く影響のでない抑えめのしきい値の最適値を見つけ、現在はこのような波形で動的にタスク数が制御されています。(設定後一度もアラートは鳴ってません)
ちなみに、導入時は、ピーク時間帯が毎日不安で、最適なタスク数と追跡するしきい値1週間は張り付いてリソース状況を観察していました。

最後に宣伝です! コネヒトでは一緒に成長中のサービスを支えるために働く仲間を探しています。 少しでも興味もたれた方は、是非気軽にオンラインでカジュアルにお話出来るとうれしいです。
人の生活になくてはならないサービスをつくる、インフラエンジニア募集! - コネヒト株式会社のインフラエンジニアの求人 - Wantedly www.wantedly.com